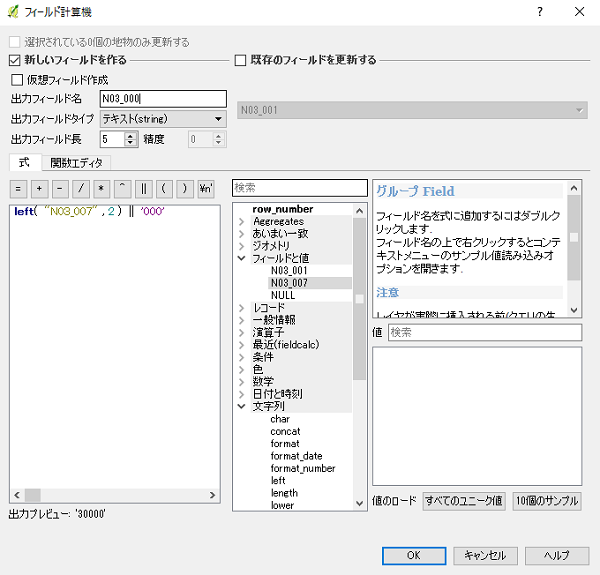
エイリアスの縛り
以下のようなテーブルを考える。
|
|
mysql> SELECT * FROM test; +-------+------+--------+ | name | age | nation | +-------+------+--------+ | John | 35 | US | | Alex | 40 | NZ | | Luice | 29 | US | | Alice | 23 | UK | | Sala | 25 | JP | +-------+------+--------+ 5 rows in set (0.00 sec) mysql> |
ここでnation=’US’のレコードのみ抽出するのに、WHERE句のフィールド名に敢えてテーブル名を付ける。
|
|
mysql> SELECT name, nation FROM test WHERE test.nation='US'; +-------+--------+ | name | nation | +-------+--------+ | John | US | | Luice | US | +-------+--------+ 2 rows in set (0.00 sec) mysql> |
ここでFROM句でテーブルのエイリアスを指定し、WHERE句とSELECT句ではフルネームのテーブル名を使うとエラーが発生。
|
|
mysql> SELECT name, nation FROM test t WHERE test.nation='US'; ERROR 1054 (42S22): Unknown column 'test.nation' in 'where clause' mysql> |
そこでWHERE句のテーブル名をエイリアスに変えると、正常に動作。
|
|
mysql> SELECT name, nation FROM test t WHERE t.nation='US'; +-------+--------+ | name | nation | +-------+--------+ | John | US | | Luice | US | +-------+--------+ 2 rows in set (0.00 sec) mysql> |
さらにSELECT句のフィールド名もフルネームのテーブル名を付けるとエラーになって・・・
|
|
mysql> SELECT test.name, test.nation FROM test t WHERE t.nation='US'; ERROR 1054 (42S22): Unknown column 'test.name' in 'field list' mysql> |
ここもエイリアスにすると正常に動作する。
|
|
mysql> SELECT t.name, t.nation FROM test t WHERE t.nation='US'; +-------+--------+ | name | nation | +-------+--------+ | John | US | | Luice | US | +-------+--------+ 2 rows in set (0.00 sec) mysql> |
これらから、以下のことが分かる。
- FROM句でテーブル名に別名を付けると、元のテーブル名はオーバーライドされて使えなくなる
- FROM句で付けたエイリアスは、WHERE句、SELECT句に波及する。
この意味で、エイリアス、別名という呼び方よりは、「テーブル名のオーバーライド」くらいがいいのではないかと思った。
INNER JOINでのエイリアスの使い方
次のような小売側・問屋側の2つのテーブルを準備。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
mysql> select * from shop; +--------------+-----------+ | product | num_order | +--------------+-----------+ | きゅうり | 20 | | リンゴ | 35 | | 大根 | 20 | | バナナ | 30 | | みかん | 50 | | 玉ねぎ | 25 | +--------------+-----------+ 6 rows in set (0.11 sec) mysql> select * from wholesale; +-----------+-------+ | product | price | +-----------+-------+ | リンゴ | 150 | | バナナ | 300 | | みかん | 200 | | ぶどう | 500 | | いちご | 250 | +-----------+-------+ 5 rows in set (0.00 sec) mysql> |
この2つのテーブルを結合して、果物の取引のみを抽出する。
|
|
mysql> SELECT shop.product, num_order, price -> FROM shop, wholesale -> WHERE shop.product = wholesale.product; +-----------+-----------+-------+ | product | num_order | price | +-----------+-----------+-------+ | リンゴ | 35 | 150 | | バナナ | 30 | 300 | | みかん | 50 | 200 | +-----------+-----------+-------+ 3 rows in set (0.01 sec) mysql> |
まずwholesaleテーブルのエイリアスを定義するのに、WHERE句のテーブル名もエイリアスに変更して
|
|
mysql> SELECT shop.product, num_order, price -> FROM shop, wholesale w -> WHERE shop.product = w.product; +-----------+-----------+-------+ | product | num_order | price | +-----------+-----------+-------+ | リンゴ | 35 | 150 | | バナナ | 30 | 300 | | みかん | 50 | 200 | +-----------+-----------+-------+ 3 rows in set (0.00 sec) mysql> |
またshopテーブルのエイリアスを定義するなら、SELECT句で使われているテーブル名まで全て変更しなければならない。
|
|
mysql> SELECT s.product, num_order, price -> FROM shop s, wholesale w -> WHERE s.product = w.product; +-----------+-----------+-------+ | product | num_order | price | +-----------+-----------+-------+ | リンゴ | 35 | 150 | | バナナ | 30 | 300 | | みかん | 50 | 200 | +-----------+-----------+-------+ 3 rows in set (0.00 sec) mysql> |