概要
国土地理院により、ラスタータイプのタイル地図が「地理院タイル」として提供されている。その仕様についてまとめてみた。
地理院タイルの考え方
地理院タイルは、地球全体をメルカトル投影により正方形化し、それがズームレベルに従って辺長1/2のエリアに分割されていく。
- 経緯度表現の全球をメルカトル投影により変換
- 投影後の形が正方形になるよう南北を制限
- 投影後正方形の地球全図をズームレベル0とする
- その後順次、同じ範囲に辺長を1/2の正方形が収まるよう分割
具体のタイル
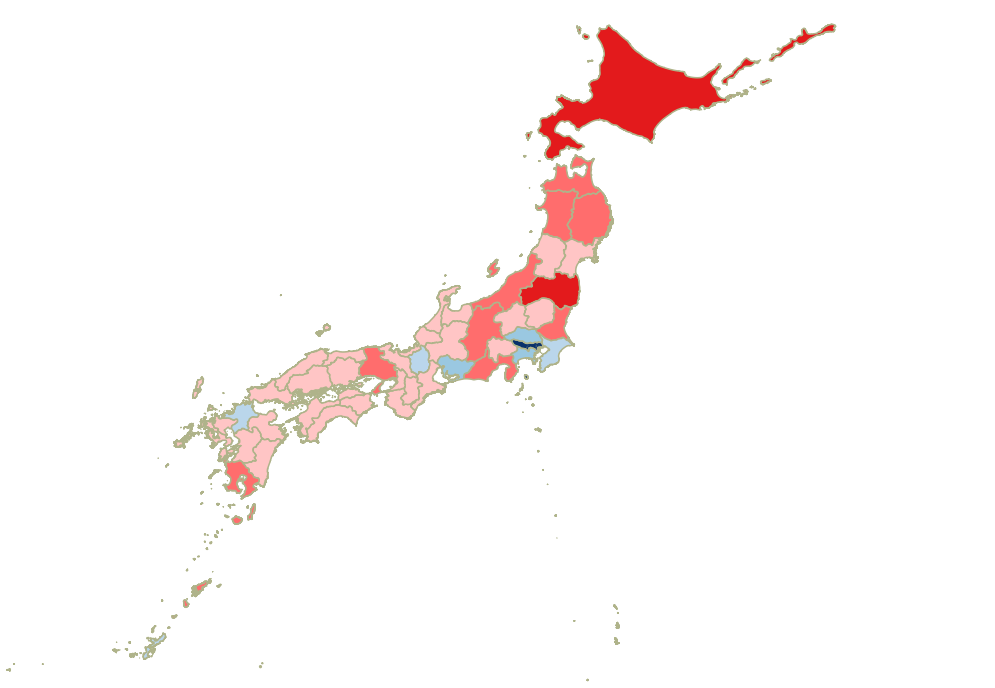
具体の地理院タイルとタイル座標はタイル座標確認ページで確認できる。最小ズームレベル2で表示すると以下のように横長く表示されるが、正方形の世界全図が経度方向に繰り返されているのがわかる。
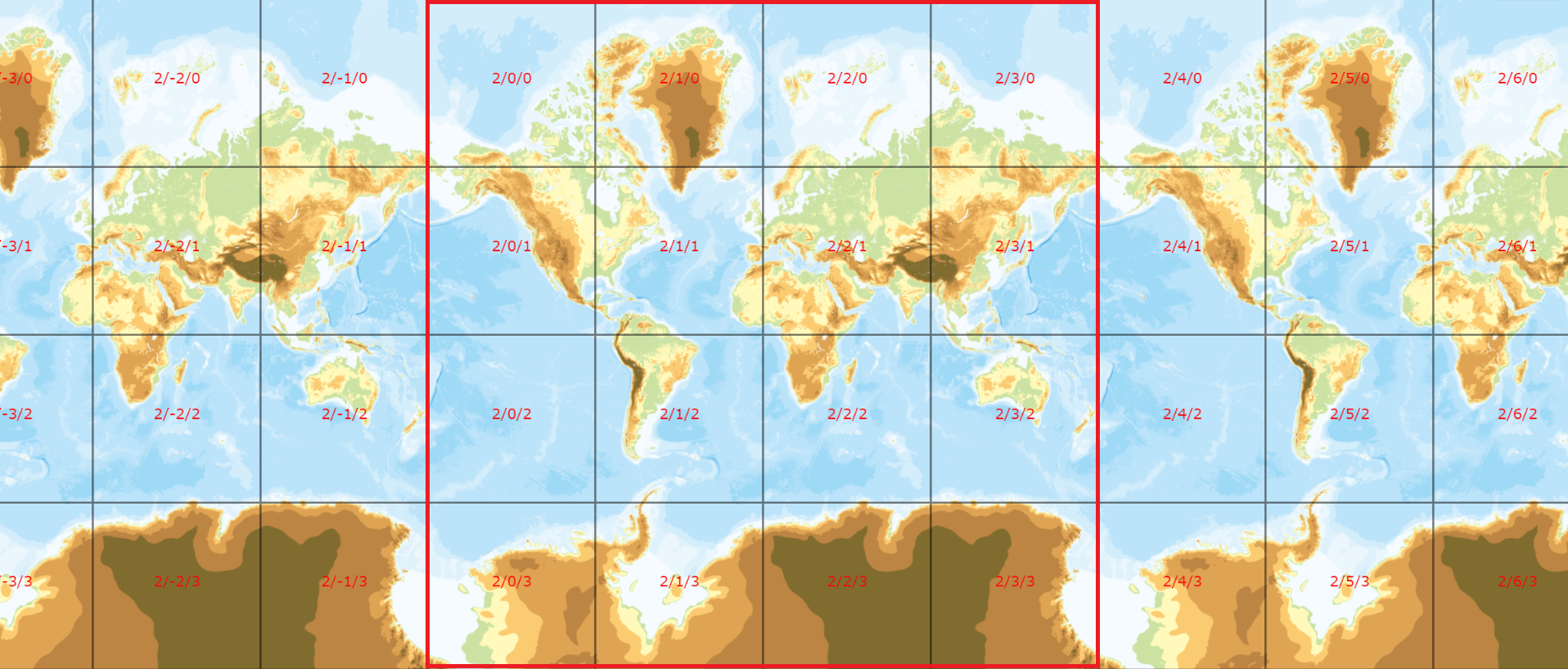
たとえば2/1/3のタイルの場合、ズームレベルが2、タイルのx座標、y座標がそれぞれ1、3ということになる。
ズームイン
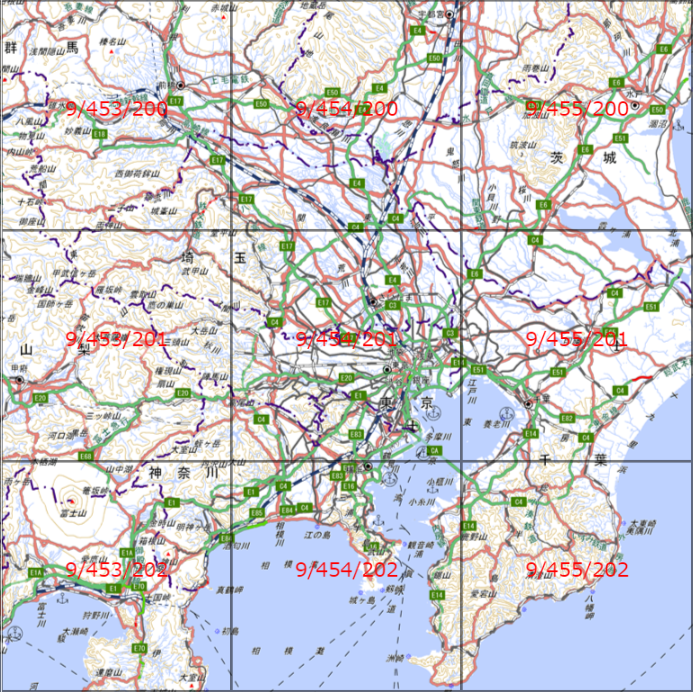
ズームレベルを日本付近で上げていくと詳細な地図に変化していく。以下は首都圏付近のズームレベル9のタイル。首都圏中心部のタイルは454/201となっている。
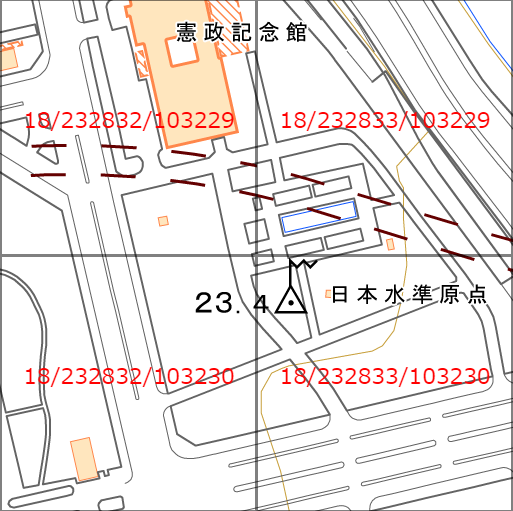
最大ズームレベル18のタイルまで準備されている。以下は日本水準原点付近のタイルの例。
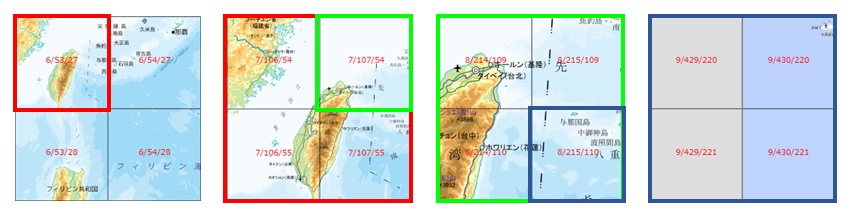
日本付近ではズームレベル18まで準備されているが、それ以外の地域で準備されているタイルはズームレベル8まで。以下は与那国島~台湾付近を順次拡大していった様子。
タイル座標
たとえばズームレベル2の場合、タイル座標は0/0~3/3、縦4×横4の16タイルで構成されている。ズームレベルが3になると、タイル座標は0/0~7/7、縦8×横8の64タイルで構成されている。
つまり、ズームレベルがzのとき、タイル座標は0~2z、タイルの枚数は2z×2z=22z枚ということになる。
タイルの取得
以下のURLを指定して、地理院サイトからタイル画像を取得することができる。
|
1 |
https://cyberjapandata.gsi.go.jp/xyz/{t}/{z}/{x}/{y}.{ext} |
{t}は「データID」で、標準地図ならstd、単色地図ならpaleなどのコードが与えられている。{z}はズームレベル、{x}と{y}はタイル座標値、{ext}は拡張子で、たとえば標準地図や単色地図ならpng。
タイルピクセル
タイルサイズは、ズームレベルに関わらず256ピクセル×256ピクセルとなっている。
たとえばズームレベル2の場合は縦横256×4=1024ピクセルで構成され、ズームレベルが3になると縦横256×8=2048ピクセルでズームレベル2の時の倍のピクセル数となる。
一般にズームレベルzのとき、全球地図の縦・横のタイルピクセル数は256×2zとなり、ズームレベルが1つ上がるごとに倍になっていく。
タイル座標とタイルピクセル位置の関係
タイル座標とタイルピクセル位置の関係は、int(タイルピクセル位置/256)となる。そしてタイルピクセル位置からタイル座標値の256倍を引いた値(タイルピクセル位置を256で割った剰余)は、そのタイルピクセルを含むタイル内でのピクセルのオフセット位置になる。
たとえばズームレベル2の場合、(896, 448)のピクセルが属するタイルは3/1となり、このタイル内でのピクセルのオフセットは(128, 192)となる。