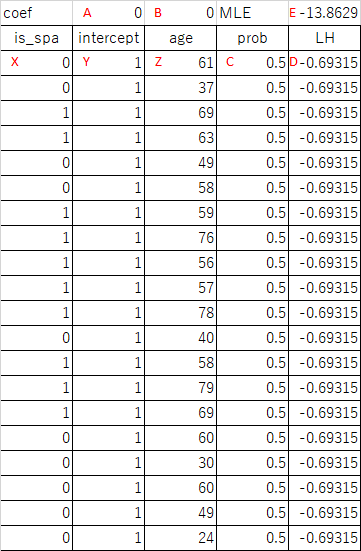
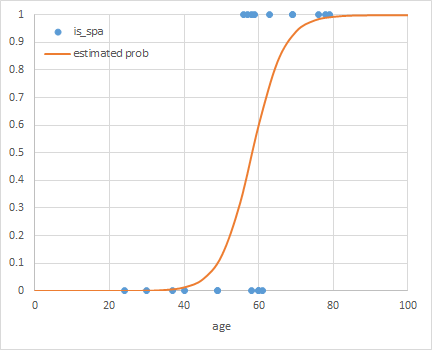
概要
適用対象となる問題
ロジスティック回帰(Logistic regression)は「回帰」という名称だが、その機能は2クラス分類である。複数の特徴量に対して、2つのクラス1/0の何れになるかを判定する。
たとえば旅行会社の会員顧客20人の年齢と、温泉(SPA)とレジャーランド(LSR)のどちらを選んだかというデータが以下のように得られているとき、新たな顧客にどちらを勧めればよいか、といったような問題。
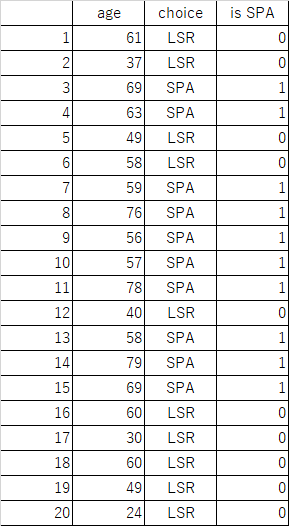
上のデータの”is SPA”列は、温泉を選んだ場合に1、レジャーランドを選んだ場合に0としている。これを散布図にすると以下の通り。
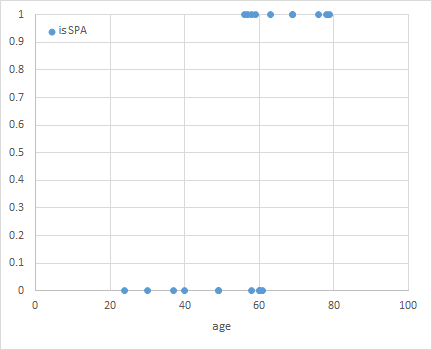
年齢が高いほど温泉を選ぶ傾向があるのは分かるが、「年齢が与えられたときに温泉とレジャーランドのどちらを選ぶか」というモデルを導出するのが目的。
(1) 
モデルを線形モデルとし、特徴量の線形和の値によってクラス1/0の何れになるかが決まるとすると
(2) 
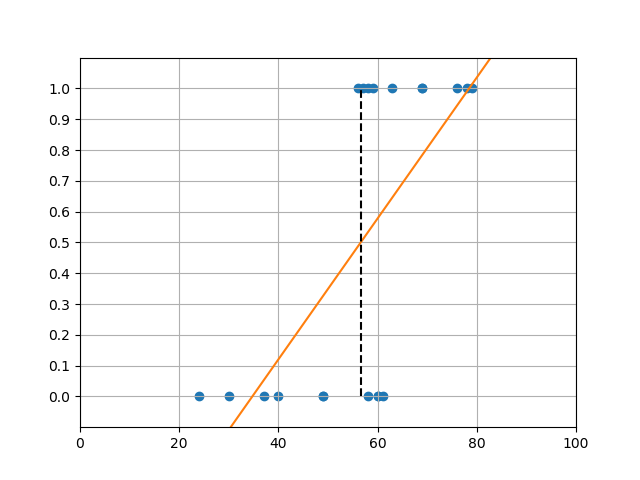
線形回帰による場合
ここでそのままデータに対して線形回帰を適用して、たとえば回帰式の値0.5に対する年齢を境にして温泉とレジャーランドを判定してもよさそうに見える。ただ、この時の回帰式がデータに対してどのような意味を持つのかが定かではない。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import os import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression path = os.path.join(os.path.dirname(__file__), "data_spa.csv") df = pd.read_csv(path) X = np.array(df['age']).reshape(-1, 1) y = df['is_spa'] linreg = LinearRegression() linreg.fit(X, y) b = linreg.intercept_ w = linreg.coef_[0] x_border = (0.5 - b) / w print(x_border) xl = 0 xr = 100 yl = b + w * xl yr = b + w * xr fig, ax = plt.subplots() ax.scatter(X, y, c='tab:blue') ax.plot([xl, xr], [yl, yr], c='tab:orange') ax.plot([x_border, x_border], [0, 1], c='k', linestyle='dashed') ax.set_xlim(xl, xr) ax.set_ylim(-0.1, 1.1) ax.set_yticks(np.linspace(0, 1, 11)) ax.grid(True) plt.show() |
確率分布の仮定
単純な線形回帰ではなく、特徴量の線形和に対してクラス1となる確率分布を考える。
(3) 
このときの確率分布の関数形として以下が必要となる。
- xの(−∞, +∞)の範囲に対して、値が(0, 1)となる
- xが小さい→確率が0に近くなる→クラス0と判別されやすくなる
- xが大きい→確率が1に近くなる→クラス1と判別されやすくなる
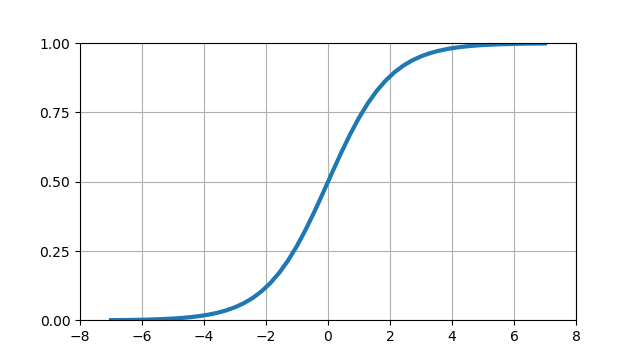
これをグラフにすると、以下のような形になる。
このような関数の回帰によるクラス分類は、確率分布に用いる関数形からLogistic回帰と呼ばれている。
Logistic回帰の定式化
確率分布関数の仮定
説明変数が であり、それに対してある事象が発生する/発生しないの2通りがあるとする。
であり、それに対してある事象が発生する/発生しないの2通りがあるとする。
いま、 の観察対象について
の観察対象について のデータが観測されたとする。このとき、以下のように定式化する。
のデータが観測されたとする。このとき、以下のように定式化する。
(4) 
 が得られたとき、その多項式を使った確率によって事象が発生することを意味している。この確率分布の式はLogistic関数と呼ばれる。
が得られたとき、その多項式を使った確率によって事象が発生することを意味している。この確率分布の式はLogistic関数と呼ばれる。
ロジスティック関数(logistic function)はシグモイド関数(sigmoid function)とも呼ばれ、その値は(0, 1)の間にあることから確率分布として採用している。
(5) 
なお、ロジスティック関数の逆関数はロジット関数(logit function)と呼ばれる。
(6) 
ここでLogit関数の対数の中はオッズの形になっている。
最尤推定
 のm×n個の説明変数データと、
のm×n個の説明変数データと、 のターゲットデータが得られたとする。
のターゲットデータが得られたとする。
このとき、ターゲットデータが得られたパターンとなる確率は、それぞれが独立事象であるとすれば確率の積になるから、
(7) 
この確率は、パラメーター に対する尤度関数であり、その対数尤度関数は以下のようになる。
に対する尤度関数であり、その対数尤度関数は以下のようになる。
(8) 
ここで、
(9) 
これを使って、対数尤度関数は以下のように変形される。
(10) 
得られたデータに対してこの対数尤度を最大とするような を求めるのには、通常数値計算が用いられる。
を求めるのには、通常数値計算が用いられる。
1変数の場合
定式化
線形表現は以下のようになる。
(11) 
ロジスティック関数による確率表現は
(12) 
nこのデータセット が与えられたとき、この確率分布に関する尤度関数は
が与えられたとき、この確率分布に関する尤度関数は
(13) 
その対数尤度関数は
(14) 
ここでデータセット(xi, yi)として、が与えられたとき、対数尤度を最大とするようなb, wを計算する。
LogisticRegressionモデル
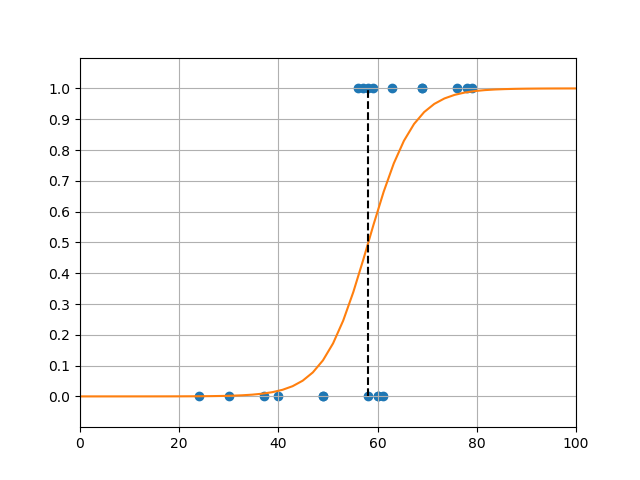
温泉のデータセットに対して、scikit-learnのLogisticRegressionモデルを適用した結果が冒頭のグラフで、コードは以下の通り。
LogisticRegressionのコンストラクターの引数としてsolver='lbfgs'を指定しているが、2020年4月時点ではこれを指定しないと警告が出るため。収束アルゴリズムにはいくつかの種類があって、データサイズや複数クラス分類・1対他分類の別などによって使い分けるようだ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
import os import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.linear_model import LogisticRegression path = os.path.join(os.path.dirname(__file__), "data_spa.csv") df = pd.read_csv(path) X = np.array(df['age']).reshape(-1, 1) y = df['is_spa'] logreg = LogisticRegression(C=1e5, solver='lbfgs') logreg.fit(X, y) b = logreg.intercept_[0] w = logreg.coef_[0][0] x_border = 0.0 - b / w print("intercept : {}".format(b)) print("coefficient: {}".format(w)) print("x_border : {}".format(x_border)) xl = 0 xr = 100 x_graph = np.linspace(xl, xr) y_graph = 1 / (1 + np.exp(- b - w * x_graph)) fig, ax = plt.subplots() ax.scatter(X, y, c='tab:blue') ax.plot(x_graph, y_graph, c='tab:orange') ax.plot([x_border, x_border], [0, 1], c='k', linestyle='dashed') ax.set_xlim(xl, xr) ax.set_ylim(-0.1, 1.1) ax.set_yticks(np.linspace(0, 1, 11)) ax.grid(True) plt.show() # intercept : -13.44995797571776 # coefficient: 0.23116842117614878 # x_border : 58.18250566961732 |
また、同じデータセットについてExcelで解いた例はこちら。
正則化
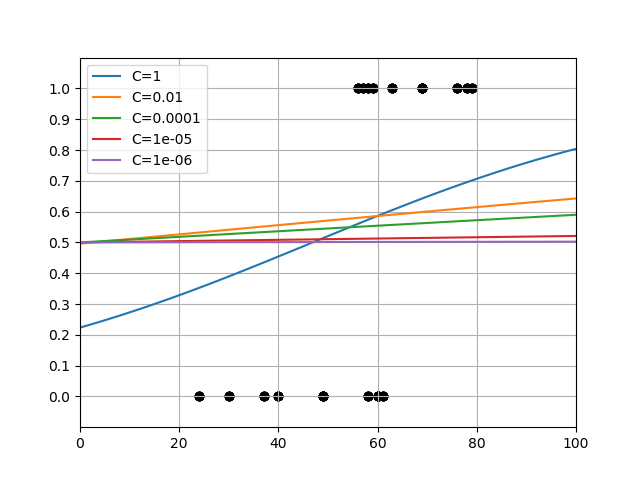
LogisticeRegressionモデルのコンストラクターの引数Cは正則化の強さを正の実数で指定する。大きな値を設定するほど正則化が弱く、小さくするほど正則化が効いてくる。
温泉のデータセットに対してCを変化させてみたところ、1000あたりから上はほとんど関数形が変わらず、ほぼ正則化がない状態。デフォルトのC=1(赤い線)は結構強い正則化のように思える。
興味深いのはこれらのグラフがほぼ1点で交わっており、その点での確率が0.6近いことである。温泉かレジャーランドかを選ぶ年齢と確率が正則化の程度に寄らず一定だということになるが、これが何を意味しているか、今のところよくわからない。
一方で、確率0.5に相当する年齢は正則化を強めていくにしたがって低くなっていて、これを判定基準とするとC=0.001ではほぼ全年齢で温泉が選択されることになってしまう。
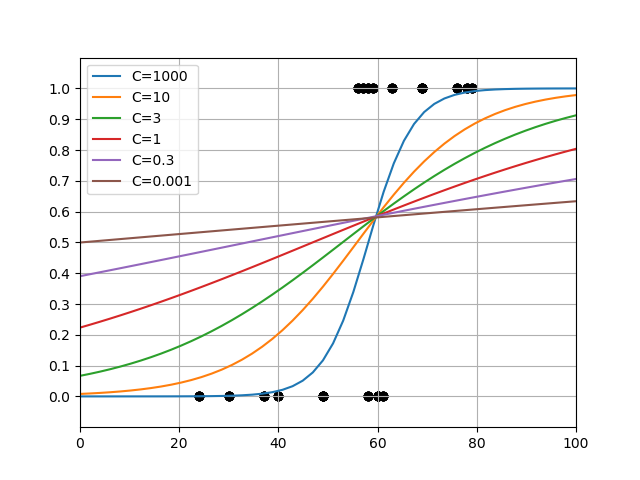
さらにCが更に小さい値になると、確率曲線はどんどんなだらかになっていき、C=1e-6では全年齢にわたって0.5、すなわち温泉、レジャーランドのいずれを選ぶかは年齢に関わらず1/2の賭けのようになっている。
2変数の場合
2変数の例として、”O’REILLYの”Pythonではじめる機械学習”にあるforgeデータの例をトレースしたものをまとめた。
Logistic回帰~forgeデータ~Pythonではじめる機械学習より
特徴量の係数
式(4)によるとziの値が大きいほどy = 1となる確率が高くなり、小さいほどy = 0となる確率が高くなる。また、特徴量xi ≥ 0とすると、係数wiが正のときにはziを増加させる効果、負の時にはziを減少させる効果がある。y = 0, 1にターゲット0, 1が割り当てられ、それらがクラス0、クラス1を表すとすると、係数が正のときにはその特徴量の増加がクラス1を選択する方向に働き、係数が負の時にはクラス0をを選択する方向に働く。
以下は特徴量数2、クラス数2の簡単な例で、Feature-0は係数が正なのでクラス0を選択する確率を高め、Feature-1の係数は係数が負なのでクラス1を選択する確率を高める。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_blobs from sklearn.linear_model import LogisticRegression X, y = make_blobs(n_samples=100, n_features=2, centers=2, random_state=9) logreg = LogisticRegression().fit(X, y) coef = logreg.coef_.reshape(logreg.coef_.size) f0 = np.linspace(-15, 3) f1 = (- logreg.intercept_ - coef[0] * f0) / coef[1] print("intercept:{}".format(logreg.intercept_)) print("coef:{}".format(coef)) fig, ax = plt.subplots() ax.scatter(X[y==0][:, 0], X[y==0][:, 1], label="Class-0") ax.scatter(X[y==1][:, 0], X[y==1][:, 1], label="Class-1") ax.plot(f0, f1, c='g') ax.set_xlim(-14, 4) ax.set_ylim(-12, 6) ax.set_xlabel("Feature-0") ax.set_ylabel("Feature-1") ax.legend() plt.show() # intercept:[2.11704743] # coef:[ 0.89424625 -0.66371147] |