概要
matplotlib.patchesパッケージに様々な図形クラスが準備されていて、Axesのadd_patch()メソッドでそれらのオブジェクトを加えていく。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import matplotlib.pyplot as plt import matplotlib.patches as patch fig, ax = plt.subplots() circ = patch.Circle(xy=(3, 3), radius=2, ec='b', fc='gray') elli = patch.Ellipse(xy=(2, 1), width=2, height=1, ec='g', fill=False, angle=10) rect = patch.Rectangle(xy=(1, 2), width=3, height=2, ec='b', fc='w', angle=30) ax.add_patch(circ) ax.add_patch(elli) ax.add_patch(rect) ax.set_xlim(0, 6) ax.set_ylim(0, 6) ax.set_aspect('equal') plt.show() |
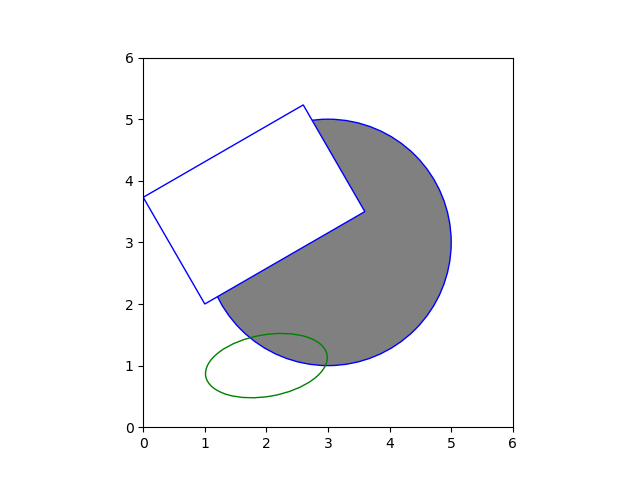
各種図形
以下の点は各図形において共通
- ほとんどの図形は引数
xyで基準点のx座標とy座標をタプルで与える edgecolor/ecで外枠の色、facecolor/fcで塗りつぶし色を指定するfill=True/Falseで塗りつぶしの有無を指定する- angleで傾きの角度を指定できる図形がある
Circle(xy[, radius=5])- 中心点を指定して円を描く。
Ellipse(xy, width, height[, angle])- 中心点と幅・高さを指定して楕円を描く。
Rectangle(xy, width, height[, angle])- 左下の点と幅・高さを指定して楕円を描く。
CirclePolygon(x, y, rasius=5, resolution=20)- 多角形を描画。辺/頂点の数を
resolutionで指定する。 Polygon(xy, closed=True)- 複数の点を指定して図形を描画する。xyはNx2配列(xy座標を要素とした2次元配列)。closedをFalseに指定すると図形の最初の点と最後の点を結ばない。
Arc(xy, width, height[, angle, theta1, theta2])- 楕円の一部の弧を描く。扇形に中を塗りつぶすことはできない。
Wedge(center, r, theta1, theta2[, width=None])- 円の一部を切出した図形を描く。widhを指定すると中心からその長さだけ除かれて描かれる。
Arrow(x, y, dx, dy[, width, ...])- 矢印を描画する。
FancyArrow(x, y, dx, dy[, width, ...])- 鏃を片側だけにしたり、鏃の大きさや形を設定したりできる。








![\begin{equation*} \left[ \begin{array}{cccc} n & S_1 & \cdots & S_m \\ S_1 & S_{11} + \alpha & & S_{1m} \\ \vdots & \vdots & & \vdots \\ S_m & S_{m1} & \cdots & S_{mm} + \alpha \end{array} \right] \left[ \begin{array}{c} w_0 \\ w_1 \\ \vdots \\ w_m \end{array} \right] = \left[ \begin{array}{c} S_y \\S_{1y} \\ \vdots \\ S_{my} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-7e7bba69bc36153a376daa558ddbf28a_l3.png "Rendered by QuickLaTeX.com")
 を消去して、以下の連立方程式を得る。
を消去して、以下の連立方程式を得る。![\begin{align*} &\left[ \begin{array}{ccc} ( S_{11} + \alpha ) - \dfrac{{S_1}^2}{n} & \cdots & S_{1m} - \dfrac{S_1 S_m}{n} \\ \vdots & & \vdots \\ S_{m1} - \dfrac{S_m S_1}{n} & \cdots & ( S_{mm} + \alpha )- \dfrac{{S_2}^2}{n} \end{array} \right] \left[ \begin{array}{c} w_1 \\ \vdots \\ w_m \end{array} \right] \\&= \left[ \begin{array}{c} S_{1y} - \dfrac{S_1 S_y}{n} \\ \vdots \\ S_{my} - \dfrac{S_m S_y}{n} \end{array} \right] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-17a68647af45d80bac08fd44b3135e4c_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \left[ \begin{array}{ccc} V_{11} + \dfrac{\alpha}{n} & \cdots & V_{1m} \\ \vdots & & \vdots \\ V_{m1} & \cdots & V_{mm} + \dfrac{\alpha}{n} \end{array} \right] \left[ \begin{array}{c} w_1 \\ \vdots \\ w_m \end{array} \right] = \left[ \begin{array}{c} V_{1y} \\ \vdots \\ V_{my} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-3a7696ac06d6f37063cc1e74c39f4bab_l3.png "Rendered by QuickLaTeX.com")
 とすると、
とすると、
![\begin{align*} \left[ \begin{array}{ccccccc} V_{11} + \dfrac{\alpha}{n} & \cdots & V_{1i} & \cdots & aV_{1i} & \cdots & V_{1m}\\ \vdots && \vdots && \vdots && \vdots\\ V_{i1} & \cdots & V_{ii} + \dfrac{\alpha}{n} & \cdots & aV_{ii} & \cdots & V_{im}\\ \vdots && \vdots && \vdots && \vdots\\ aV_{i1} & \cdots & aV_{ii} & \cdots & a^2V_{ii} + \dfrac{\alpha}{n} & \cdots & aV_{im}\\ \vdots && \vdots && \vdots && \vdots\\ V_{m1} & \cdots & V_{mi} & \cdots & aV_{mi} & \cdots & V_{mm} + \dfrac{\alpha}{n} \end{array} \right] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-6eff526fb57f5dc6657a032f7dc7da8d_l3.png "Rendered by QuickLaTeX.com")













![\begin{equation*} \boldsymbol{x} = \left[ \begin{array}{c} x_1 \\ \vdots \\ x_n \\ \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-ca095fba05bd6b51953489329a4dbed5_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \boldsymbol{X} = \left[ \begin{array}{ccc} x_{11} & \ldots & x_{1n} \\ \vdots & x_{ij} & \vdots \\ x_{m1} & \ldots & x_{mn} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-b789d485dcbf0314d7147eaf2ac533f1_l3.png "Rendered by QuickLaTeX.com")

![\begin{equation*} \boldsymbol{f}(x) = \left[ \begin{array}{c} f_1(x) \\ \vdots \\ f_n(x) \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-0c143adda5de76e2ad2d9f369b269daa_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \boldsymbol{f}(\boldsymbol{x}) =\ \left[ \begin{array}{c} f_1(x_1, \ldots, x_n) \\ \vdots \\ f_m(x_1, \ldots, x_n) \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-e1402f4bca526f4e708673a396a76432_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \boldsymbol{F}(x) = \left[ \begin{array}{ccc} F_{11}(x) & \ldots & F_{1n}(x) \\ \vdots & F_{ij} & \vdots \\ F_{m1}(x) & \ldots & F_{mn}(x) \\ \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-11b648294a10e1e0bd969847ac5eca32_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \frac{d \boldsymbol{f}(x)}{dx} = \left[ \begin{array}{c} \dfrac{d f_1(x)}{dx} \\ \vdots \\ \dfrac{d f_n(x)}{dx} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-2a6538c824acdcefdc708eecff19c4c9_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \frac{d \boldsymbol{F}(x)}{dx} = \left[ \begin{array}{ccc} \dfrac{dF_{11}(x)}{dx} & \ldots & \dfrac{dF_{1n}(x)}{dx} \\ \vdots & \dfrac{dF_{ij}(x)}{dx} & \vdots \\ \dfrac{dF_{m1}(x)}{dx} & \ldots & \dfrac{dF_{mn}(x)}{dx} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-fcd4c19cbe8c45de7a76c60b7e7414be_l3.png "Rendered by QuickLaTeX.com")
 のベクトルで微分すると、同じ次数のベクトルになる。
のベクトルで微分すると、同じ次数のベクトルになる。![\begin{equation*} \frac{df(\boldsymbol{x})}{d\boldsymbol{x}} = \left[ \begin{array}{c} \dfrac{\partial f}{\partial x_1} \\ \vdots \\ \dfrac{\partial f}{\partial x_m} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-91df3f7d18edb4fce8d49b885fd8ba4d_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \frac{d}{d\boldsymbol{x}}f(\boldsymbol{x}) = \left[ \begin{array}{c} \dfrac{\partial}{\partial x_1} \\ \vdots \\ \dfrac{\partial}{\partial x_m} \end{array}\right] f(\boldsymbol{x}) \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-4f4019636c967a53d820033d665ac0e0_l3.png "Rendered by QuickLaTeX.com")
 の行列で微分すると、同じ次元・次数の行列になる。
の行列で微分すると、同じ次元・次数の行列になる。![\begin{equation*} \frac{df(\boldsymbol{X})}{d\boldsymbol{X}} = \left[ \begin{array}{ccc} \dfrac{\partial f}{\partial x_{11}} & \ldots & \dfrac{\partial f}{\partial x_{1n}} \\ \vdots & \dfrac{\partial f}{\partial x_{ij}} & \vdots \\ \dfrac{\partial f}{\partial x_{m1}} & \ldots & \dfrac{\partial f}{\partial x_{mn}} \\ \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-420e553422141fba601f4663078d0386_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \frac{d}{d\boldsymbol{X}} f(\boldsymbol{X}) = \\ \left[ \begin{array}{ccc} \dfrac{\partial}{\partial x_{11}} & \ldots & \dfrac{\partial}{\partial x_{1n}} \\ \vdots & \dfrac{\partial}{\partial x_{ij}} & \vdots \\ \dfrac{\partial}{\partial x_{m1}} & \ldots & \dfrac{\partial}{\partial x_{mn}} \\ \end{array} \right] f(\boldsymbol{X}) \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-99d9e67383e94425fcf5d01ea0223e26_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \frac{d\boldsymbol{f}(\boldsymbol{x})^T}{d\boldsymbol{x}} = \left[ \begin{array}{ccc} \dfrac{\partial f_1}{\partial x_1} & \ldots & \dfrac{\partial f_n}{\partial x_1} \\ \vdots & \dfrac{\partial f_j}{\partial x_i} & \vdots \\ \dfrac{\partial f_1}{\partial x_m} & \ldots & \dfrac{\partial f_n}{\partial x_m} \\ \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-311d88dd2427ed7067a39ffafa8dad8d_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \frac{d}{d\boldsymbol{x}} \boldsymbol{f}(\boldsymbol{x})^T = \left[ \begin{array}{c} \dfrac{\partial}{\partial x_1} \\ \vdots \\ \dfrac{\parial}{\partial x_m} \end{array} \right] [ f_1(\boldsymbol{x}) \; \ldots \; f_n(\boldsymbol{x}) ] = \left[ \begin{array}{ccc} \dfrac{\partial f_1}{\partial x_1} & \cdots & \dfrac{\partial f_n}{\partial x_1} \\ & \dfrac{\partial f_j}{\partial x_i} &\\ \dfrac{\partial f_1}{\partial x_m} & \cdots & \dfrac{\partial f_n}{\partial x_m} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-9a2aab5d164571bef0094ea7f1eaf975_l3.png "Rendered by QuickLaTeX.com")


![\begin{align*} \frac{df}{dx_i} &= \frac{\partial f}{\partial u_1}\frac{\partial u_1}{\partial x_i} + \cdots + \frac{\partial f}{\partial u_j}\frac{\partial u_j}{\partial x_i} + \cdots + \frac{\partial f}{\partial u_n}\frac{\partial u_n}{\partial x_i} \\ \rightarrow \frac{df(\boldsymbol{u}(\boldsymbol{x}))}{d\boldsymbol{x}} &= \left[ \begin{array}{ccc} \dfrac{\partial u_1}{\partial x_1} & \cdots & \dfrac{\partial u_n}{\partial x_1} \\ \vdots && \vdots \\ \dfrac{\partial u_1}{\partial x_m} & \cdots & \dfrac{\partial u_n}{\partial x_m} \\ \end{array} \right] \left[ \begin{array}{c} \dfrac{\partial f}{\partial u_1} \\ \vdots \\ \dfrac{\partial f}{\partial u_n} \end{array} \right] \\ &= \left[ \begin{array}{c} \dfrac{\partial}{\partial x_1} \\ \vdots \\ \dfrac{\partial}{\partial x_m} \end{array} \right] [u_1 \; \cdots \; u_n] \left[ \begin{array}{c} \dfrac{\partial}{\partial u_1} \\ \vdots \\ \dfrac{\partial}{\partial u_n} \end{array} \right] f(\boldsymbol{u}) \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-299db8ffb5c52904ccea0f0f44844cb4_l3.png "Rendered by QuickLaTeX.com")

![\begin{align*} \frac{d(\boldsymbol{FG})}{dx} &= \frac{d}{dx}\left[\sum_{j=1}^m f_{ij} g_{jk}\right] = \left[\sum_{j=1}^m \left(\frac{df_{ij}}{dx} g_{jk} + f_{ij} \frac{dg_{jk}}{dx} \right)\right] \\ &= \left[ \sum_{j=1}^m \frac{df_{ij}}{dx} g_{jk} \right] + \left[ \sum_{j=1}^m f_{ij} \frac{dg_{jk}}{dx} \right] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-48367a30bf2176691b7825652e570751_l3.png "Rendered by QuickLaTeX.com")

![\begin{equation*} \begin{align} & \frac{d}{d\boldsymbol{x}} \left[ \begin{array}{c} a_{11}x_1 + \cdots + a_{1j}x_j + \cdots + a_{1n}x_n \\ \vdots \\ a_{i1}x_1 + \cdots + a_{ij}x_j + \cdots + a_{in}x_n \\ \vdots \\ a_{m1}x_1 + \cdots + a_{mj}x_j + \cdots + a_{mn}x_n \\ \end{array} \right]^T \\ &= \left[ \begin{array}{c} \dfrac{\partial}{\partial x_1} \\ \vdots \\ \dfrac{\partial}{\partial x_j} \\ \vdots \\ \dfrac{\partial}{\partial x_n} \\ \end{array} \right] \left[ \begin{array}{c} a_{11}x_1 + \cdots + a_{1j}x_j + \cdots + a_{1n}x_n \\ \vdots \\ a_{i1}x_1 + \cdots + a_{ij}x_j + \cdots + a_{in}x_n \\ \vdots \\ a_{m1}x_1 + \cdots + a_{mj}x_j + \cdots + a_{mn}x_n \\ \end{array} \right]^T \\ &= \left[ \begin{array}{ccccc} a_{11} & \cdots & a_{i1} & \cdots & a_{m1} \\ \vdots && \vdots && \vdots \\ a_{1j} & \cdots & a_{ij} & \cdots & a_{mj} \\ \vdots && \vdots && \vdots \\ a_{1n} & \cdots & a_{in} & \cdots & a_{mn} \\ \end{array} \right] = \boldsymbol{A}^T \end{align} \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-ae74fc9540924803afe8d58422df0a6f_l3.png "Rendered by QuickLaTeX.com")

![\begin{equation*} \left[ \begin{array}{c} \dfrac{\partial}{\partial x_1} \\ \vdots \\ \dfrac{\partial}{\partial x_n} \end{array} \right] [ x_1^2 + \cdots + x_n^2 ] = \left[ \begin{array}{c} 2x_1 \\ \vdots \\ 2x_n \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-9a4a53d35d99be2161876f0ebea4b973_l3.png "Rendered by QuickLaTeX.com")
 は正方行列で、
は正方行列で、 と同じ次数でなければならない。
と同じ次数でなければならない。
![\begin{align*} &\frac{d}{d \boldsymbol{x}} \left( [x_1 \; \cdots \; x_n] \left[ \begin{array}{ccc} a_{11} & \cdots & a_{1n} \\ \vdots & & \vdots \\ a_{n1} & \cdots & a_{nn} \\ \end{array} \right] \left[ \begin{array}{c} x_1 \\ \vdots \\ x_n \end{array} \right] \right)\\ &=\frac{d}{d \boldsymbol{x}} \left( [x_1 \; \cdots \; x_n] \left[ \begin{array}{c} a_{11} x_1 + \cdots + a_{1n} x_n \\ \vdots \\ a_{n1} x_1 + \cdots + a_{nn} x_n \end{array} \right] \right)\\ &= \frac{d}{d \boldsymbol{x}} \left( \left( a_{11} {x_1}^2 + \cdots + a_{1n} x_1 x_n \right) + \cdots + \left( a_{n1} x_n x_1 + \cdots + a_{nn} {x_n}^2 \right) \right) \end{array}\\ &=\left[ \begin{array}{c} \left( 2 a_{11} x_1 + \cdots + a_{1n} x_n \right) + a_{21} x_2 + \cdots + a_{n1} x_n \\ \vdots \\ a_{1n} x_1 + \cdots + a_{1n-1} x_{n-1} + \left( a_{n1} x_1 + \cdots + 2a_{nn} x_n \right) \end{array} \right] \\ &=\left[ \begin{array}{c} \left( a_{11} x_1 + \cdots + a_{1n} x_1 \right) + \left( a_{11} x_1 + \cdots + a_{n1} x_n \right) \\ \vdots \\ \left( a_{n1} x_1 + \cdots + a_{nn} x_n \right) + \left( a_{1n} x_1 + \cdots + a_{nn} x_n \right) \end{array} \right] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-deafe332adeef9ea5b9eb9c5cfbd1ef5_l3.png "Rendered by QuickLaTeX.com")








![\begin{align*} \left( [ \boldsymbol{AB} ]_{ij} \right)^T = \left( \sum_k \boldsymbol{A}_{ik} \boldsymbol{B}_{kj} \right)^T = \sum_k \boldsymbol{B}_{jk} \boldsymbol{A}_{ki} =\boldsymbol{B}^T \boldsymbol{A}^T \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-e0a675c84ad11bc2c66bd764f6b3dfeb_l3.png "Rendered by QuickLaTeX.com")

![\begin{equation*} \left[ \begin{array}{ccc} a_{11} & \cdots & a_{1n} \\ \vdots & & \vdots \\ a_{m1} & \cdots & a_{mn} \\ \end{array} \right] \left[ \begin{array}{c} x_1 \\ \vdots \\ x_n \end{array} \right] = [x_1 \; \cdots \; x_n] \left[ \begin{array}{ccc} a_{11} & \cdots & a_{m1} \\ \vdots & & \vdots \\ a_{1n} & \cdots & a_{mn} \\ \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-47268abd1fb09618f4ac57dcd0edb815_l3.png "Rendered by QuickLaTeX.com")

![\begin{equation*} [x_1 \; \cdots \; x_n] \left[ \begin{array}{c} x_1 \\ \vdots \\ x_n \end{array} \right] = x_1^2 + \cdots + x_n^2 \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-d7eb4031678ac7ca0faa0eefd7cb4318_l3.png "Rendered by QuickLaTeX.com")