概要
Scikit-learnの決定木モデル、DecisionTreeClassifierについていろいろ試した際のコードをストック。
Treeオブジェクト内容確認
DecisionTreeClassifierオブジェクトのプロパティーtree_はデータセットに対して生成された決定木の構造が保存されている。以下はその内容を確認するためのコード。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_moons from sklearn.tree import DecisionTreeClassifier X, y = make_moons(n_samples=20, noise=0.25, random_state=3) treeclf = DecisionTreeClassifier(random_state=0) treeclf.fit(X, y) tree = treeclf.tree_ n_nodes = tree.node_count children_left = tree.children_left children_right = tree.children_right features = tree.feature thresholds = tree.threshold value = tree.value print("number of nodes: {}".format(n_nodes)) print("Chlidren(Left) : {}".format(children_left)) print("Chlidren(Right): {}".format(children_right)) print("Features : {}".format(features)) print("Thresholds : {}".format(np.round(thresholds, 3))) print("Values:\n{}".format(value)) print() for i in range(n_nodes): print("Node-{}".format(i), end="") print("(Feature[{:2d}]<{:6.3f}):"\ .format(features[i], thresholds[i]), end="") print("LeftNode[{:2d}], RightNode[{:2d}]"\ .format(children_left[i], children_right[i])) |
Treeクラスはツリー内の各ノードの情報を1次元の配列でもっていて、子ノードを参照するにはノード番号に対応する配列のインデックスを参照する。Treeクラスが持っている主なプロパティーは以下の通り。
node_count- ツリーが持つ全ノード数。
children_left, children_right- 各ノードの左/右の子ノードの番号を格納した1次元配列。
feature- 各ノードを分割する際に使われる特徴量の番号を格納した1次元配列。
threshold- 各ノードを
featureで示された特性量で分割する際の閾値を格納した1次元配列。 value- 各ノードにおける、各クラスのデータ数。クラス数分のデータを格納した1次元配列1つだけを要素とする2次元配列を、ノード数分だけ集めた3次元配列。
コードの実行結果は以下の通り。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
number of nodes: 7 Chlidren(Left) : [ 1 2 -1 -1 5 -1 -1] Chlidren(Right): [ 4 3 -1 -1 6 -1 -1] Features : [ 1 0 -2 -2 0 -2 -2] Thresholds : [ 0.072 -0.643 -2. -2. 1.536 -2. -2. ] Values: [[[10. 10.]] [[ 1. 9.]] [[ 1. 0.]] [[ 0. 9.]] [[ 9. 1.]] [[ 9. 0.]] [[ 0. 1.]]] Node-0(Feature[ 1]< 0.072):LeftNode[ 1], RightNode[ 4] Node-1(Feature[ 0]<-0.643):LeftNode[ 2], RightNode[ 3] Node-2(Feature[-2]<-2.000):LeftNode[-1], RightNode[-1] Node-3(Feature[-2]<-2.000):LeftNode[-1], RightNode[-1] Node-4(Feature[ 0]< 1.536):LeftNode[ 5], RightNode[ 6] Node-5(Feature[-2]<-2.000):LeftNode[-1], RightNode[-1] Node-6(Feature[-2]<-2.000):LeftNode[-1], RightNode[-1] |
親ノードと子ノードの関係は、たとえばノード0の左右の子ノードはchildren_leftとchildren_rightの0番目の要素からノード1とノード4、ノード1の左右の子ノードはノード2とノード3、という風に追っていくことができる。
valueがややこしい。この配列は各ノードにおけるクラスごとのデータ数を格納している。全体配列の中にこのケースだとノード数に対応する7個の配列が要素として格納されているが、その配列が2次元配列になっていて、その要素の配列がクラスごとのデータを格納した配列になっている。例えば3番目の要素のクラス1の要素を取り出す場合にはvalue[3, 0, 1]と言う風に指定することになる。
Treeのコンソール表示
Treeオブジェクトのツリー構造を確認し、決定境界の描画などの準備とするために書いたコード。決定木の構造をコンソールに表示させる。2つの再帰関数を定義していて、本体は決定木学習後にそれらの関数を呼び出すのみ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
from sklearn.datasets import make_moons from sklearn.tree import DecisionTreeClassifier def print_node1(tree, i_node, n_level=0): print("{}{:2d}-feature:{:2d}"\ .format(" " * n_level, i_node, tree.feature[i_node])) if tree.children_left[i_node] == -1: return print_node1( tree=tree, i_node=tree.children_left[i_node], n_level=n_level+1) print_node1( tree=tree, i_node=tree.children_right[i_node], n_level=n_level+1) def print_node2(tree, i_node, n_level=0): if tree.children_left[i_node] == -1: print("{}{:2d}-feature:{:2d}"\ .format(" " * n_level, i_node, tree.feature[i_node])) return print_node2( tree=tree, i_node=tree.children_left[i_node], n_level=n_level+1) print("{}{:2d}-feature:{:2d}"\ .format(" " * n_level, i_node, tree.feature[i_node])) print_node2( tree=tree, i_node=tree.children_right[i_node], n_level=n_level+1) X, y = make_moons(n_samples=20, noise=0.25, random_state=3) treeclf = DecisionTreeClassifier(random_state=0) treeclf.fit(X, y) tree = treeclf.tree_ print_node1(tree=tree, i_node=0) print("-"*40) print_node2(tree=tree, i_node=0) |
関数print_node1()は、ツリー構造をルートノードから階層が下がるごとに段下げして表示していく。このため、まず親ノードを表示してから左右の子ノードを引数として再帰呼び出しをしている。
終了条件はノードが子ノードを持たない葉(leaf)であることを利用するが、リーフの時のパラメータは以下の通りで、ここでは左子ノードの番号が−1となることを利用している。
- 子ノードの番号が−1
- 特性量の番号が−2
- 特性量の閾値が−2.0
関数print_node2は、決定木の構造を枝分かれした木の形で表示する。左側のノードから右側に移るのを、コンソール上で上から下に表示していく。手順としては、
- リーフノードならノードの内容を出力してリターン
- リーフノードでなければ、
- 左子ノードの処理を呼び出す
- それが戻ってきたら(左側の全子孫ノードが出力されたら)自身の内容を出力
- 右子ノードの処理を呼び出す
- それが戻ってきたら(右側の全子孫ノードが出力されたら)リターン
引数に現在のノードの階層を保持する変数があり、その階層に応じた数のスペースでインデントすることで木の構造を表す。
出力は以下の通り。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
0-feature: 1 1-feature: 0 2-feature:-2 3-feature:-2 4-feature: 0 5-feature:-2 6-feature:-2 ---------------------------------------- 2-feature:-2 1-feature: 0 3-feature:-2 0-feature: 1 5-feature:-2 4-feature: 0 6-feature:-2 |
決定木の構築過程の表示
make_monns()による2特性量のデータについて、順次ノードを分割する過程を図で描画するためのコード。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as patch from sklearn.datasets import make_moons from sklearn.tree import DecisionTreeClassifier def draw_tree_boundary(tree, ax, left, right, bottom, top, i_node=0, stop_level=None, n_level=0): if tree.children_left[i_node] == -1 or stop_level == n_level: fc =\ 'tab:orange' if np.argmax(tree.value[i_node][0])==0 else 'tab:blue' rect = patch.Rectangle(xy=(left, bottom), width=right-left, height=top-bottom, fc=fc, alpha=0.2) ax.add_patch(rect) return if tree.feature[i_node] == 0: f0 = tree.threshold[i_node] ax.plot([f0, f0], [top, bottom]) draw_tree_boundary(tree=tree, ax=ax, left=left, right=f0, top=top, bottom=bottom, i_node=tree.children_left[i_node], stop_level=stop_level, n_level=n_level+1,) draw_tree_boundary(tree=tree, ax=ax, left=f0, right=right, top=top, bottom=bottom, i_node=tree.children_right[i_node], stop_level=stop_level, n_level=n_level+1) else: f1 = tree.threshold[i_node] ax.plot([left, right], [f1, f1]) draw_tree_boundary(tree=tree, ax=ax, left=left, right=right, top=f1, bottom=bottom, i_node=tree.children_left[i_node], stop_level=stop_level, n_level=n_level+1) draw_tree_boundary(tree=tree, ax=ax, left=left, right=right, top=top, bottom=f1, i_node=tree.children_right[i_node], stop_level=stop_level, n_level=n_level+1) X, y = make_moons(n_samples=20, noise=0.25, random_state=5) treeclf = DecisionTreeClassifier(random_state=0) treeclf.fit(X, y) tree = treeclf.tree_ fig, ax = plt.subplots() ax.scatter(X[y==0][:, 0], X[y==0][:, 1], ec='k', s=60, marker='o', label="Class 0") ax.scatter(X[y==1][:, 0], X[y==1][:, 1], ec='k', s=60, marker='^', label="Class 1") x0_min, x0_max = -2, 2.5 x1_min, x1_max = -1, 1.5 draw_tree_boundary(tree=tree, i_node=0, ax=ax, left=x0_min, right=x0_max, bottom=x1_min, top=x1_max, stop_level=None) ax.set_xlim(x0_min, x0_max) ax.set_ylim(x1_min, x1_max) ax.legend() plt.show() |
draw_tree_boundary()関数は再帰関数で、もしそのノードがリーフノードか指定された終了階層の場合はクラスに応じた色で領域を塗りつぶす。リーフノードでなければ、閾値が特性量0の場合と1の場合で境界線の縦横や開始終了位置を変化させて再帰的に関数を呼び出す。引数stop_levelに正の整数を指定することで、その階層までの描画に留めることができる。関数の内容についてはこちらを参照。
本体はデータをクラスごとの色で散布図として描き、ルートノードについてdraw_tree_boundary()を呼び出している。
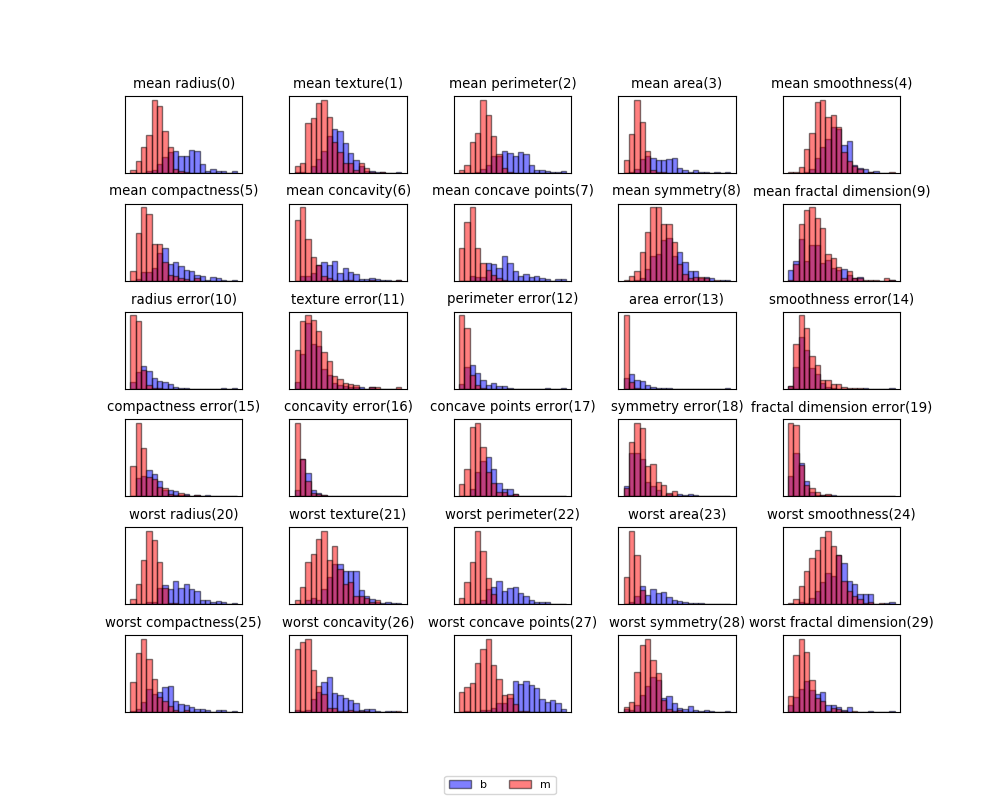
以下は、実行例。
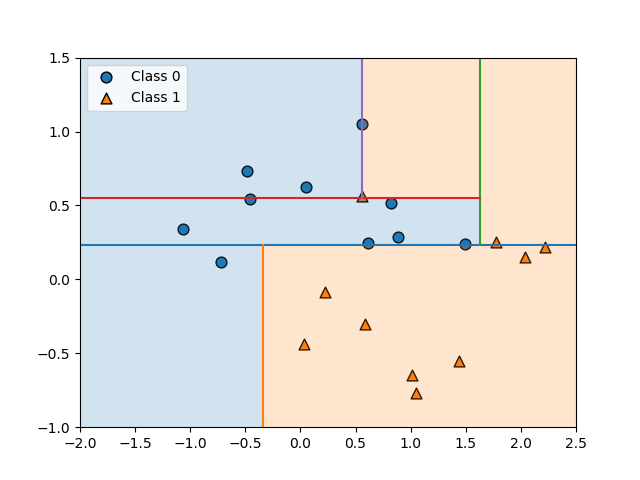
以下は、stop_levelを順次増やしていって、領域が分割される過程を描いた例。
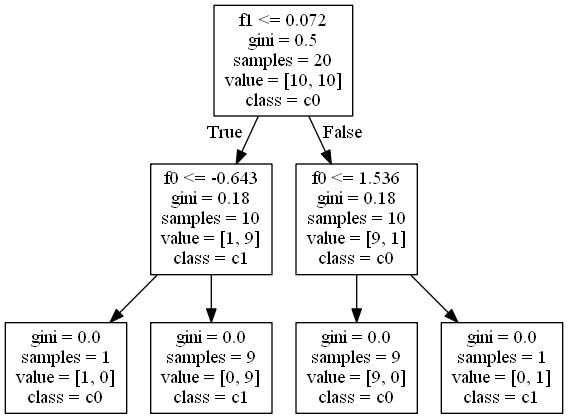
決定木のツリー表示
DecisionTreeClassificationオブジェクトを可視化する環境によって、決定木を表示する例。
- 環境構築
- Pythonで
pydotplusパッケージを導入 - Graphviz環境を構築
- Pythonで
- 実行
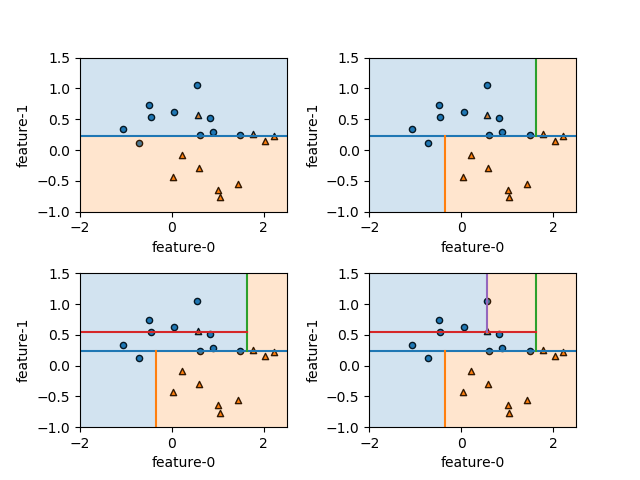
sklearn.tree.export_graphviz()で決定木のdotデータを得るpydotplus.graph_from_dot_data()でDotオブジェクトを生成write_png()などのメソッドでグラフを画像として書き出す
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import numpy as np import pydotplus as pdp from sklearn.datasets import make_moons from sklearn.tree import DecisionTreeClassifier, export_graphviz X, y = make_moons(n_samples=20, noise=0.25, random_state=5) treeclf = DecisionTreeClassifier(random_state=0) treeclf.fit(X, y) dot_data = export_graphviz(treeclf, max_depth=None, feature_names=["feature-0", "feature-1"], class_names=["class-0", "class-1"]) graph = pdp.graph_from_dot_data(dot_data) graph.write_png("tree.png") # C:...\atom\app-1.47.0 |
このコードはAtom上でコードを実行したため、Atomのディレクトリーに画像ファイルが書き出される。








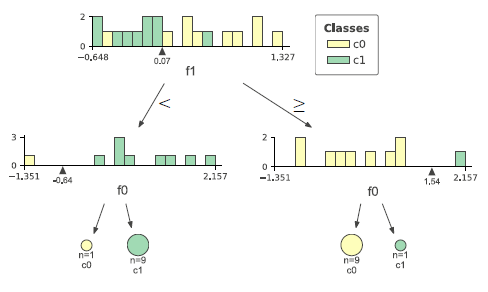


![\begin{align*} w_{cf} &= \left[ \begin{array}{rrr} -0.17492222 & 0.23140089 \\ 0.4762125 & -0.06936704 \\ -0.18914556 & -0.20399715 \end{array} \right] \\ b_c &= [-1.07745632 \quad 0.13140349 \quad -0.08604899] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-8fbdc9a0c6266b87c93914dfd375a1e0_l3.png "Rendered by QuickLaTeX.com")