概要
Scikit-learnから入手できるLFW peopleデータセットは、世界の著名人の顔画像データを集めたものである。
1人につき1枚~最大530枚の画像データが、それぞれの人に対して紐づけされている。
LFWは”Labeled Faces in the Wild”の略で、”in the Wild”には「出回っている」というニュアンスがあるらしい。
IrisやBostonなどのデータと異なり、Scikit-learnをインストールした状態ではデータはローカルに格納されず、最初の読み込み時にデータがダウンロードされてローカルに格納される。1度ダウンロードされた後は、ローカルのデータが使われる。
【注意】
fetch_lfw_people()のresize引数を変更すると、そのたびにデータのダウンロードが実行されるようなので、実行ごとの時間を節約したい場合はresizeの値を決めておくとよい
データの取得
データの読み込みは以下の手順による。
sklearn.datasets.fetch_lfw_peopleをインポートするfetch_lfw_poeple()関数でBunchオブジェクトのデータセットを読み込むfetch_lfw_peple()関数を最初に実行したときに、ローカルにデータが読み込まれる(これには数分程度かかる)- 一度読み込まれた後は、ローカル上のデータが使われる
- ローカル上のデータの場所は、ログインしたユーザーのホームディレクトリー下、schikit_learn_dataディレクトリー
データ構造
データセットはBunchオブジェクトで、辞書型のkeyとvalueで内容を取得できる。
|
1 2 3 4 5 6 |
from sklearn.datasets import fetch_lfw_people ds = fetch_lfw_people() for key, value in zip(ds.keys(), ds.values()): print("{}:\n{}\n".format(key, value)) |
内容は以下の通りで、
dataとimagesは顔画像データを異なる形状の配列で格納したものtargetは各顔画像の人物idtarget_namesは各idに対する人物の名前DESCRはデータに関する説明。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
data: [[ 34. 29.333334 22.333334 ... 14.666667 16. 14. ] [158. 160.66667 169.66667 ... 138.66667 135.66667 130.33333 ] [ 76.666664 81. 87.666664 ... 191.66667 145.33333 66. ] ... [ 38.333332 41.666668 55. ... 66. 63.333332 54.666668] [ 16.666666 24.333334 60.333332 ... 219. 144. 69. ] [ 58.333332 48. 20. ... 116. 105.666664 143.66667 ]] images: [[[ 34. 29.333334 22.333334 ... 20. 26. 31. ] [ 37.333332 32. 25.333334 ... 21. 27. 32. ] [ 33.333332 32. 40.333332 ... 23.333334 28.666666 35.666668] ... [166. 96.666664 44.666668 ... 9.333333 14. 12. ] [ 64.333336 39. 30.333334 ... 13. 16. 14. ] [ 30.333334 29. 26.333334 ... 14.666667 16. 14. ]] ... [[ 58.333332 48. 20. ... 66. 101.666664 94.666664] [ 62.333332 32.666668 26.333334 ... 50.666668 90. 101.666664] [ 56. 29.333334 47.333332 ... 55.333332 76.666664 106.666664] ... [116.333336 107. 95. ... 113.333336 100.666664 88.333336] [116.666664 105. 94. ... 116. 103.666664 111.666664] [116. 103.333336 95.333336 ... 116. 105.666664 143.66667 ]]] target: [5360 3434 3807 ... 2175 373 2941] target_names: ['AJ Cook' 'AJ Lamas' 'Aaron Eckhart' ... 'Zumrati Juma' 'Zurab Tsereteli' 'Zydrunas Ilgauskas'] DESCR: .. _labeled_faces_in_the_wild_dataset: The Labeled Faces in the Wild face recognition dataset ------------------------------------------------------ This dataset is a collection of JPEG pictures of famous people collected over the internet, all details are available on the official website: ..... Examples ~~~~~~~~ :ref:`sphx_glr_auto_examples_applications_plot_face_recognition.py` PS C:\Users\tomo\GoogleDrive\IT_and_Mobile\dev\python\packages\sklearn.datasets\lfw_people> |
データの内容
target_names~ターゲットの人物
ターゲットとなる人の名前はtarget_namesに格納されていて、その数は20201122時点で5,749人分のユニークなデータ。
名前に対するインデックスがターゲットのidになる。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import numpy as np import pandas as pd from sklearn.datasets import fetch_lfw_people ds = fetch_lfw_people() print(ds.target_names.shape) # (5749,) print(ds.target_names) # ['AJ Cook' 'AJ Lamas' 'Aaron Eckhart' ... 'Zumrati Juma' 'Zurab Tsereteli' # 'Zydrunas Ilgauskas'] |
target~ターゲット数
ターゲットのidはtargetに1次元配列で格納されている。
1人のターゲットに複数枚の異なる顔画像が格納されているものもあり、targetデータに格納されたターゲットデータ全体は13,233個。
これらのidがターゲットとなる人の名前と顔画像データに結びついている。
|
1 2 3 4 5 |
print(ds.target.shape) (13233,) print(ds.target) # [5360 3434 3807 ... 2175 373 2941] |
images~顔画像のピクセルデータ
imagesには各顔画像のデータが1次元のピクセル値として格納されている。
配列のインデックスとtargetのインデックスが紐づいていて、targetの要素から顔画像の人物が特定できる。
|
1 2 |
print(ds.images.shape) print(ds.images) |
このデータの構造は以下のとおりで、13,233個の画像データが62×47のグレイスケールの配列として保存されている。
|
1 |
(13233, 62, 47) |
3次元データの構造は以下の通り。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
(13233, 62, 47) [[[ 34. 29.333334 22.333334 ... 20. 26. 31. ] [ 37.333332 32. 25.333334 ... 21. 27. 32. ] [ 33.333332 32. 40.333332 ... 23.333334 28.666666 35.666668] ... [166. 96.666664 44.666668 ... 9.333333 14. 12. ] [ 64.333336 39. 30.333334 ... 13. 16. 14. ] [ 30.333334 29. 26.333334 ... 14.666667 16. 14. ]] [[158. 160.66667 169.66667 ... 74.666664 28. 16. ] [155.66667 156. 163.33333 ... 83. 25.666666 14. ] [146.66667 144. 145. ... 82.333336 25.666666 14.666667] ... [118.666664 120. 170. ... 131.33333 126.666664 125.666664] [125. 117.666664 140.33333 ... 133.66667 132. 129.33333 ] [128.33333 123. 122. ... 138.66667 135.66667 130.33333 ]] ... [[ 58.333332 48. 20. ... 66. 101.666664 94.666664] [ 62.333332 32.666668 26.333334 ... 50.666668 90. 101.666664] [ 56. 29.333334 47.333332 ... 55.333332 76.666664 106.666664] ... [116.333336 107. 95. ... 113.333336 100.666664 88.333336] [116.666664 105. 94. ... 116. 103.666664 111.666664] [116. 103.333336 95.333336 ... 116. 105.666664 143.66667 ]]] |
data~1次元の顔画像データ
dataには顔画像のピクセルデータが各画像ごとに1次元で格納されている。
imagesと同じく、各画像データと人物が紐づけられる。
|
1 2 |
print(ds.data.shape) print(ds.data) |
このデータの構造は以下の通りで、13,233行のデータがあり、各行が2次元の配列を1次元にフラット化した形で格納されている(62×47=2914)。
|
1 |
(13233, 2914) |
2次元のデータ構造は以下の通り。
|
1 2 3 4 5 6 7 |
[[ 34. 29.333334 22.333334 ... 14.666667 16. 14. ] [158. 160.66667 169.66667 ... 138.66667 135.66667 130.33333 ] [ 76.666664 81. 87.666664 ... 191.66667 145.33333 66. ] ... [ 38.333332 41.666668 55. ... 66. 63.333332 54.666668] [ 16.666666 24.333334 60.333332 ... 219. 144. 69. ] [ 58.333332 48. 20. ... 116. 105.666664 143.66667 ]] |
データの概要
顔画像データの確認
顔画像データの内容を確認してみる。ここでは、書籍”Pythonではじめる機械学習”の例に沿って、最低20枚以上の画像がある人物から最初の10人分を取り出して表示している。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import matplotlib.pyplot as plt from sklearn.datasets import fetch_lfw_people people = fetch_lfw_people(min_faces_per_person=20) print(people.images[0].shape) fig, axes_list = plt.subplots(2, 5, figsize=(6.4, 3.2)) fig.subplots_adjust(hspace=0.5) for target, image, axes in zip(people.target, people.images, axes_list.ravel()): axes.imshow(image, 'gray') axes.set_title(people.target_names[target], fontsize=8) plt.show() |
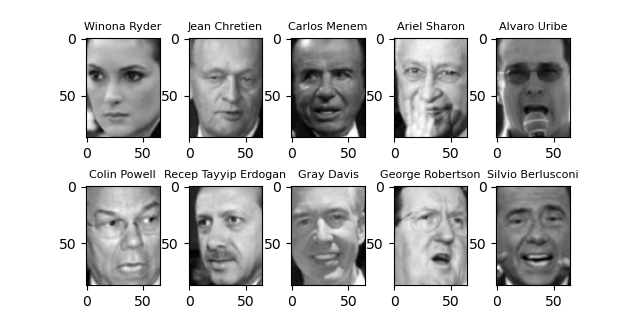
人物の並びは原著どおりだが、それぞれの顔画像が異なっている。著書執筆後にデータが追加/更新されたようだ。
データの俯瞰
全体の画像データを、1人あたりの枚数ごとに集計してみる。
多くの人について顔画像が1つだけで、George Bush元大統領の顔画像が飛びぬけて多いようだ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
df = pd.DataFrame() df['name'] = ds.target_names df['counts'] = np.bincount(ds.target) print(df.sort_values('counts')) # name counts # 0 AJ Cook 1 # 3518 Marina Canetti 1 # 3513 Marie-Josee Croze 1 # 3512 Marie Haghal 1 # 3511 Maribel Dominguez 1 # ... ... ... # 1892 Gerhard Schroeder 109 # 1404 Donald Rumsfeld 121 # 5458 Tony Blair 144 # 1047 Colin Powell 236 # 1871 George W Bush 530 # # [5749 rows x 2 columns] |
画像枚数ごとに人数を整理してみる。
そこで、顔画像の個数ごとに見た時の人数を確認してみる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
print(np.bincount(df['counts'])) # [ 0 4069 779 291 187 112 55 39 33 26 15 16 10 11 # 10 11 3 8 5 7 5 4 5 3 3 1 2 1 # 2 2 2 2 3 3 0 1 1 1 0 2 0 2 # 2 0 1 0 0 0 1 1 0 0 2 1 0 1 # 0 0 0 0 1 0 0 0 0 0 0 0 0 0 # 0 1 0 0 0 0 0 1 0 0 0 0 0 0 # 0 0 0 0 0 0 0 0 0 0 0 0 0 0 # 0 0 0 0 0 0 0 0 0 0 0 1 0 0 # 0 0 0 0 0 0 0 0 0 1 0 0 0 0 # 0 0 0 0 0 0 0 0 0 0 0 0 0 0 # 0 0 0 0 1 0 0 0 0 0 0 0 0 0 # 0 0 0 0 0 0 0 0 0 0 0 0 0 0 # 0 0 0 0 0 0 0 0 0 0 0 0 0 0 # 0 0 0 0 0 0 0 0 0 0 0 0 0 0 # 0 0 0 0 0 0 0 0 0 0 0 0 0 0 # 0 0 0 0 0 0 0 0 0 0 0 0 0 0 # 0 0 0 0 0 0 0 0 0 0 0 0 1 0 # 0 0 0 0 0 0 0 0 0 0 0 0 0 0 # # .....この間はすべてゼロ # # 0 0 0 0 0 0 0 0 0 0 0 0 0 0 # 0 0 0 0 0 0 0 0 0 0 0 0 1] |
上の配列は0~530の531個の要素の1次元配列で、インデックスが画像枚数、要素の値はそのインデックスの枚数の画像データがある人の数。
顔画像が1枚の人数が4千人以上と、ほとんどの人物については顔画像が1枚しかない。そして画像枚数2枚以降の人物の数が減っていっている。
読み込みパラメーター
resize~画像のサイズ変更(再読み込みされる)
fetch_lfw_people()のresize引数で、画像データのサイズを指定できる。
デフォルトは0.5でこの時のサイズは62×47、書籍”Pythonではじめる機械学習”ではresize=0.7を指定していて、この時のサイズは87×65になる。
自分のマシンでは、resize=1.0とするとメモリーの制約なのかエラーになった。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from sklearn.datasets import fetch_lfw_people ds = fetch_lfw_people() print(ds.target_names.size) print(ds.target.size) print(ds.images.shape) # 5749 # 13233 # (13233, 62, 47) ds = fetch_lfw_people(resize=0.7) print(ds.target_names.size) print(ds.target.size) print(ds.images.shape) # 5749 # 13233 # (13233, 87, 65) |
min_faces_per_person~1人あたりの最低画像数
分析の目的によって、1人あたりの画像が複数必要な場合に、最低限登録されている画像数を指定する。
ここで指定した数以上の画像が登録されている人物とその画像データのみ抽出される。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
from sklearn.datasets import fetch_lfw_people ds = fetch_lfw_people(min_faces_per_person=0, resize=0.7) print(ds.target_names.size) print(ds.target.size) print(ds.images.shape) # 5749 # 13233 # (13233, 87, 65) ds = fetch_lfw_people(min_faces_per_person=20, resize=0.7) print(ds.target_names.size) print(ds.target.size) print(ds.images.shape) # 62 # 3023 # (3023, 87, 65) ds = fetch_lfw_people(min_faces_per_person=100, resize=0.7) print(ds.target_names.size) print(ds.target.size) print(ds.images.shape) # 5 # 1140 # (1140, 87, 65) |