概要
2次元のndarrayやDataFrameで、行単位や列単位での合計を計算したり、それを使って行単位/列単位の率を計算する方法。
2次元のndarrayの場合は、
- 合計は
sum()メソッドの引数にaxisを指定- 列和なら
axis=0、行和ならaxis=1 - 結果は1次元配列で得られる
- 列和なら
- 率の計算はこれらの合計の配列を使うが、列和に対する各列要素の率なら1次元配列の行ベクトルのまま、行和に対する各行要素の率なら2次元の列ベクトルに変換して除算
DataFrameの場合、まず合計を求めるには、
- 合計は
sum()メソッドの引数にaxisを指定- 列和なら
axis=0、行和ならaxis=1 - 結果は
Seriesオブジェクトで得られる
- 列和なら
その上で率の計算には2通りある。1つ目はSeriesオブジェクトの内容をndarrayとして取り出して計算する方法で、
Series.valuesで列和/行和の配列を取り出し、ndarrayの場合と同じ方法で計算する
もう1つの方法はSeriesオブジェクトのままでdiv()メソッドにaxisを指定する方法で、
- 列和に対する各列要素の率を計算するには、
div(列和Series, axis=1) - 行和に対する各行要素の率を計算するには、
div(列和Series, axis=0)
ndarrayの場合
確認
まず確認のために、以下の配列を準備する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import numpy as np a = np.arange(1, 10).reshape(3, 3) vrow = np.arange(1, 4) vcol = np.arange(1, 4).reshape(-1, 1) print(a) # [[1 2 3] # [4 5 6] # [7 8 9]] print(vrow) # [1 2 3] print(vcol) # [[1] # [2] # [3]] # ] |
行ベクトルを2次元配列に加えると、配列の各行に対して行ベクトルが加えらえる。
|
1 2 3 4 5 |
print(a + vrow) # [[ 2 4 6] # [ 5 7 9] # [ 8 10 12]] |
列ベクトルを2次元配列に加えると、配列の各列に対して列ベクトルが加えられる。
|
1 2 3 4 5 |
print(a + vcol) # [[ 2 3 4] # [ 6 7 8] # [10 11 12]] |
つまり、ndarrayの2次元配列に行または列のベクトルを加えると、加える方のベクトルの形状に合わせて各行/列に演算が実行される。これは他のオペレーターについても同じ。
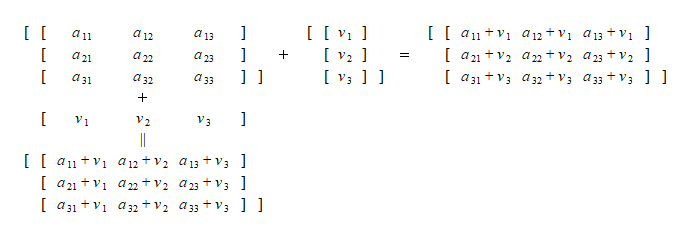
この演算は直感的にも分かりやすく、列ごと/行ごとの小計に対する比率の計算も思い浮かべることができる。
合計
ndarrayの各列/行に沿った合計を計算する。合計計算はndarrayのsum()メソッドを使うが、引数を省略すると全要素の和となる。引数にaxis=0を指定すると列方向に処理がされ(つまり配列の各列の要素が列方向に足され)、axis=1を指定すると行方向に処理がされる(つまり配列の各行の要素が行方向に足される)。
以下の例は、最初に使った2次元配列の列方向の和(の行ベクトル)と行方向の和(の列ベクトル)を計算している。
|
1 2 3 4 5 6 7 8 9 10 |
sums_along_cols = a.sum(axis=0) sums_along_rows = a.sum(axis=1).reshape(-1, 1) print(sums_along_cols) # [12 15 18] print(sums_along_rows) # [[ 6] # [15] # [24]] |
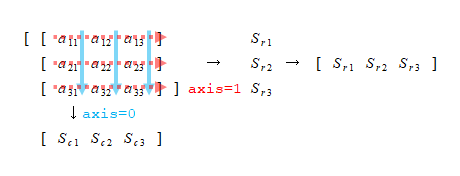
率の計算
2次元配列を行合計ベクトルで割ると、各行の要素が合計ベクトルの各要素で割られる(各列の行要素の合計は1になる)。
|
1 2 3 4 5 6 7 8 9 10 |
print(a / sums_along_cols) # [[0.08333333 0.13333333 0.16666667] # [0.33333333 0.33333333 0.33333333] # [0.58333333 0.53333333 0.5 ]] # NOTE # 1/12 2/15 3/18 # 4/12 5/15 6/18 # 7/12 8/15 9/18 |
また、2次元配列を列合計ベクトルで割ると、各列の要素が合計ベクトルの各要素で割られる。繰り返しになるが、この場合の合計ベクトルは2次元の列ベクトルになっている。
|
1 2 3 4 5 6 7 8 9 10 |
print(a / sums_along_rows) # [[0.16666667 0.33333333 0.5 ] # [0.26666667 0.33333333 0.4 ] # [0.29166667 0.33333333 0.375 ]] # NOTE # 1/6 2/6 3/6 # 4/15 5/15 6/15 # 7/24 8/24 9/24 |
以下の図のように、この
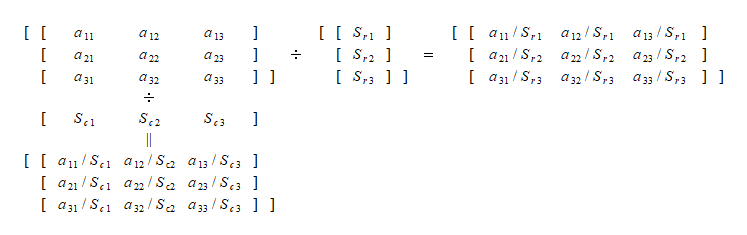
DataFrameの場合
確認
まず確認のために、以下のDataFrameとSeriesを準備する。2次元配列はndarrayの例と同じものを流用。
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd df = pd.DataFrame(a) sr = pd.Series(np.arange(1, 4)) print(df) # 0 1 2 # 0 1 2 3 # 1 4 5 6 # 2 7 8 9 |
合計ベクトルがndarrayの場合
演算をほどこすベクトルがndarrayの場合、2次元配列の時と同じように、ベクトルが行/列によって自動的に加えられる方向が決められる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
vrow = np.arange(1, 4) vcol = np.arange(1, 4).reshape(-1, 1) print(vrow) # [1 2 3] print(vcol) # [[1] # [2] # [3]] print(df + vrow) # 0 1 2 # 0 2 4 6 # 1 5 7 9 # 2 8 10 12 print(df + vcol) # 0 1 2 # 0 2 3 4 # 1 6 7 8 # 2 10 11 12 |
合計ベクトルがSeriesの場合
DataFrameのsum()メソッドで行や列の合計を計算するとSeriesオブジェクトで結果が得られるため、その挙動を確認しておく。
|
1 2 3 4 5 6 7 |
sr = pd.Series(np.arange(1, 4)) print(sr) 0 1 1 2 2 3 dtype: int32 |
Seriesを単純にDataFrameと演算子で結ぶと、行ベクトルとして扱われる。
|
1 2 3 4 5 6 |
print(df + sr) # 0 1 2 # 0 2 4 6 # 1 5 7 9 # 2 8 10 12 |
Seriesは行・列の概念を持たないが、演算の方向を明示するのに以下の方法をとる。
- 演算子の代わりに演算メソッドを使う
- 演算メソッドの引数
axisで演算の方向を指定する
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
print(df.add(sr, axis=0)) # 0 1 2 # 0 2 3 4 # 1 6 7 8 # 2 10 11 12 print(df.add(sr, axis=1)) # 0 1 2 # 0 2 4 6 # 1 5 7 9 # 2 8 10 12 |
演算子に対応するメソッドは、add、sub、mul、div、mod、powが準備されている。
合計
列/行ごとの合計は、ndarrayと同じくDataFrameのsum()メソッドで引数axisを指定して計算する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
sums_along_cols = df.sum(axis=0) sums_along_rows = df.sum(axis=1) print(sums_along_cols) # 0 12 # 1 15 # 2 18 # dtype: int64 print(sums_along_rows) # 0 6 # 1 15 # 2 24 # dtype: int64 |
率の計算
Seriesをndarrayで取り出して計算する方法
Seriesのvaluesプロパティーでその内容をndarrayとして取り出せる。
列和に対しては、それを行ベクトルのまま除算すれば、各列の要素を行ベクトルの対応する要素で割った値となる。
|
1 2 3 4 5 6 |
print(df / sums_along_cols.values) # 0 1 2 # 0 0.083333 0.133333 0.166667 # 1 0.333333 0.333333 0.333333 # 2 0.583333 0.533333 0.500000 |
行和に対しては、ndarrayを1列の列ベクトルに変換して除算すれば、各行の要素を列ベクトルの対応する要素で割った値となる。
|
1 2 3 4 5 6 |
print(df / sums_along_rows.values.reshape(-1, 1)) # 0 1 2 # 0 0.166667 0.333333 0.500 # 1 0.266667 0.333333 0.400 # 2 0.291667 0.333333 0.375 |
Seriesのままで計算する方法
合計Seriesをそのまま使って除算する場合はDataFrameのdiv()メソッドを使いaxisを指定するが、axisの指定の仕方に注意が必要。
列和で除算する場合は、その各要素が各行の各要素に対応するため、列和を行ベクトルとみて各行に除算を適用する(axis=1)。
|
1 2 3 4 5 6 |
print(df.div(sums_along_cols, axis=1)) # 0 1 2 # 0 0.083333 0.133333 0.166667 # 1 0.333333 0.333333 0.333333 # 2 0.583333 0.533333 0.500000 |
分かりにくいので図示すると以下のようになる。まず合計を求めるのにsum()メソッドでaxis=0として列和を求める。この合計で各要素を割るのに1列目の要素は合計の1つ目の要素、2列目の要素は合計の2つ目の要素・・・で割る必要があるので、div()メソッドでaxis=1とする。こうすると合計のSeriesは行ベクトルとみなされて、それが各行の要素に適用される。

行和で除算する場合は、その各要素が各列の各要素に対応するため、行和を列ベクトルとみて各列に除算を適用する(axis=0)。
|
1 2 3 4 5 6 |
print(df.div(sums_along_rows, axis=0)) # 0 1 2 # 0 0.166667 0.333333 0.500 # 1 0.266667 0.333333 0.400 # 2 0.291667 0.333333 0.375 |
これも分かりにくいので以下のように図示する。合計を求めるのにsum()メソッドでaxis=1として行和を求める。この合計で各要素を割るのに1行目の要素は合計の1つ目の要素、2行目の要素は合計の2つ目の要素・・・で割る必要があるので、div()メソッドでaxis=1とする。こうすると合計のSeriesは列ベクトルとみなされて、それが各列の要素に適用される。
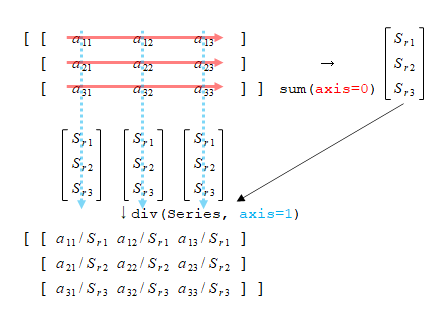
このように、div()のような演算子メソッドでaxisを使う方法はややこしい(少なくとも私には)。
実行速度
各計算方法の実行速度には、あまり大きな差は出なかった。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
import numpy as np import pandas as pd import time counter = 100 a = np.arange(1000000).reshape(1000, 1000) df = pd.DataFrame(a) sum_of_cols = df.sum(axis=0) sum_of_rows = df.sum(axis=1) t0 = time.time() for n in range(counter): df.values / sum_of_cols.values t_array_c = time.time() print(t_array_c - t0) for n in range(counter): df.values / sum_of_rows.values.reshape(-1, 1) t_array_r = time.time() print(t_array_r - t_array_c) for n in range(counter): df / sum_of_cols.values t_df_array_c = time.time() print(t_df_array_c - t_array_r) for n in range(counter): df / sum_of_rows.values.reshape(-1, 1) t_df_array_r = time.time() print(t_df_array_r - t_df_array_c) for n in range(counter): df.div(sum_of_cols, axis=1) t_df_div_c = time.time() print(t_df_div_c - t_df_array_r) for n in range(counter): df.div(sum_of_rows, axis=0) t_df_div_r = time.time() print(t_df_div_r - t_df_div_c) |
実行時間は以下の通りで、各計算手法の間に差はない。敢えて言えば、DataFrameを使った場合に僅かに時間がかかっている。
|
1 2 3 4 5 6 |
0.4757249355316162 0.4577751159667969 0.524827241897583 0.5440847873687744 0.5674364566802979 0.5242717266082764 |
なお、この計算はpandasのバージョン1.1.4で実行したが、upgrade前のバージョン0では、3つ目と5つ目、DataFrameで行単位の演算を行うときに20秒台と2桁長い時間がかかっていた。