ArtistAnimationの場合
ArtistAnimationにグラフを追加するには、たとえばplotメソッドの戻り値をそのままリストに追加していけばよい。
|
1 2 3 4 5 6 7 8 9 10 |
artists = [] fig, ax = plt.subplots() frame_count = 20 for i in range(frame_count): x = np.linspace(0, 4 * np.pi) y = np.sin(x - 2 * np.pi / frame_count * i) artist = ax.plot(x, y, color='blue') artists.append(artist) anim = ArtistAnimation(fig, artists, interval=100) plt.show() |
ところが、matplotlib.patchesの図形の場合に同じようにすると、アニメーションにならず全フレームの図形が重ね書きされてしまう。
|
1 2 3 4 5 6 |
for i in range(frame_count): circle = patch.Circle(xy=(i, 0), radius=1.0) artist_patch = ax.add_artist(circle) artists.append(artist_patch) anim = ArtistAnimation(fig, artists, interval=100) plt.show() |
これを解決するには、appendの際に[]で囲んでリスト化する必要がある。
|
1 2 3 4 5 6 |
for i in range(frame_count): circle = patch.Circle(xy=(i, 0), radius=1.0) artist_patch = ax.add_artist(circle) artists.append([artist_patch]) anim = ArtistAnimation(fig, artists, interval=100) plt.show() |
以下は円の図形のアニメーションのコード例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as patch from matplotlib.animation import ArtistAnimation # 各フレームを保存するフレームリスト artists = [] # FigureとAxesインスタンスを取得 fig, ax = plt.subplots() ax.set_aspect('equal') ax.set_xlim(0, 20) ax.set_ylim(-1, 1) # 1サイクルの動画のフレーム数 frame_count = 20 # 表示する各フレームの生成・保存 for i in range(frame_count): # 図形の生成 circle = patch.Circle(xy=(i, 0), radius=1.0) # artist要素の取得 artist_patch = ax.add_artist(circle) # フレームリストへの追加 # 明示的にリスト化しないと要素追加となり、一括で描画されてしまう artists.append([artist_patch]) # フレームリストを渡してArtistAnimationインスタンスを生成 anim = ArtistAnimation(fig, artists, interval=100) # 表示 plt.show() |
実行結果は以下の通り。
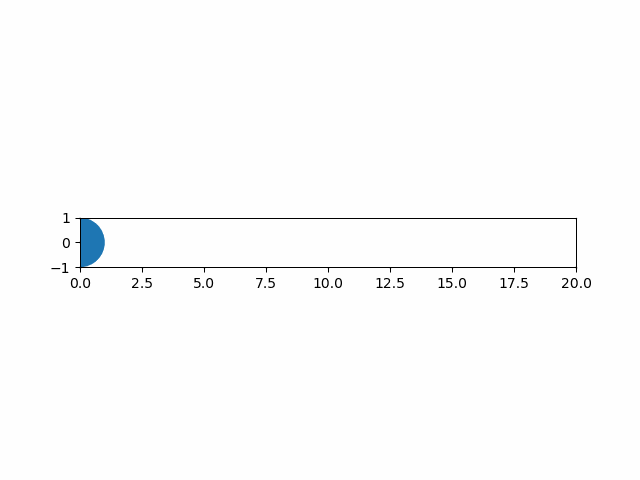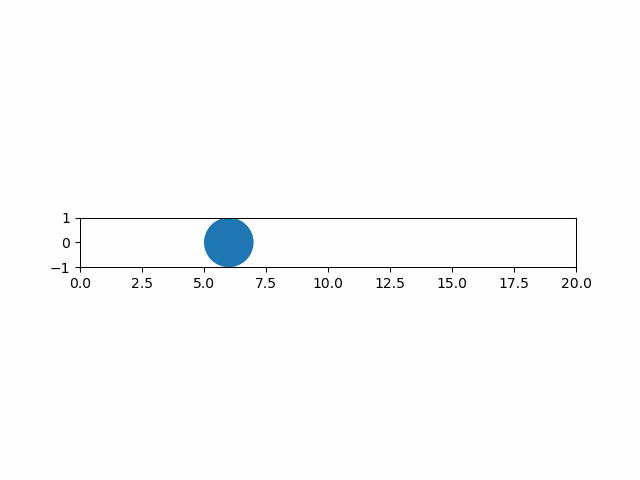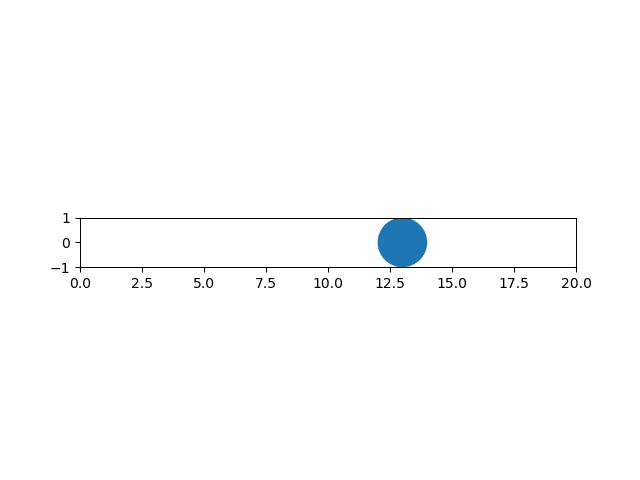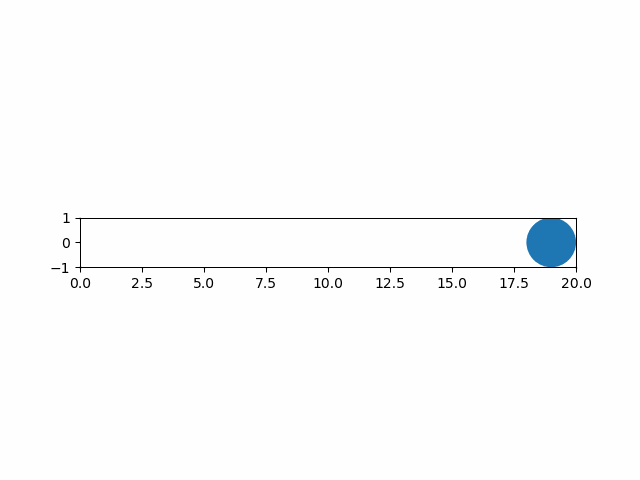
グラフと図形の重ね合わせ
グラフと図形を重ね合わせるときも、patchesの図形を明示的にリストとしてappendする必要がある。
|
1 2 3 4 5 |
for i in range(frame_count): artist_graph = ax.plot([0, i], [0, 0], color='blue') circle = patch.Circle(xy=(i, 0), radius=1.0) artist_patch = ax.add_artist(circle) artists.append(artist_graph + [artist_patch]) |
以下は、plotによる線とpatches.Circleによる円を重ねて描く例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as patch from matplotlib.animation import ArtistAnimation # 各フレームを保存するフレームリスト artists = [] # FigureとAxesインスタンスを取得 fig, ax = plt.subplots() ax.set_aspect('equal') ax.set_xlim(0, 20) ax.set_ylim(-1, 1) # 1サイクルの動画のフレーム数 frame_count = 20 # 表示する各フレームの生成・保存 for i in range(frame_count): # グラフのartist取得 artist_graph = ax.plot([0, i], [0, 0], color='blue') # 図形の生成 circle = patch.Circle(xy=(i, 0), radius=1.0) # artist要素の取得 artist_patch = ax.add_artist(circle) # フレームリストへの追加 # 図形は明示的にリスト化しないと要素追加となり、一括で描画されてしまう artists.append(artist_graph + [artist_patch]) # フレームリストを渡してArtistAnimationインスタンスを生成 anim = ArtistAnimation(fig, artists, interval=100) # 表示 plt.show() |
実行結果は以下の通り。
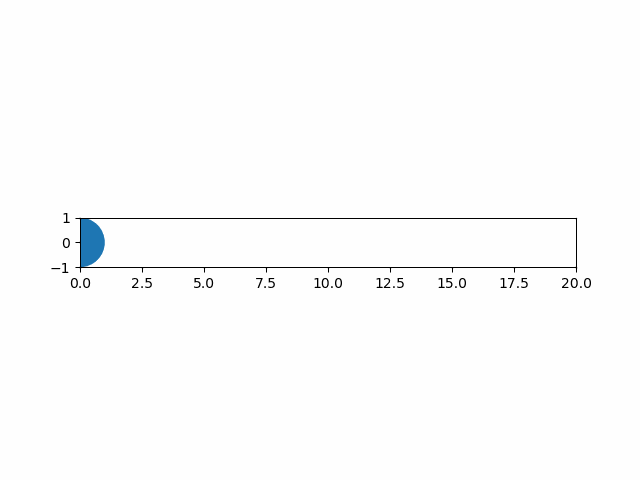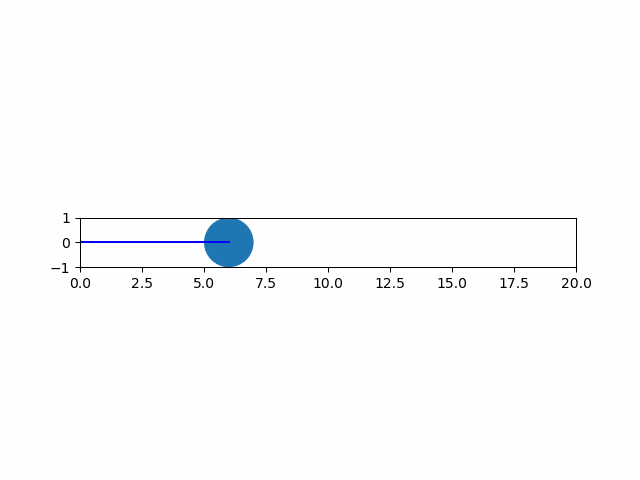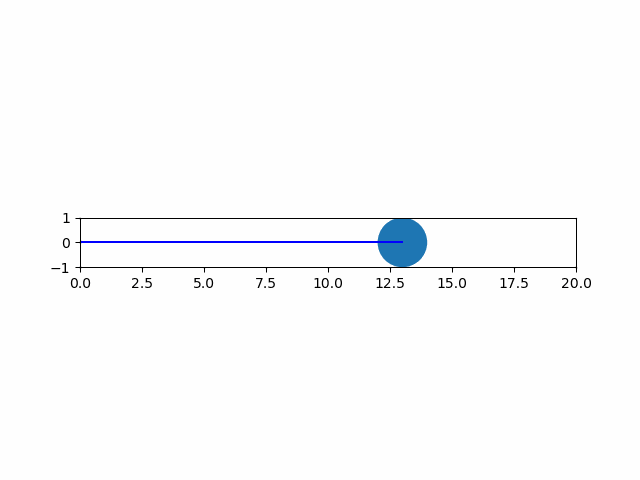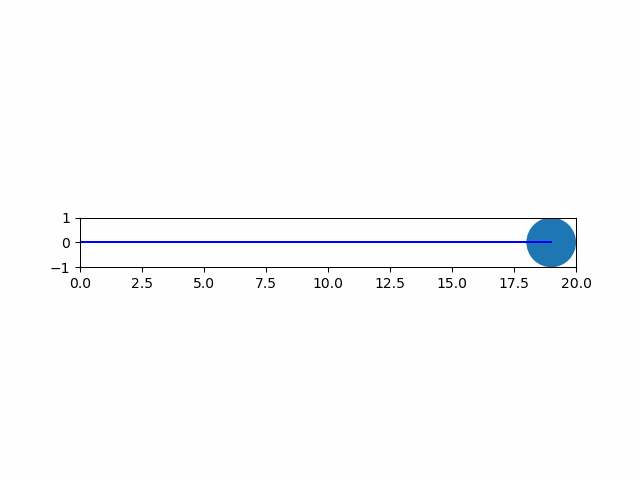
FuncAnimationの場合
FuncAnimationの場合は描画関数中でグラフを描くだけで、ArtistAnimationのようなコレクションを用いない。
この場合はArtistAnimationより簡明で、グラフはAxesオブジェクトなどに描画、図形はadd_artistメソッドで追加するだけ。
|
1 2 3 4 5 6 7 8 9 |
def draw_frame(frame): plt.cla() ax.set_aspect('equal') ax.set_xlim(0, 20) ax.set_ylim(-1, 1) ax.plot([0, frame], [0, 0], color='blue') circle = patch.Circle(xy=(frame, 0), radius=1.0) ax.add_artist(circle) anim = FuncAnimation(fig, draw_frame, interval=100, frames=20) |
以下はArtistAnimationと同じく、plotによる線とpatches.Circleによる円を重ね牡蠣する例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as patch from matplotlib.animation import FuncAnimation # 各フレームを保存するフレームリスト artists = [] # FigureとAxesインスタンスを取得 fig, ax = plt.subplots() def draw_frame(frame): # FuncAnimationの場合はフレームごとに内容をクリア plt.cla() # Axesに対する設定もクリアされるので、毎回設定が必要 ax.set_aspect('equal') ax.set_xlim(0, 20) ax.set_ylim(-1, 1) # グラフの描画 ax.plot([0, frame], [0, 0], color='blue') # 図形の生成 circle = patch.Circle(xy=(frame, 0), radius=1.0) # 図形の追加 ax.add_artist(circle) # 描画関数を渡してFuncAnimationインスタンスを生成 anim = FuncAnimation(fig, draw_frame, interval=100, frames=20) # 表示 plt.show() |