概要
配列などのメソッドの引数で指定するaxis=0/1について確認。
axis=0は配列やDataFrameを列単位で捉えて、その列の中で処理を行いながら、すべての列に対して処理が行われるSerieseオブジェクトがDataFrameの処理の対象となる場合は列として扱われ、DataFrameの各列を処理しながらすべての列に適用される
axis=1は配列やDataFrameを行単位で捉えて、その行の中で処理を行いながら、すべての行に対して処理が行われる。SerieseオブジェクトがDataFrameの処理の対象となる場合は行として扱われ、DataFrameの各行を処理しながらすべての行に適用される
ndarrayの場合
まずndarrayの2次元配列で確認する。
|
1 2 3 4 5 |
ary = np.arange(1, 7).reshape(2, 3) print(ary) # [[1 2 3] # [4 5 6]] |
max()メソッド
axis=0は列単位で各列の最大値を探し、それらを要素とする配列(要素数=列数の1次元配列)axis=1は行単位で各行の最大値を探し、それらを要素とする配列(要素数=行数の1次元配列)
|
1 2 3 4 5 |
print(ary.max(axis=0)) # [4 5 6] print(ary.max(axis=1)) # [3 6] |
sum()メソッド
axis=0は列単位で各列の合計を要素とする配列(要素数=列数の1次元配列)axis=1は行単位で各行の合計を要素とする配列(要素数=行数の1次元配列)
|
1 2 3 4 5 |
print(ary.sum(axis=0)) # [5 7 9] print(ary.sum(axis=1)) # [ 6 15] |
repeat()メソッド
axis=0は列単位で各列の要素が指定回数繰り返されるaxis=1は行単位で各行の要素が指定回数繰り返される
|
1 2 3 4 5 6 7 8 9 10 11 |
print(ary.repeat(2, axis=0)) # [[1 2 3] # [1 2 3] # [4 5 6] # [4 5 6]] print(ary.repeat(2, axis=1)) # [[1 1 2 2 3 3] # [4 4 5 5 6 6]] |
図による理解
sum()メソッドを例に、axis=0/1に対する挙動を図にすると、以下のようになる。
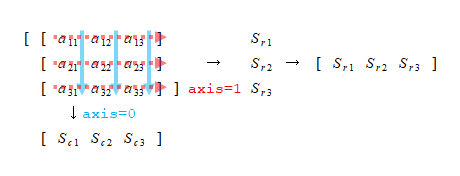
DataFrameの場合
以下のDataFrameとSeriesオブジェクトで確認する。Seriesオブジェクトは行として扱われ、array_like、1次元の配列でも同じ結果になる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
df = pd.DataFrame(np.arnge(1, 9).reshape(3, 3)) sr = pd.Series(np.arange(1, 3)) print(df) # 0 1 2 # 0 1 2 3 # 1 4 5 6 # 2 7 8 9 print(sr) # 0 1 # 1 2 # 2 3 # dtype: int32 |
min()メソッドなど
min、max、sumなどのメソッドの考え方はndarrayと同じ挙動。
add()などの演算メソッド
DataFrameには演算子による演算の代替となるメソッドがある(add、sub、mul、div、mod、pow)。addメソッドを例にとると、以下のように引数を指定。
add(array_like, axis=0/1)
axis=0はarray_likeを列とみなして、DataFrameオブジェクトの各列の要素との和を計算するaxis=1はarray_likeを行とみなして、DataFrameオブジェクトの各行の要素との和を計算する
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
print(df.add(sr, axis=0)) # 0 1 2 # 0 2 3 4 # 1 6 7 8 # 2 10 11 12 print(df.add(sr, axis=1)) # 0 1 2 # 0 2 4 6 # 1 5 7 9 # 2 8 10 12 |
apply()メソッド
applyメソッドは、行または列を指定した関数に渡す。
axis=0はDataFrameオブジェクトの各列を指定した関数に渡すaxis=1はDataFrameオブジェクトの各行を指定した関数に渡す
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
print(df.apply(lambda x: sum(x) / 3, axis=0)) # 0 4.0 # 1 5.0 # 2 6.0 # dtype: float64 print(df.apply(lambda x: sum(x) / 3, axis=1)) # 0 2.0 # 1 5.0 # 2 8.0 # dtype: float64 |
演算メソッドの図による理解
演算メソッドは少し挙動が違うので図で整理しておく。1次元のarray_likeオブジェクトがaxisの指定によって列/行としてみなされる点に注意。

補足
1次元配列の場合
1次元配列に対してaxis引数を使う場合、行ベクトルとしてaxis=1に反応しそうだが、実際にはaxis=0で各要素に対する処理が行われる。axis=1を指定すると、たとえば以下のようなエラーになる。
|
1 |
ary.min(axis=1)->numpy.AxisError: axis 1 is out of bounds for array of dimension 1 |
元々多次元配列を意図した引数なので、1次元配列に使うのはナンセンスだろう(axis=0を行単位の処理にしておけば自然ではあったかもしれないが)。
1行の2次元配列の場合
1行の配列(1つの1次元配列を要素に持つ2次元配列:行ベクトル)に対するaxisの効果を、sumメソッドで見てみる。
|
1 2 3 4 5 6 7 8 9 |
ary = np.arange(1, 4).reshape(1, -1) print(ary) # [[1 2 3]] print(ary.sum(axis=0)) # [1 2 3] print(ary.sum(axis=1)) # [6] |
axis=0の場合は各要素が1要素の列ベクトルとみなされ、3つの列(要素)ごとに処理される。その結果は3つの要素を持つ1次元配列(行ベクトル)となる。
axis=1の場合は行ベクトル全体が1つの行とみなされ、それらの要素に対して処理がされる。その結果は1つの数値となるが、1つの要素を持つ1次元配列で返される。
1列の2次元配列の場合
1列の配列(列ベクトル)に対するaxisの効果を、sumメソッドで見てみる。
|
1 2 3 4 5 6 7 8 9 10 11 |
ary = np.arange(1, 4).reshape(-1, 1) print(ary) # [[1] # [2] # [3]] print(ary.sum(axis=0)) # [6] print(ary.sum(axis=1)) # [1 2 3] |
axis=0の場合は3つの要素を持つ1つの列に対して処理される。その結果は1つの数値となるが、1つの要素を持つ1次元配列で返される。
axis=1の場合は列の各要素が1要素の行とみなされ、3つの行(要素)ごとに処理される。その結果は3つの要素を持つ列ベクトルだが、3つの要素を持つ1次元配列(行ベクトル)で返される。