概要
OneHotEncoderは、あるクラスデータの特徴量をエンコードする。LabelEncoderやOrdinalEncoderが特徴量内のクラスに一連の数値を振るのに対して、OneHotEncoderはクラスの数だけ列を確保し、データごとに該当するクラスのみに1を立てる。エンコードされたデータは、該当するクラスのみに反応するインデックス引数となる。
なお、DataFrameのget_dummis()メソッドでもone-hotエンコーディングができる。
使い方
fit()~インデックス列の生成
以下の例は、2つのクラス特徴量を持つ6個のデータセットをOneHotEncoderで変換。
sklearn.prreprocessingからOneHotEncoderをインポート- エンコーダーのインスタンスを生成
- デフォルトではスパース行列になるので、オプションで
sparse=Falseを指定
- デフォルトではスパース行列になるので、オプションで
fit()メソッドでデータをフィッティングし、変換器を準備- この段階で
categories_プロパティーには各特徴量ごとのインデックス構成がセットされる
以下の例では、1つ目の特徴量は3つのクラス、2つ目の特徴量は2つのクラスを持つので、3要素、2要素の配列を要素に持つリストがcategories_にセットされる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from sklearn.preprocessing import OneHotEncoder X = [ ["Tokyo", "Male"], ["Tokyo", "Female"], ["Osaka", "Male"], ["Kyoto", "Female"], ["Osaka", "Female"], ["Osaka", "Male"] ] ohe = OneHotEncoder(sparse=False) ohe.fit(X) print(ohe.categories_) print(ohe.categories_[0]) print(ohe.categories_[1]) # [array(['Kyoto', 'Osaka', 'Tokyo'], dtype=object), array(['Female', 'Male'], dtype=object)] # ['Kyoto' 'Osaka' 'Tokyo'] # ['Female' 'Male'] |
transform()~インデックスデータへの変換
fit()メソッドで準備された変換器によってデータを変換する。変換後のデータは特徴量のクラス数分の列を持つ2次元のndarrayで返される。なおfitとtransformを一度に行うfit_transform()メソッドも準備されている。
|
1 2 3 4 5 6 7 8 9 |
X_trans = ohe.transform(X) print(X_trans) # [[0. 0. 1. 0. 1.] # [0. 0. 1. 1. 0.] # [0. 1. 0. 0. 1.] # [1. 0. 0. 1. 0.] # [0. 1. 0. 1. 0.] # [0. 1. 0. 0. 1.]] |
出力の右3列は3つの都市、それに続く2列は性別に対応していて、たとえば1行目のデータの都市はcategories_[0]の3番目'Tokyo'、性別はcategories_[1]の2番目の'Male'であることがあらわされている。
DataFrameによる操作
OneHotEncoderはpandas.DataFrameも扱える。ただしtransfrom()やfit_transform()メソッドの戻り値はndarrayなので、以下の例ではこれをDataFrameの形にしている。このときcolumns引数にエンコーダーのインスタンスのcategories_プロパティーを使うと個別のクラス名まで打ち込まずに済んで便利。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import numpy as np from pandas import DataFrame df_X = DataFrame(X, columns=["city", "gender"]) X_trans = ohe.fit_transform(df_X) df_X_trans =DataFrame(X_trans, columns=np.append(ohe.categories_[0], ohe.categories_[1])) print(df_X) print() print(df_X_trans) # city gender # 0 Tokyo Male # 1 Tokyo Female # 2 Osaka Male # 3 Kyoto Female # 4 Osaka Female # 5 Osaka Male # # Kyoto Osaka Tokyo Female Male # 0 0.0 0.0 1.0 0.0 1.0 # 1 0.0 0.0 1.0 1.0 0.0 # 2 0.0 1.0 0.0 0.0 1.0 # 3 1.0 0.0 0.0 1.0 0.0 # 4 0.0 1.0 0.0 1.0 0.0 # 5 0.0 1.0 0.0 0.0 1.0 |
数値データとクラスデータが混在する場合
DataFrameの準備
以下の例では、2つのクラス特徴量と2つの数値特徴量を持つデータセットをDataFrameとして扱う。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import numpy as np from pandas import DataFrame from sklearn.preprocessing import OneHotEncoder X = [ ["Tokyo", 10000, "Male", 2], ["Tokyo", 8000, "Female", 1.5], ["Osaka", 9000, "Male", 1.5], ["Kyoto", 10000, "Female", 1], ["Osaka", 7000, "Female", 1], ["Osaka", 8000, "Male", 1.5] ] df_X = DataFrame(X, columns=["city", "hotel_charge", "gender", "travel_time"]) print(df_X) # city hotel_charge gender travel_time # 0 Tokyo 10000 Male 2.0 # 1 Tokyo 8000 Female 1.5 # 2 Osaka 9000 Male 1.5 # 3 Kyoto 10000 Female 1.0 # 4 Osaka 7000 Female 1.0 # 5 Osaka 8000 Male 1.5 |
クラスデータのヘッダーの準備
クラスデータを複数のインデックスデータの列にするための準備。
- 特徴量のうち、クラスデータのものと数値データのもののヘッダーを分けておく
- クラスデータ用の
DataFrameを準備して、元データからクラスデータの列だけを切り出し - エンコーダーを生成して
fit_trans()を実行 - 実行後にエンコーダーの
categories_に保持されているクラスリストを取得
このクラスリストが変換後のデータのヘッダーになる。
|
1 2 3 4 5 6 7 8 9 10 11 |
col_class = ["city", "gender"] col_num = ["hotel_charge", "travel_time"] df_X_class = df_X[col_class] ohe = OneHotEncoder(sparse=False) X_trans = ohe.fit_transform(df_X_class) col_class = [cls for ary in ohe.categories_ for cls in ary] print(col_class) # ['Kyoto', 'Osaka', 'Tokyo', 'Female', 'Male'] |
クラスデータと数値データの合体
以下の処理では、変換されたクラスデータ列と元の数値データ列を合わせて最終的なデータセットとしている
- クラスリストをヘッダーとして、変換後のクラスデータ(
ndarray)をDataFrameとして読み込み - 上記
DataFrameに元データの数値データを追加
この処理によって元データセットから特徴量の順番が変わるが、学習過程で特徴量の順番は影響しない。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
df_X_class_trans = DataFrame(X_trans, columns=col_class_trans) print(df_X_class_trans) # Kyoto Osaka Tokyo Female Male # 0 0.0 0.0 1.0 0.0 1.0 # 1 0.0 0.0 1.0 1.0 0.0 # 2 0.0 1.0 0.0 0.0 1.0 # 3 1.0 0.0 0.0 1.0 0.0 # 4 0.0 1.0 0.0 1.0 0.0 # 5 0.0 1.0 0.0 0.0 1.0 df_X_trans = df_X_class_trans.copy() df_X_trans[col_num] = df_X[col_num] print(df_X_trans) # Kyoto Osaka Tokyo Female Male hotel_charge travel_time # 0 0.0 0.0 1.0 0.0 1.0 10000 2.0 # 1 0.0 0.0 1.0 1.0 0.0 8000 1.5 # 2 0.0 1.0 0.0 0.0 1.0 9000 1.5 # 3 1.0 0.0 0.0 1.0 0.0 10000 1.0 # 4 0.0 1.0 0.0 1.0 0.0 7000 1.0 # 5 0.0 1.0 0.0 0.0 1.0 8000 1.5 |
inverse_transform()
上でdf_X_trans = df_X_class_trans.copy()としたので、df_X_class_transは保存されている。このデータをエンコーダーのinverse_transform()に与えると、複数列で表現されていたクラスが元の表現で得られる。
|
1 2 3 4 5 6 7 8 |
print(ohe.inverse_transform(df_X_class_trans)) # [['Tokyo' 'Male'] # ['Tokyo' 'Female'] # ['Osaka' 'Male'] # ['Kyoto' 'Female'] # ['Osaka' 'Female'] # ['Osaka' 'Male']] |
新しいデータの変換
訓練済みモデルにデータを与えて予測する場合、前処理のエンコーディングでは、フィッティング済みのエンコーダーに新しいデータを与えて変換する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
x = [["Kyoto", 7000, "Male", 0.5]] df_X = DataFrame(x, columns=col_original) print(df_X) # city hotel_charge gender travel_time # 0 Kyoto 7000 Male 0.5 df_X_class = df_X[col_class] X_trans = ohe.transform(df_X_class) df_X_trans = DataFrame(X_trans, columns=col_class_trans) df_X_trans[col_num] = df_X[col_num] print(df_X_trans) # Kyoto Osaka Tokyo Female Male hotel_charge travel_time # 0 1.0 0.0 0.0 0.0 1.0 7000 0.5 |
未知のクラスへの対処
フィッティング時になかったクラスに遭遇した場合の動作は、エンコーダーのインスタンス生成時に指定する。
OneHotEncoder(handle_unknown='error'/'ignore')
デフォルトは'error'で、未知のクラスに遭遇するとエラーを投げる。'ignore'を指定すると未知のクラスの場合はその特徴量のすべてのクラスラベルが0になる。
以下の例では、2行目のデータにフィッティングでは含まれていなかった”Nagoya”があるため、変換後のデータの2行目の1~3列が0となっている。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
df_X = DataFrame(X, columns=col_original) df_X_class = df_X[col_class] ohe = OneHotEncoder(sparse=False, handle_unknown='ignore') ohe.fit(df_X_class) x = [ ["Kyoto", 9000, "Female", 1], ["Nagoya", 7000, "Male", 0.5] ] df_X = DataFrame(x, columns=col_original) df_X_class = df_X[col_class] print(df_X_class) # city gender # 0 Kyoto Female # 1 Nagoya Male X_class_trans = ohe.transform(df_X_class) print(X_class_trans) # [[1. 0. 0. 1. 0.] # [0. 0. 0. 0. 1.]] df_X_trans = DataFrame(X_class_trans, columns=col_class_trans) df_X_trans[col_num] = df_X[col_num] print(df_X_trans) # Kyoto Osaka Tokyo Female Male hotel_charge travel_time # 0 1.0 0.0 0.0 1.0 0.0 9000 1.0 # 1 0.0 0.0 0.0 0.0 1.0 7000 0.5 |
この変換データをinverse_transform()で逆変換すると、未知のクラスであったところは'None'に変換される。
|
1 2 3 4 |
print(ohe.inverse_transform(X_class_trans)) # [['Kyoto' 'Female'] # [None 'Male']] |





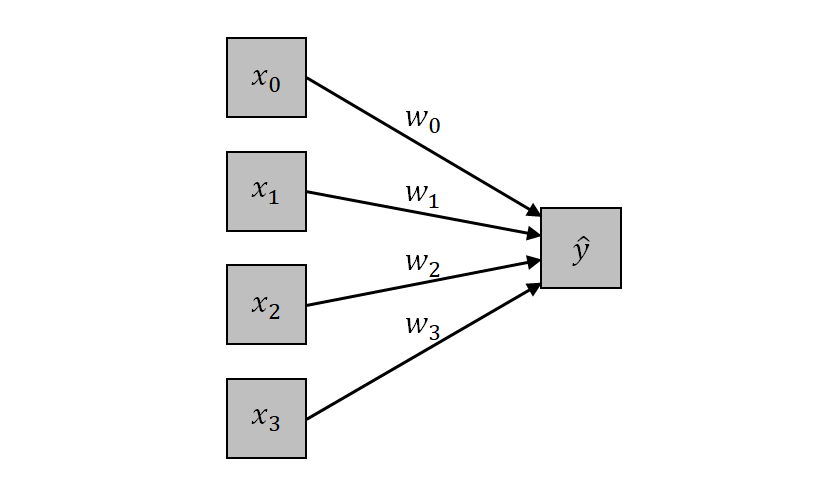
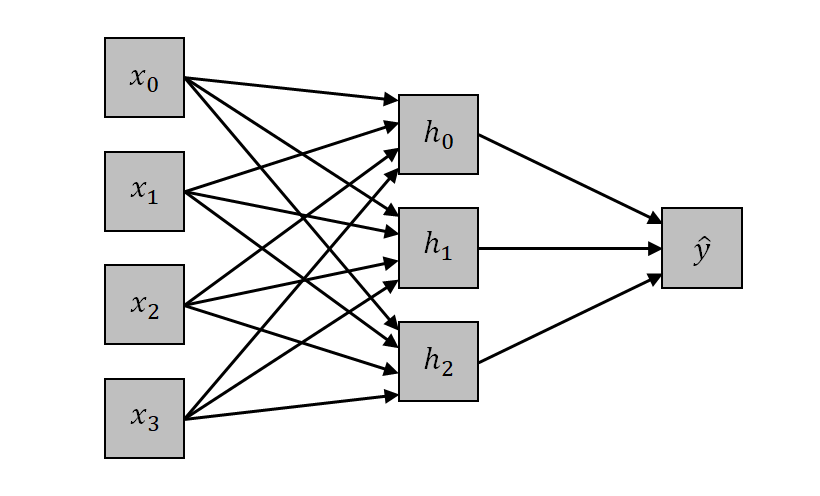

 に対する重みをvj、切片をcとすると、出力への重み付き線形和は以下のようになる。
に対する重みをvj、切片をcとすると、出力への重み付き線形和は以下のようになる。