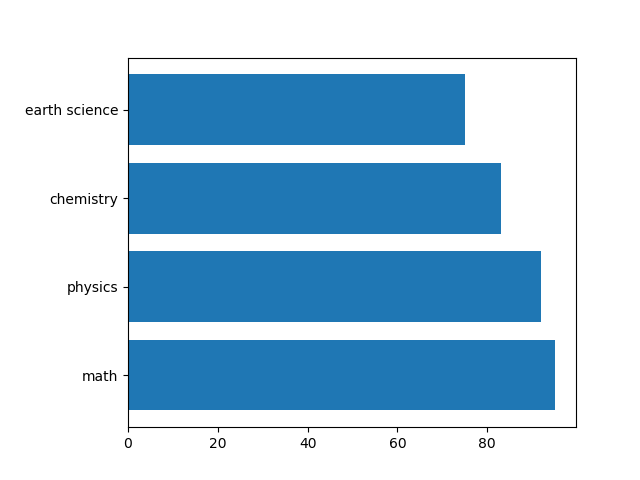概要
barh()は横棒グラフを描く。主要なパラメーターは以下の通り。
barh(y, width, height, left, align, fc, ec, linewidth, xerr, capsize, log)
y, width, heightyは縦方向の座標で棒グラフのラベルをリスト等で指定するのが一般的。widthは棒の長さでこれもリスト等で指定。heightは棒の太さでデフォルトは0.8だが数値/リスト等で指定可。alignalignはデフォルトで'center'だが、'edge'を指定すると棒の下側がラベルに合わせられる。上を合わせるにはheightに負の値を指定する。fc, ec, linewidthfc/colorは棒の塗りつぶし色、ec/edgecolorは縁の色、linewidthは縁の太さxerr, capsizexerrは誤差の範囲でリスト等で指定。capsizeは誤差範囲の両端の直交線の長さ。loglog=Trueを指定すると横軸が対数スケールになる。
実行例
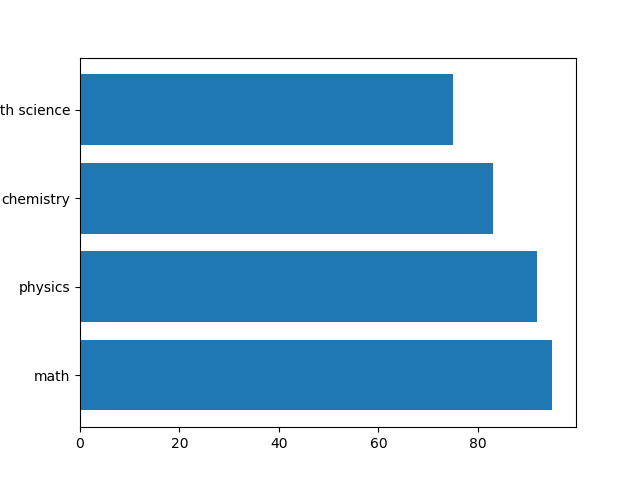
基本形
基本的な使い方で、第1引数yに縦軸のラベル、第2引数widthに各棒の長さをそれぞれリストで与える。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import numpy as np import matplotlib.pyplot as plt subjects = np.array(["math", "physics", "chemistry", "earth science"]) scores = np.array([80, 95, 45, 65]) fig, ax = plt.subplots() fig.subplots_adjust(left=0.2) ax.barh(subjects, scores) plt.show() |
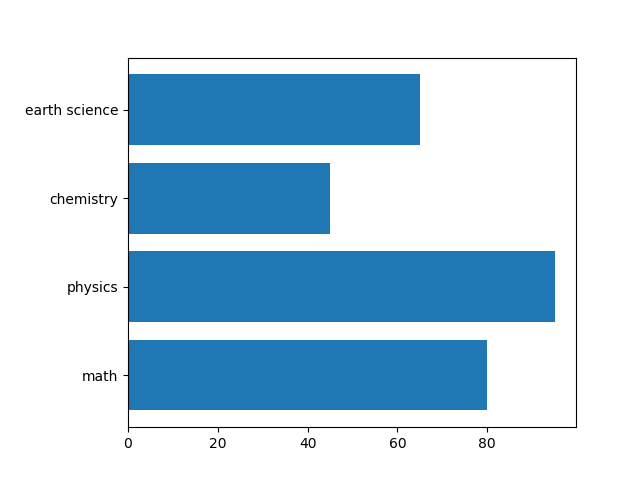
色・枠線の指定
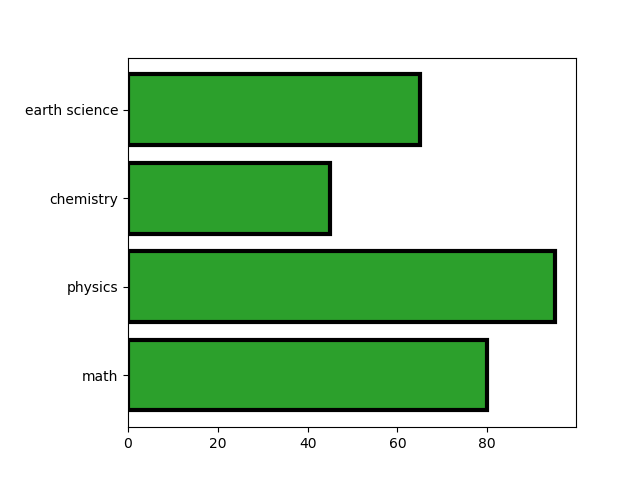
棒の塗りつぶし色と枠線の色・太さを指定。
|
1 |
ax.barh(subjects, scores, fc='tab:green', ec='k', linewidth=3) |
高さ・位置
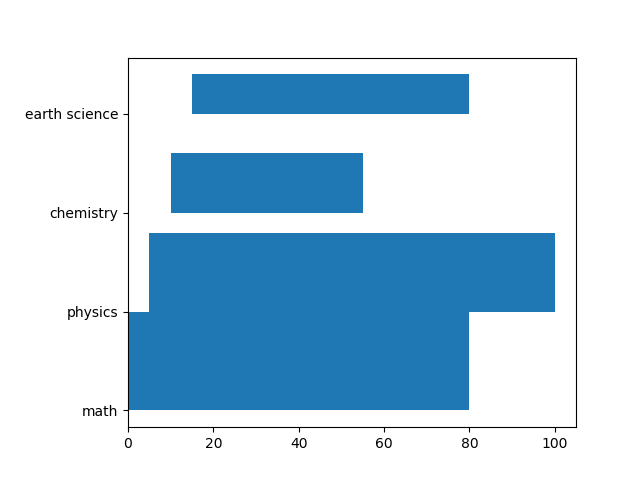
棒の高さ、開始位置を指定し、ラベルに対して棒の下端を合わせている。
|
1 2 3 |
heights = [1, 0.8, 0.6, 0.4] lefts = [0, 5, 10, 15] ax.barh(subjects, scores, height=heights, left=lefts, align='edge') |
誤差
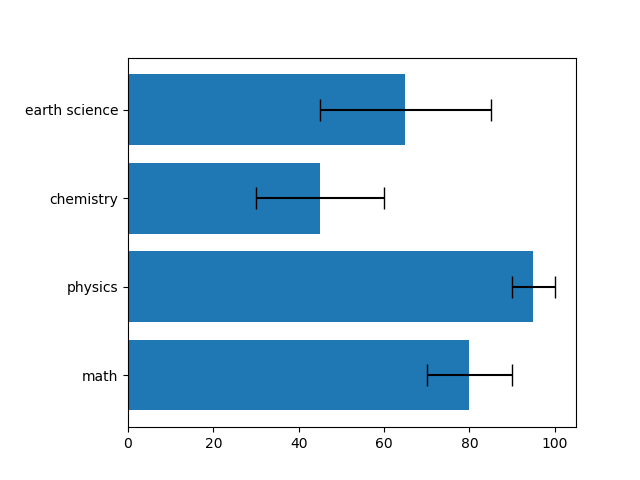
棒の端に誤差範囲を表示。
|
1 |
ax.barh(subjects, scores, xerr=xerr, capsize=8) |
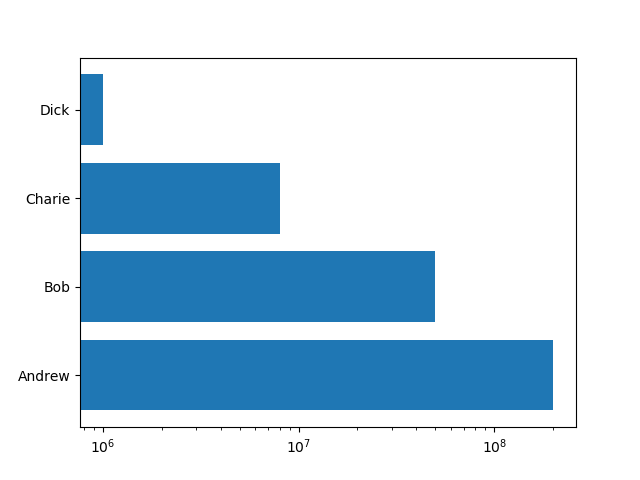
対数軸
横軸を対数軸としている。
|
1 2 3 4 5 6 7 8 9 10 |
import matplotlib.pyplot as plt names = ["Andrew", "Bob", "Charie", "Dick"] properties = [200000000, 50000000, 8000000, 1000000] fig, ax = plt.subplots() ax.barh(names, properties, log=True) plt.show() |