概要
Boston house-pricesデータセットは、カーネギーメロン大学のStatLibライブラリーから取得したもので、持家の価格とその持家が属する地域に関する指標からなる。
ボストンの各地域にある506の持家の価格の中央値に対して、その地域の犯罪発生率やNOx濃度など13の指標が得られる。
ここではPythonのscikit-learnにあるbostonデータの使い方をまとめる。
データの取得とデータ構造
Pythonで扱う場合、scikit-learnのdatasetsモジュールにあるload_breast_cancer()でデータを取得できる。データはBunchクラスのオブジェクト。
|
1 2 3 4 5 6 |
from sklearn.datasets import load_boston boston_ds = load_boston() for key, value in zip(boston_ds.keys(), boston_ds.values()): print("{}:\n{}\n".format(key, value)) |
データセットの構造は辞書型で、506の地域に関する13の特徴量と、当該地域における持家住宅の1000ドル単位の価格などのデータ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
data: [[6.3200e-03 1.8000e+01 2.3100e+00 ... 1.5300e+01 3.9690e+02 4.9800e+00] [2.7310e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9690e+02 9.1400e+00] [2.7290e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9283e+02 4.0300e+00] ... [6.0760e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 5.6400e+00] [1.0959e-01 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9345e+02 6.4800e+00] [4.7410e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 7.8800e+00]] target: [24. 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 15. 18.9 21.7 20.4 18.2 19.9 23.1 17.5 20.2 18.2 13.6 19.6 15.2 14.5 15.6 13.9 16.6 14.8 18.4 21. 12.7 14.5 13.2 13.1 13.5 18.9 20. 21. 24.7 30.8 34.9 26.6 ..... 16.7 12. 14.6 21.4 23. 23.7 25. 21.8 20.6 21.2 19.1 20.6 15.2 7. 8.1 13.6 20.1 21.8 24.5 23.1 19.7 18.3 21.2 17.5 16.8 22.4 20.6 23.9 22. 11.9] feature_names: ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO' 'B' 'LSTAT'] DESCR: .. _boston_dataset: Boston house prices dataset --------------------------- **Data Set Characteristics:** :Number of Instances: 506 :Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target. ..... - Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261. - Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann. filename: C:\Users\tomo\AppData\Local\Programs\Python\Python37-32\lib\site-packages\sklearn\datasets\data\boston_house_prices.csv |
データのキーは以下のようになっている。
|
1 2 3 4 5 6 7 |
from sklearn.datasets import load_boston boston_ds = load_boston() print(boston_ds.keys()) # dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename']) |
データの内容
'data'~特徴量データセット
506の地域における13の指標を特徴量として格納した2次元配列。列のインデックスが特徴量の番号に対応している。
|
1 2 3 4 5 6 7 8 |
data: [[6.3200e-03 1.8000e+01 2.3100e+00 ... 1.5300e+01 3.9690e+02 4.9800e+00] [2.7310e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9690e+02 9.1400e+00] [2.7290e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9283e+02 4.0300e+00] ... [6.0760e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 5.6400e+00] [1.0959e-01 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9345e+02 6.4800e+00] [4.7410e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 7.8800e+00]] |
'target'~住宅価格
506の地域における持家住宅の1000ドル単位の価格中央値
|
1 2 3 4 5 6 7 8 |
target: [24. 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 15. 18.9 21.7 20.4 18.2 19.9 23.1 17.5 20.2 18.2 13.6 19.6 15.2 14.5 15.6 13.9 16.6 14.8 18.4 21. 12.7 14.5 13.2 13.1 13.5 18.9 20. 21. 24.7 30.8 34.9 26.6 ..... 16.7 12. 14.6 21.4 23. 23.7 25. 21.8 20.6 21.2 19.1 20.6 15.2 7. 8.1 13.6 20.1 21.8 24.5 23.1 19.7 18.3 21.2 17.5 16.8 22.4 20.6 23.9 22. 11.9] |
'feature_names'~特徴名
13種類の特徴量の名称。
- CRIM:町ごとの人口当たり犯罪率
- ZN:25,000平方フィート以上の区画の住居用途地区比率
- INDUS:町ごとの小売り以外の産業用途地区比率
- CHAS:チャールズ川に関するダミー変数(1:川沿い、0:それ以外)
- NOX:NOx濃度(10ppm単位)
- RM:1戸あたり部屋数
- AGE:1940年より前に建てられた持家物件の比率
- DIS:ボストンの5つの職業紹介所への重みづけ平均距離
- RAD:放射道路へのアクセス性
- TAX:10,000ドルあたりの固定資産税総額
- PTRATIO:生徒対教師の比率
- B:1000(Bk – 0.63)^2(Bkは待ちにおける黒人比率)
- LSTAT:下位層の人口比率(%)
|
1 2 3 |
feature_names: ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO' 'B' 'LSTAT'] |
'filename'~ファイル名
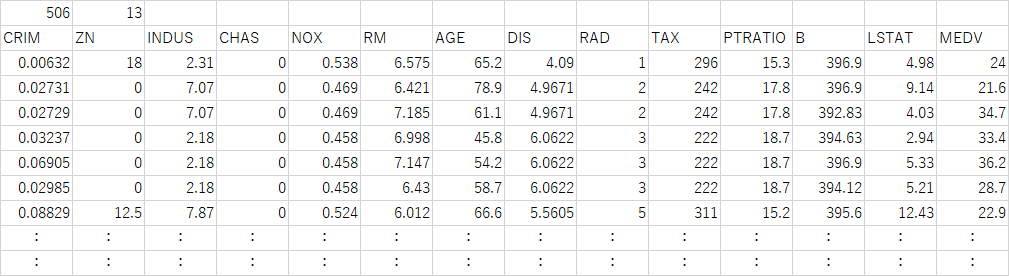
CSVファイルのフルパス名が示されている。1行目にはデータ数、特徴量数が並んでおり、2行目に13の特徴量とターゲットの住宅価格、その後に506行のレコードに対する13列の特徴量と1列のターゲットデータが格納されている。このファイルにはDESCRに当たるデータは格納されていない。
|
1 |
'C:...\lib\site-packages\sklearn\datasets\data\boston_house_prices.csv' |
'DESCR'~データセットの説明
データセットの説明。print(breast_ds_dataset['DESCR'])のようにprint文で整形表示される。
- レコード数506個
- 属性は、13の数値/カテゴリー属性と、通常はターゲットに用いられる中央値
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
.. _boston_dataset: Boston house prices dataset --------------------------- **Data Set Characteristics:** :Number of Instances: 506 :Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target. :Attribute Information (in order): - CRIM per capita crime rate by town - ZN proportion of residential land zoned for lots over 25,000 sq.ft. - INDUS proportion of non-retail business acres per town - CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise) - NOX nitric oxides concentration (parts per 10 million) - RM average number of rooms per dwelling - AGE proportion of owner-occupied units built prior to 1940 - DIS weighted distances to five Boston employment centres - RAD index of accessibility to radial highways - TAX full-value property-tax rate per $10,000 - PTRATIO pupil-teacher ratio by town - B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town - LSTAT % lower status of the population - MEDV Median value of owner-occupied homes in $1000's :Missing Attribute Values: None :Creator: Harrison, D. and Rubinfeld, D.L. This is a copy of UCI ML housing dataset. https://archive.ics.uci.edu/ml/machine-learning-databases/housing/ This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University. The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic prices and the demand for clean air', J. Environ. Economics & Management, vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics ...', Wiley, 1980. N.B. Various transformations are used in the table on pages 244-261 of the latter. The Boston house-price data has been used in many machine learning papers that address regression problems. .. topic:: References - Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261. - Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann. |
データの利用
データの取得方法
bostonデータセットから各データを取り出すのに、以下の2つの方法がある。
- 辞書のキーを使って呼び出す(例:
boston['DESCR']) - キーの文字列をプロパティーに指定する(例:
boston.DESCR)
全レコードの特徴量データの取得
'data'から、506のレコードに関する13の特徴量が506行13列の2次元配列で得られる。13の特徴量は’feature_names’の13の特徴名に対応している。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from sklearn.datasets import load_boston boston_ds = load_boston() print(boston_ds.data) # [[6.3200e-03 1.8000e+01 2.3100e+00 ... 1.5300e+01 3.9690e+02 4.9800e+00] # [2.7310e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9690e+02 9.1400e+00] # [2.7290e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9283e+02 4.0300e+00] # ... # [6.0760e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 5.6400e+00] # [1.0959e-01 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9345e+02 6.4800e+00] # [4.7410e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 7.8800e+00]] |
特定の特徴量のデータのみ取得
特定の特徴量に関する全レコードのデータを取り出すときにはX[:, n]の形で指定する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from sklearn.datasets import load_boston boston_ds = load_boston() features = boston_ds.feature_names X = boston_ds.data n_feature = 10 feature = X[:, n_feature] print("feature name : {}".format(features[n_feature])) print("feature data :\n{}".format(feature)) # feature name : PTRATIO # feature data : # [15.3 17.8 17.8 18.7 18.7 18.7 15.2 15.2 15.2 15.2 15.2 15.2 15.2 21. # 21. 21. 21. 21. 21. 21. 21. 21. 21. 21. 21. 21. 21. 21. # 21. 21. 21. 21. 21. 21. 21. 19.2 19.2 19.2 19.2 18.3 18.3 17.9 # ... # 20.2 20.2 20.2 20.2 20.2 20.2 20.2 20.2 20.2 20.2 20.2 20.2 20.1 20.1 # 20.1 20.1 20.1 19.2 19.2 19.2 19.2 19.2 19.2 19.2 19.2 21. 21. 21. # 21. 21. ] |