精度不足
書籍”Pythonではじめる機械学習”の”2.3.8.2 ニューラルネットワークのチューニング”で、scikit-learnのMLPをBreast Cancerデータセットに適用した例が示されている。
デフォルトのパラメーターのままで実行した例は以下の通りだが、訓練スコアとテストスコアは、書籍ではそれぞれ0.92と0.90となっていて、下の結果とは異なる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.neural_network import MLPClassifier ds = load_breast_cancer() X_train, X_test, y_train, y_test = \ train_test_split(ds.data, ds.target, random_state=0) print("for raw data") mlp = MLPClassifier(random_state=42).fit(X_train, y_train) print("Training score: {:.3f}".format(mlp.score(X_train, y_train))) print("Test score : {:.3f}".format(mlp.score(X_test, y_test))) # for raw data # Training score: 0.939 # Test score : 0.916 |
データの標準化
これに対して書籍では、特徴量データを標準化(standardize)する例を示している。同じコードで計算したのが以下の結果で、この場合は書籍と同じ値となっている。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
mean_train = X_train.mean(axis=0) std_train = X_train.std(axis=0) X_train_scaled = (X_train - mean_train) / std_train X_test_scaled = (X_test - mean_train) / std_train print("for scaled data") mlp = MLPClassifier(random_state=0).fit(X_train_scaled, y_train) print("Training score: {:.3f}".format(mlp.score(X_train_scaled, y_train))) print("Test score : {:.3f}".format(mlp.score(X_test_scaled, y_test))) # for scaled data # Training score: 0.991 # Test score : 0.965 |
ここで未収束の警告が出て、これも書籍と同じ。
|
1 2 |
ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet. % self.max_iter, ConvergenceWarning) |
書籍に倣ってmax_iter=1000とすると正常終了するが、今度は書籍の結果(0.995/0.965)と異なる結果となってしまう。
|
1 2 3 4 5 6 |
mlp = MLPClassifier(max_iter=1000, random_state=0).fit(X_train_scaled, y_train) print("Training score: {:.3f}".format(mlp.score(X_train_scaled, y_train))) print("Test score : {:.3f}".format(mlp.score(X_test_scaled, y_test))) # Training score: 1.000 # Test score : 0.972 |
random_stateが違う?
よく見ると、最初のコードではMPLClassifierのパラメーターでrandom_state=42とそれ以前と同じ値を使っているが、その後の2つの計算ではrandom_state=0と異なる値を使っている。MLPの解説で重みの初期値に影響するrandom_stateの値によってモデルが異なることを注意しているにもかかわらず、このパラメーターを変更している理由がよくわからない(値を42に揃えてみたところ、ドラスティックな変化はなかったが)。
重み係数の分布
最後に、書籍に掲載されているimshowを使った重み係数の分布を再現してみる。imshowは画像ファイルを表示するほかに、配列を与えてその内容に応じたイメージを表示できる。colorbarは扱いがややこしそうで、Axesに対して適当なメソッドが見当たらなかったので、ここではpyplotに直接描画している。
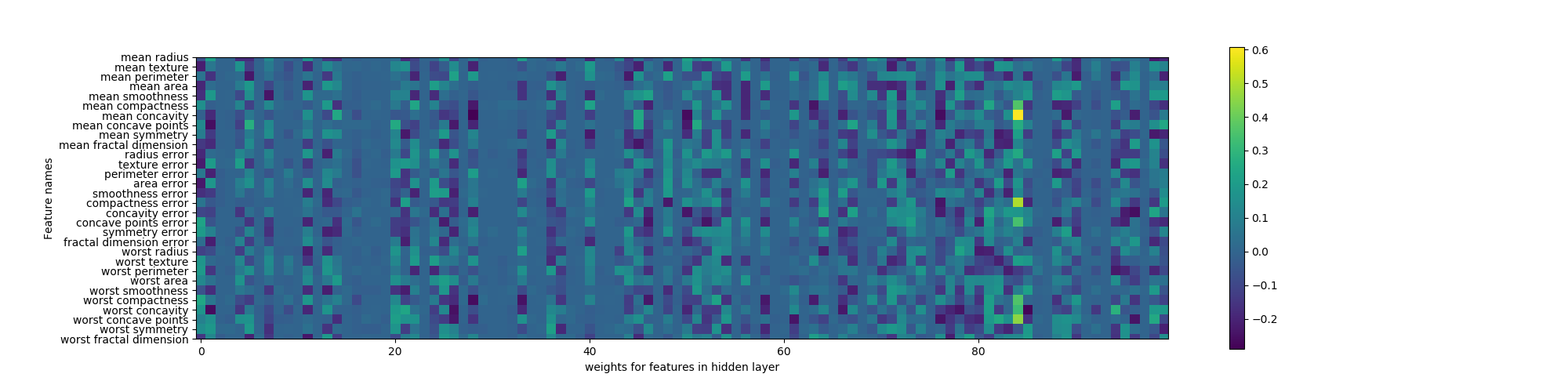
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import matplotlib.pyplot as plt from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.neural_network import MLPClassifier ds = load_breast_cancer() X_train, X_test, y_train, y_test = \ train_test_split(ds.data, ds.target, random_state=0) mlp = MLPClassifier(random_state=42, hidden_layer_sizes=[100]).fit(X_train, y_train) plt.figure(figsize=(20, 5)) plt.imshow(mlp.coefs_[0], interpolation='none', cmap='viridis') plt.yticks(range(30), ds.feature_names) plt.xlabel("weights for features in hidden layer") plt.ylabel("Feature names") plt.colorbar() plt.show() |