リスト関係
2次元リストを展開して1次元リストにしたい
itertools.chain.from_iterableを使う。
|
|
from itertools import chain lst = [[1, 2, 3], [4, 5, 6]] print(list(chain.from_iterable(lst))) # [1, 2, 3, 4, 5, 6] |
2次元リストを転置したい
2次元のリストを転置する方法を、順を追って確認する。
まず2次元リストの要素、すなわち各行を取り出す。リストの要素を分解するにはリストの先頭に'*'をつける。
|
|
list_2d = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] print(*list_2d) # [1, 2, 3] [4, 5, 6] [7, 8, 9] |
結果はリストやタプルではなく、独立した3つの子リストが取り出されている。
これらの結果は、zip関数の任意個数の引数として与えることができる。ただしその結果はタプルとして得られる。
|
|
for row in zip(*list_2d): print(row) # (1, 4, 7) # (2, 5, 8) # (3, 6, 9) |
この結果を内包表記を使って1つのリストにまとめると、3つのタプル行を含むリストになる。
|
|
list_2d_t = [row for row in zip(*list_2d)] print(list_2d_t) # [(1, 4, 7), (2, 5, 8), (3, 6, 9)] |
各行をタプルではなくリストとしたいので、list関数でタプルをリストに変換する。
|
|
list_2d_t = [list(row) for row in zip(*list_2d)] print(list_2d_t) # [[1, 4, 7], [2, 5, 8], [3, 6, 9]] |
これで元の2次元リストが転置された。
ndarray関係
1次元配列の2次元化
1次元配列を単に2次元化
1次元配列を2次元一要素の行ベクトルにする方法。
np.array([a])と2次元で構築するreshape(1, -1)で2次元1行の配列として変形
|
|
a = np.array([0, 1, 2, 3]) print(np.array([a])) print(a.reshape(1, -1)) # [[0 1 2 3]] |
1次元配列の列ベクトル化
1次元配列を2次元の列ベクトルにする方法。hstack()などで列ベクトルを横に結合していくときに必要。
- reshape(-1, 1)でn行1列の配列として変形
|
|
a = np.array([0, 1, 2, 3]) print(a.reshape(-1, 1)) # [[0] # [1] # [2] # [3]] |
2つの1次元配列の結合
縦に積み重ねる
素直に実行するならvstack()を使うのがおすすめ。
vstack()は1次元配列のままで積み重ねられるappend()は1次元配列を2次元化する必要がある
|
|
a = np.array([0, 1, 2]) b = np.array([3, 4, 5]) print(np.vstack((a, b))) print(np.append(a.reshape(1, -1), b.reshape(1, -1), axis=0)) # [[0 1 2] # [3 4 5]] |
列ベクトルとして横につなげていく
この場合はhstack()が意外にややこしく、c_が手軽。ただし列ベクトルを意識するならhstack()もアリ。
- 1次元配列を
reshape()で列ベクトル化し、hstack()を使う(1次元配列のままだと横1列に伸びるだけ)
c_を使う(1次元配列でも列ベクトル化されて結合される)
|
|
a = np.array([0, 1, 2]) b = np.array([3, 4, 5]) print(np.hstack((a.reshape(-1, 1), b.reshape(-1, 1)))) print(np.c_[a, b]) # [[0 3] # [1 4] # [2 5]] |
空のベクトルへの追加
1次元配列の縦方向への追加
縦方向に追加するならvstack()が全般によさそう。
empty((0, n), dtype=type)で空の配列を準備し、これにvstack()で1次元配列をそのまま追加していく。
|
|
a = np.empty((0, 3), dtype=int) b = np.array([0, 1, 2]) a = np.vstack((a, b)) print(a) # [[0 1 2]] b = np.array([3, 4, 5]) a = np.vstack((a, b)) print(a) # [[0 1 2] # [3 4 5]] |
1次元配列を列ベクトルとして横方向に追加
empty((n, 0), dtype=type)で空の配列を準備し、1次元配列をreshape()で列ベクトルに変形してhstack()で追加していく。
|
|
a = np.empty((3, 0), dtype=int) b = np.array([0, 1, 2]) a = np.hstack((a, b.reshape(-1, 1))) print(a) # [[0] # [1] # [2]] b = np.array([3, 4, 5]) a = np.hstack((a, b.reshape(-1, 1))) print(a) # [[0 3] # [1 4] # [2 5]] |
または、c_を使うとreshape()を使わなくてもそのまま列ベクトルとして追加してくれる。
|
|
a = np.empty((3, 0), dtype=int) b = np.array([0, 1, 2]) a = np.c_[a, b] print(a) b = np.array([3, 4, 5]) a = np.c_[a, b] print(a) |
多次元配列の1次元化
2次元以上の配列を1次元としたいときは、reshape(-1)、flatten()、ravel()メソッド/関数を使う(詳しくはこちら)。
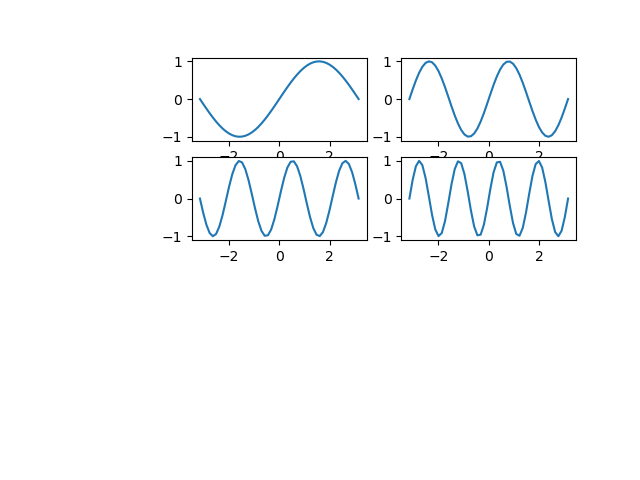
たとえばpyplotのsubplotで2次元の配列として得られたAxesオブジェクト(への参照)に対して全て同じ処理を施したいときに、以下のようにする。
|
|
import numpy as np import matplotlib.pyplot as plt fig, axs = plt.subplots(2, 2) for ax in axs.reshape(-1): ax.tick_params(left=False, bottom=False, labelleft=False, labelbottom=False) plt.show() |
条件による抽出
条件に合う要素を取り出す
|
|
a = np.arange(10) print(a[a>=5]) # [5 6 7 8 9] |
条件式による要素の取り出しを参照。
条件に合う要素のインデックスを取り出す
|
|
a = np.arange(10, 20) print(a[np.where(a%2==0)]) # (array([0, 2, 4, 6, 8], dtype=int32),) # [10 12 14 16 18] |
1次元配列の条件に合う行を2次元配列から切り出す
特徴量データの配列のうち、特定のクラスに属するデータだけを取り出したいときなど。
|
|
X = np.array([ [11, 12, 13], [21, 22, 23], [31, 32, 33], [41, 42, 43], ]) y = np.array([0, 1, 2, 3]) print(X[y%2==0]) # [[11 12 13] # [31 32 33]] |
インデックス配列の置き換え
例えばclass_name = np.array(["Class-0", "Class-1", "Class-2"])と定義されているとき、配列np.array([0 1, 2, 0])の各要素をインデックスとしてclass_nameの要素で置き換えたい(numpy.ndarray(['Class-0', 'Class-1', 'Class-2', 'Class-0'])を得たい)。
|
|
class_name = np.array(["Class-0", "Class-1", "Class-2"]) indexes = np.array([0, 1, 2, 0]) print(class_name[indexes]) # ['Class-0' 'Class-1' 'Class-2' 'Class-0'] |
インデックス配列の置き換えを参照。
統計値の計算
min, max, argmin, argmax
1次元配列のmin()メソッド/max()メソッドを使うと、要素の中の最小値/最大値が得られる。また、argmin()メソッド/argmax()メソッドを使うと、最小の要素/最大の要素のインデックスが得られる。
|
|
a = np.array([10, 11, 12, 13]) print(a.min(), a.max()) # 10 13 print(a.argmin(), a.argmax()) # 0 3 |
2次元配列の場合は、a.reshape(-1).min()やa.reshape(-1).argmin()などと同じ結果となる。
|
|
a = np.array([ [11, 12, 13], [21, 22, 23], [31, 32, 33], ]) print(a.min(), a.max()) # 0 8 print(a.argmin(), a.argmax()) # 11 33 |
メソッドの引数でaxis=0を指定すると、各列ごとの最小値/最大値を要素とする1次元配列を得る。
|
|
print(a.min(axis=0)) # [11 12 13] print(a.max(axis=0)) # [31 32 33] |
axis=1を指定すると、各行ごとの最小値/最大値を要素とする1次元配列を得る。この場合、この配列を列ベクトルとして考えると対比がわかりやすい。
|
|
print(a.min(axis=1)) # [11 21 31] print(a.max(axis=1)) # [13 23 33] |
sum,mean
要素の和や平均を計算するsum()メソッド/mean()メソッドもmin()/max()と同じように機能する。
1次元配列の場合。
|
|
a = np.array([1, 2, 3, 4, 5]) print(a.sum()) # 15 print(a.mean()) # 3.0 |
2次元配列の場合は全要素で計算したスカラーを返す。
|
|
a = np.array([ [0, 1, 2], [3, 4, 5], [6, 7, 8], ]) print(a.sum()) # 36 print(a.mean()) # 4.0 |
axis=0で列ごとに計算した結果を1次元配列で返す。
|
|
print(a.sum(axis=0)) # [ 9 12 15] print(a.mean(axis=0)) # [3. 4. 5.] |
axis=1で行ごとに計算した結果を1次元配列で返す。この配列が列ベクトルだと解釈すると分かりやすい。
|
|
print(a.sum(axis=1)) # [ 3 12 21] print(a.mean(axis=1)) # [1. 4. 7.] |
順列や組み合わせを得たい
概要
順列や組み合わせの結果としての要素のコレクションを得たいときは、itertoolsパッケージを使い、結果のイテレーターをforループなどで利用。
要素数(選び出す個数)指定のパラメーター名や省略時の挙動がそれぞれで異なっているので注意。
直積
itertools.product()で直積のイテレーターを得る。
|
|
import itertools import numpy as np a = [1, 2, 3] for prod in itertools.product(a, repeat=2): print(prod, end=" ") # (1, 1) (1, 2) (1, 3) (2, 1) (2, 2) (2, 3) (3, 1) (3, 2) (3, 3) |
順列
itertools.permutations()で順列のイテレーターを得る。
|
|
for perm in itertools.permutations(a, r=2): print(perm, end=" ") # (1, 2) (1, 3) (2, 1) (2, 3) (3, 1) (3, 2) |
組み合わせ
itertools.combinations()で組み合わせのイテレーターを得る。
|
|
for comb in itertools.combinations(a, r=2): print(comb, end="") # (1, 2)(1, 3)(2, 3) |
重複組み合わせ
combinations_with_replacement()で重複ありの組み合わせのイテレーターを得る。
|
|
for comb_repl in itertools.combinations_with_replacement(a, r=2): print(comb_repl, end="") # (1, 1)(1, 2)(1, 3)(2, 2)(2, 3)(3, 3) |

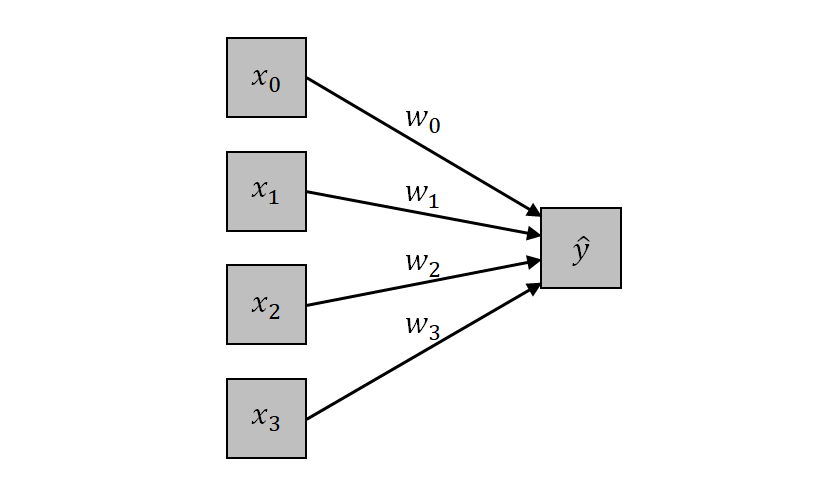
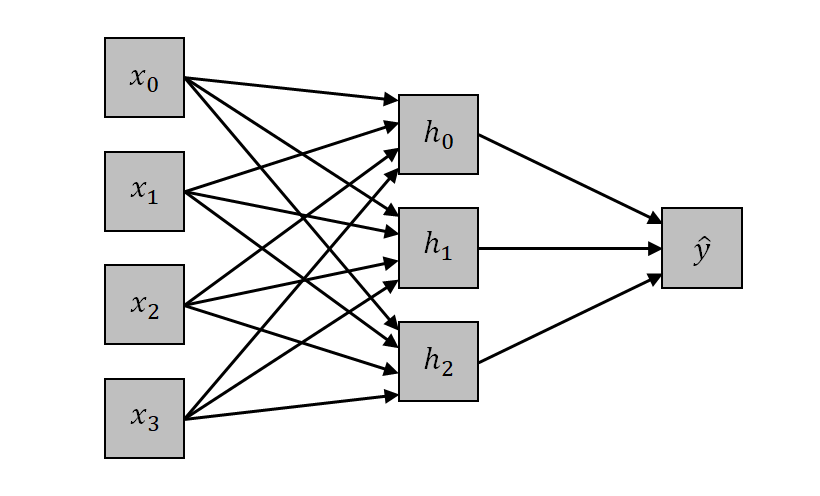

 に対する重みをvj、切片をcとすると、出力への重み付き線形和は以下のようになる。
に対する重みをvj、切片をcとすると、出力への重み付き線形和は以下のようになる。