例題のデータ
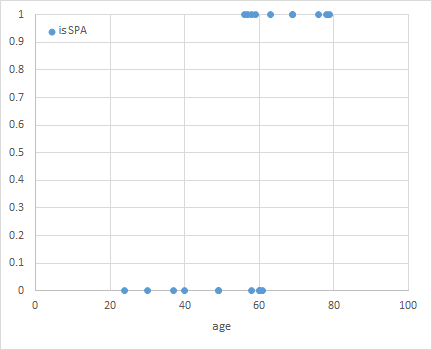
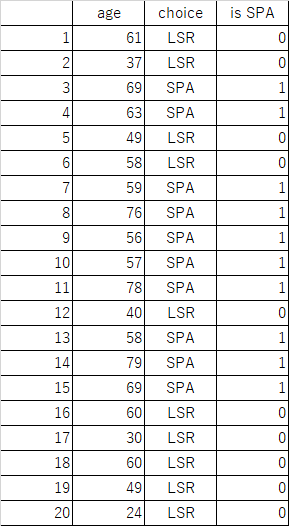
ある旅行会社の会員顧客20人の年齢と、温泉(SPA)とレジャーランド(LSR)のどちらを選んだかというデータが以下のように得られているとき、新たな顧客にどちらを勧めればより適切か。
このようなクラス分けの問題にLogistic回帰を使うのにPythonのパッケージなどによる方法もあるが、ここではExcelを使った方法を示す。
その流れは、各観光客の選択結果のカテゴリー変数と年齢から個別の尤度と合計の尤度の計算式を定義し、切片と係数の初期値を設定しておいてから、尤度が最大となるような切片・係数を求めるためにExcelのソルバーを使う。
元となるデータは、各観光客の年齢と、行先に選んだのが温泉(SPA)かレジャーランドか(LSR)の別、それらに対して温泉を選んだ場合は1、レジャーランドを選んだ場合は0となるカテゴリー変数。
計算表の準備
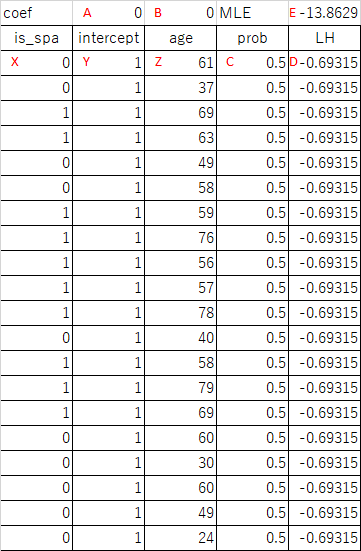
このデータから以下のような表を作る。各セルの意味と内容は以下の通り。
- coef:線形式の切片Aと係数Bの初期値としてそれぞれ0をセットし、収束計算の結果が入る
- intercept:切片の計算のために使われるデータで、全て固定値の1
- prob:coefがA, Bの値の時に各顧客の年齢に対してis_spa=1となる確率で、Logistic関数の計算値
- セルの内容は計算式で
=1/(1+EXP(-$A*Y-$B*Z)) - $A, $Bは固定座標を表し、全てのデータに対してこれらのセルの内容を使う
- セルの内容は計算式で
- LH:is_spaの値に対する尤度(likelihood)
- セルの内容は計算式で
X*LN(C)+(1-X)*LN(1-C)
- セルの内容は計算式で
- MLE:全データのLHの和で、このデータセットのパターンに対する最大尤度の結果が入る
収束計算
データタブの一番右にあるソルバーに入る(ない場合はファイル→オプション→アドイン→設定からソルバーアドインにチェックを入れる)。
ソルバーのパラメーター設定ダイアログで、
- 目的セルを上記のDで選択
- 変数セルを上記のA:Bの範囲で選択。
- 目標値は「最大値」を選択
「解決」ボタンを押して収束計算すると、Dの値を最大化するA:Bの内容がセットされる。
この場合の結果は以下の通り
- coef:-13.6562, 0.234647
- MLE:-7.45298
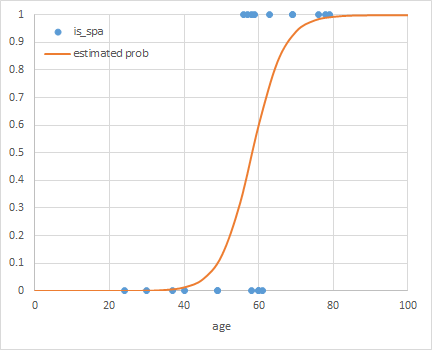
確率0.5(線形式の値が0)を温泉とレジャーランドの閾値とするなら、それに相当する年齢は以下のように計算される。
(1) 
Pythonのscikit-learnのLogisticRegressionモデルを同じデータに適用した結果(C=1e5)は以下の通りで、かなり近い値となっている。
intercept_ = [-13.38993211]coefficient_ = [0.23015561]
得られた係数の値を使って、以下の関数式のグラフを描いてみたのが以下の図でLogistic曲線が現れている。