概要
2020年9月時点で、COVID-19いわゆる新型コロナウイルス感染症は収束を見ていない。このコロナウイルスについて、PCR検査を増やすべきだ、いや効果はない/医療現場の負担が増えるだけ、といろいろな論が飛び交っている。
不思議なことに、多くの人の目に触れるマスメディアや一般的なネットのソースでは、殆どの場合定性的な、あるいはそれ以前の論拠もないようなものばかりが並んでいる。意図してネットで検索すると確率論を適用しているものも見られるが、残念ながらほとんどの人はこれらのコンテンツはその意義や存在さえ意識しないだろう。
新型コロナウイルスの場合、計算に必要なデータは未詳のようだが、少なくともベイズ理論を適用する教科書的なパターンの問題である。そこで、この機に学んだいくつかの用語や概念、計算過程などをまとめておく。
なお、難病検査を例にした条件付確率の考え方はこちらにまとめている。
基本のデータ
定義
鍵となる指標の定義を確認するとともに、その記号を以下のように定義する。
医学・疫学上の指標
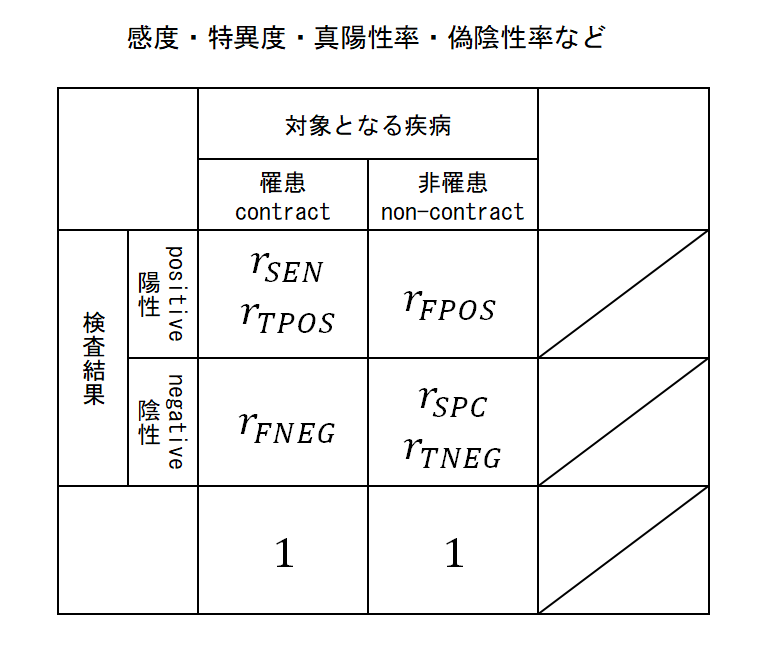
陽性率/陰性率
以下は罹患している/罹患していないことがわかっている人の集合に対する割合。
- 感度(sensitivity):rSEN
- 真陽性率(true positive rate):rTPOS
- 罹患している人の検査結果が陽性と判定される割合。
- 特異度(specificity):rSPC
- 真陰性率(true negative rate):rTNEG
- 罹患していない人の検査結果が陰性と判定される割合。
- 偽陽性率(false positive rate):rFPOS
- 罹患していない人の検査結果が陽性と判定される割合。
- 偽陰性率(false negative rate):rFNEG
- 罹患している人の検査結果が陰性と判定される割合。
これらの関係を図にすると以下の通り。真/偽の陽性率/陰性率は罹患者数のみあるいは非罹患者数のみの集団に対して、検査の判定結果を集計して計算される。表から、検査判定の陽性/陰性の割合は問題にしていないことがわかる。
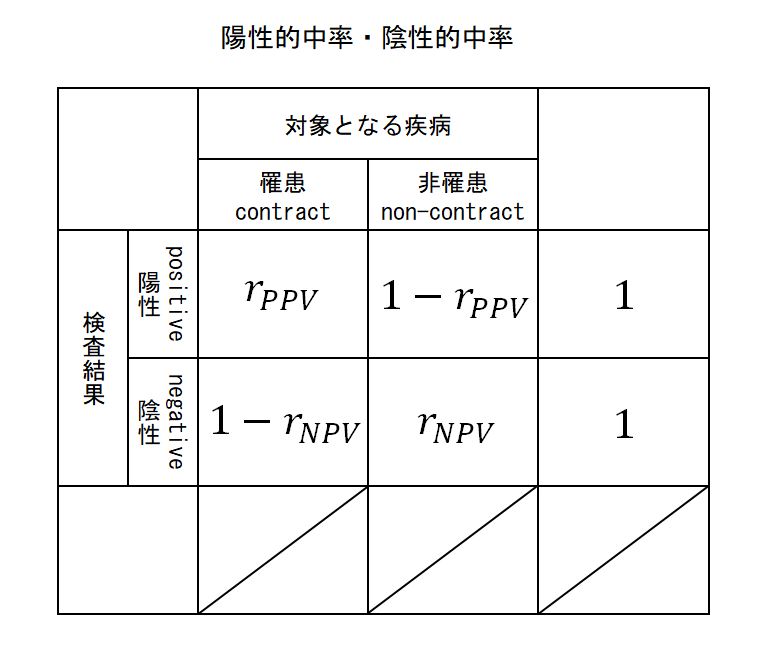
的中率
次に検査結果が判明している集団の実際の罹患状態に関する割合。
- 陽性的中率(Positive Predictive Value: PPV, PV+):rPPV
- 検査で陽性と判定された人のうち、実際に罹患者である割合。
- 陰性的中率(Negative Predictive Value: NPV, PV-):rNPV
- 検査で非陽性と判定された人のうち、実際に罹患していない者である割合。
これらは検査の判定結果が陽性あるいは陰性の集団における罹患/非罹患の人の割合で、罹患している(あるいはしていない)人の全体の割合は問題にしていない。
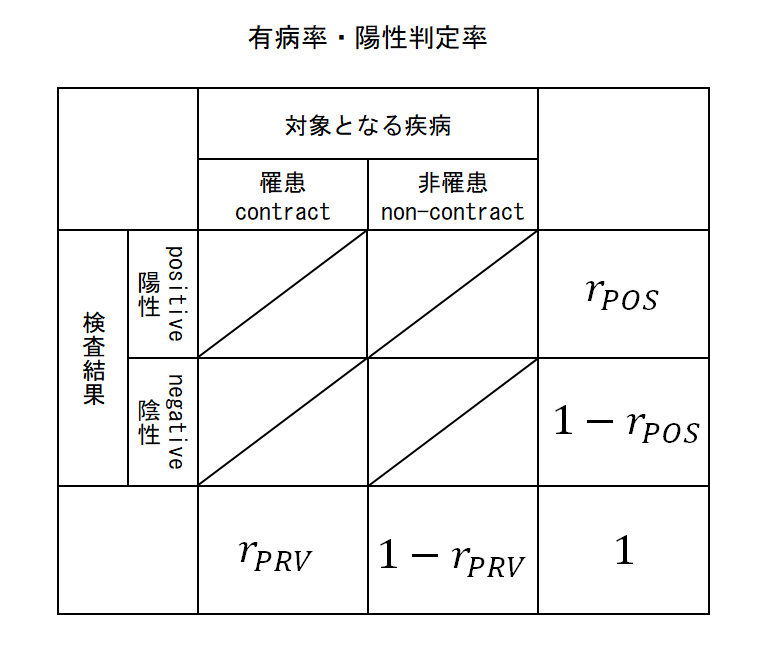
有病率/陽性率など
以下は対象となる集団全体における検査結果の割合や罹患状態の割合。
- 陽性率(positive rate):rpos
- 検査で陽性と判定された人の割合。
- 有病率(Prevalence / Prevalence rate):rPRV
- ある時点における疾病者数の人口に対する割合。
- 罹患率(Incidence / Incidence rate):rINC
- ある期間において、疾病リスクのある人が対象とする疾病に罹患する割合。
これらは対象エリアの全員に対して罹患している人の割合、検査結果が陽性の人の割合である。有病率と罹患率の違いは一般にはあまり伝えられていないようだ。図にすると以下のようになる。
補足:感度と特異度について
「感度(sensitivity)」が「罹患している」という帰無仮説が真なのに検査で陰性と判定してしまう誤り、いわば「第一種の過誤」を起こさない確率と言える。
また「特異度(specificity)」が「罹患していない」という仮説(上の帰無仮説の対立仮説)が真なのに検査で陽性と判定してしまう誤り、すなわち「第二種の過誤」を起こさない確率と言える。
補足:「特異度」という表現について
「特異度」の用語には違和感がある。日本語の「特異な」ならsinglularやpeculiarの方が近く、specificは「明確な」、「特定の」というのが相当する(specifyという動詞もその意味でつかわれる)。「特別な」というニュアンスもあるようだが、「特異」というのは言い過ぎではないか。
specificityは罹患していない人を検査で陰性と正しく判定する割合なので、罹患していない人が大勢だとすると、その明白な事実を支持する割合、「明白度」とすると、ちょっと意味が分からなくなる。あるいは、その人が罹患していないということを特定するなら、せめて「特定度」くらいか。
いずれにしても、「特異度」という表現が使われているのは、英語の単語のニュアンスからしても、そもそもの意味合いからしても気持ちが悪い。
ここで定義する記号
- C / N
- 罹患している(contract)/罹患していない(non-contract)の人の集合
- + / −
- 検査結果が陽性/陰性の人の集合
- N
- 検査人口
- N+ / N−
- それぞれ検査結果が陽性/陰性の人口
- NC / NN
- 検査を受けた人のうち、それぞれ罹患している(contract)/罹患していない(non-contract)人の人口
- nC+ / nC– , nN+ / nN–
- 検査を受けた人のうち、それぞれ、罹患していてかつ検査結果が陽性(C+)あるいは陰性(C−)、罹患しておらずかつ検査結果が陽性(N+)あるいは陰性(N−)の人の人口
これらを表で整理すると以下の通り。
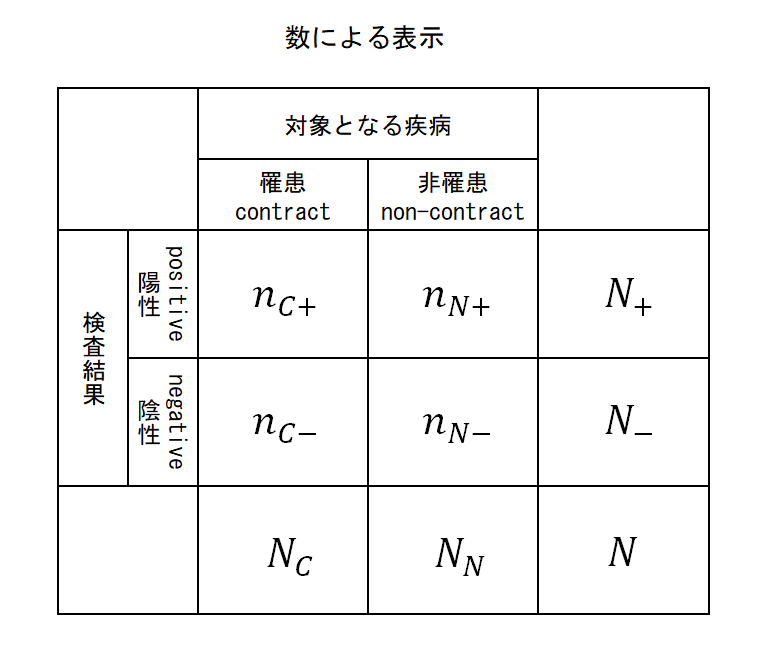
また、これらから計算される確率は以下の通り。
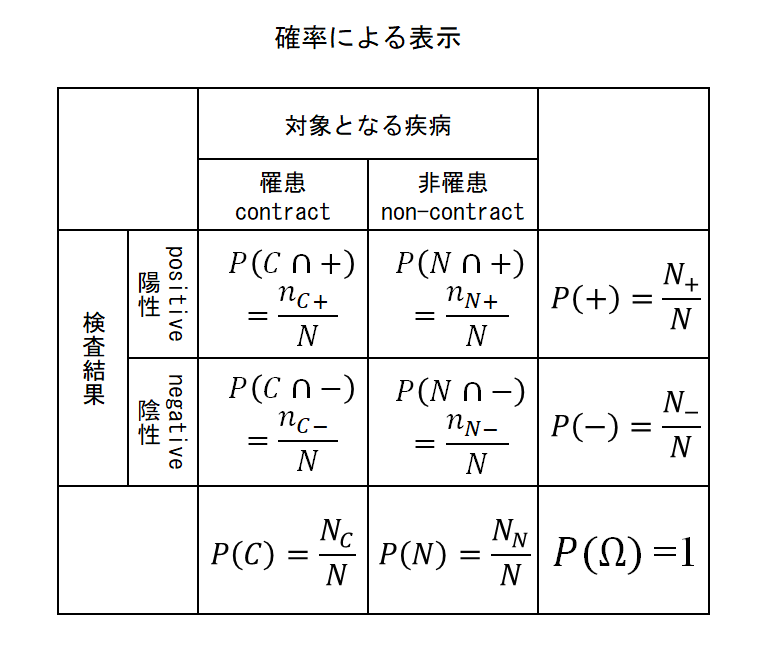
条件付確率による表示
感度/特異度(真陽性率/真陰性率)
感度や特異度は、ある人が罹患している/罹患していない場合に検査結果が陽性/陰性となる確率ともいえる。これを条件付確率で表示し、的中率による表現に変換すると以下のようになる。
(1) 
偽陽性率/偽陰性率
偽陽性/偽陰性についても条件付確率で表し、これらを的中率による表現に変換すると以下のようになる。
(2) 
たとえばここで真陽性率と偽陰性率を加えると、
(3) 
ここで総数Nを仮定して分母分子にかければ、結果は1となることがわかる。
陽性的中率/陰性的中率
的中率は検査の判定陽性/陰性に対して、その対象者が実際に罹患/非罹患である割合を表す。これを条件付確率で表して陽性率や陰性率で表すと以下のようになる。
(4) 
実際の使われ方
多くの場合、検査方法の精度を確認するには、「罹患している人と罹患していない人を連れてきて検査をしてみる」というのが妥当だろう。感染症などで疑いがある人が医療機関に集まるから、そういうところで臨床的に試すのだろう。場合によって臨床例が少ない場合は、とにかく検査方法を適用しながら、実際の罹患状態をトレースするという方法がとられるのかもしれないが。
ただCOVID-19のPCR検査の場合、データが公表されていないのかどうかわからないが、感度については適当に(あるいは他サイトで使われている値を持ってきて)設定したりしているものしか見当たらない。以下のような手順が見られる。
- 感度と特異度を適当に設定する。感度は70%、特異度は99%というのがほとんど。
- 対象エリアの陽性者数nと総人口Nを持ってくる。
- 陽性者数を感度で割って、罹患者数を算出。
- 罹患者数を総人口で割って有病率を算出。
- 総人口から有病人口を引いて非罹患者数を算出。
- 非罹患者数と特異度の定義から偽陽性者数を算出。
- 以上のパラメーターを使って陽性的中率を算出。
計算された陽性的中率がかなり低いと主張しているものや、オーソリティーがありそうなサイトでも例題みたいな数字を示して有病率10%くらいで設定したりしているものや、結構混乱しているようだ。
ここで陽性的中率を感度で微分して、感度を見てみる(ややこしい)。
(5) 
有病率が10000人に一人、陽性判定率が100人にひとりくらいなら、1%くらいで、感度(真陽性率)が数十%くらい違っても差は出なさそうだ。それよりも有病率がかなり低いと、いくら高感度の検査方法でも陽性的中率がかなり低くなりそうなことが式から読み取れる。
一方偽陽性率の方は、有病率や陽性的中率が結構低いとすると、陽性判定率の値が効いてくる。これは結構無視できないレベルのように思えるが。
ただ、共通して使えるデータが見当たらないので、数値の信憑性が揺らいでいるように思える。罹患・非罹患を計算するのに母数にエリアの全人口を使ったりするのは、検査をしていない人すべてを非罹患とみているので有病率を過少に見積もることになるだろう。
退院前の検査を含むかどうかなど定義の問題はあるが、そのようなフラグを立てたデータを集約するだけでも有益な情報になると思う。


 と置く。
と置く。


 として、以下を得る。
として、以下を得る。
















 と不偏分散s2を求める
と不偏分散s2を求める




 と不偏分散s2が以下であるとする。
と不偏分散s2が以下であるとする。







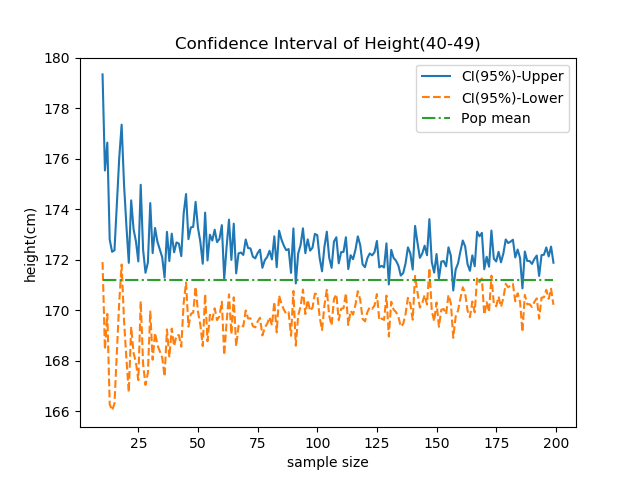
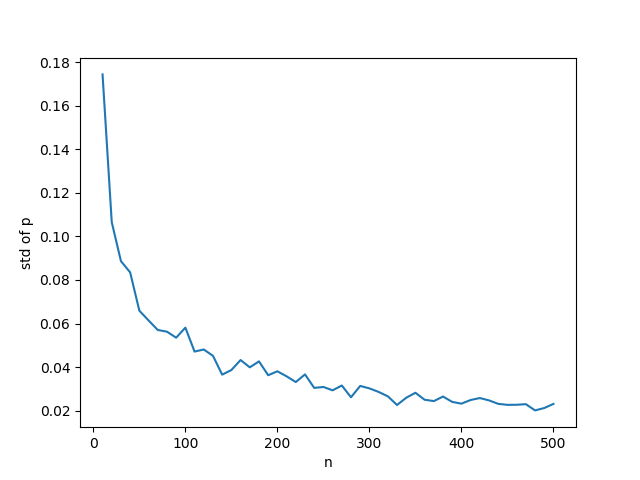
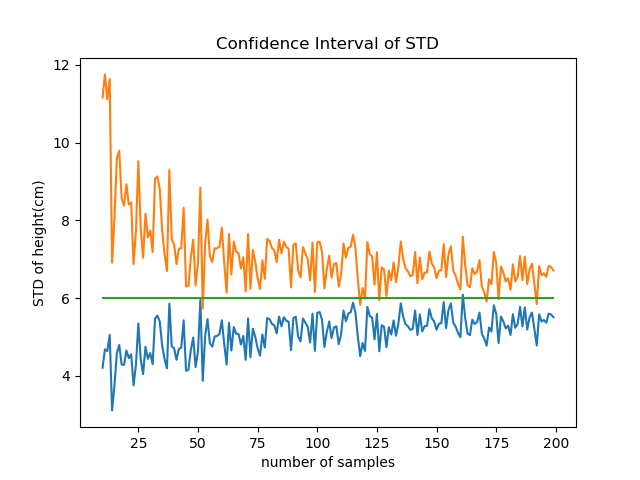
 のグラフを描いてみると分かるが、n=20程度まで急激に小さくなり、その後の減少スピードはかなり遅いことがわかる。したがって、信頼区間を狭めようとしても、効果があるのはせいぜいデータ数50程度までということになる。
のグラフを描いてみると分かるが、n=20程度まで急激に小さくなり、その後の減少スピードはかなり遅いことがわかる。したがって、信頼区間を狭めようとしても、効果があるのはせいぜいデータ数50程度までということになる。 などのグラフを描くべき。ご指摘に感謝します。
などのグラフを描くべき。ご指摘に感謝します。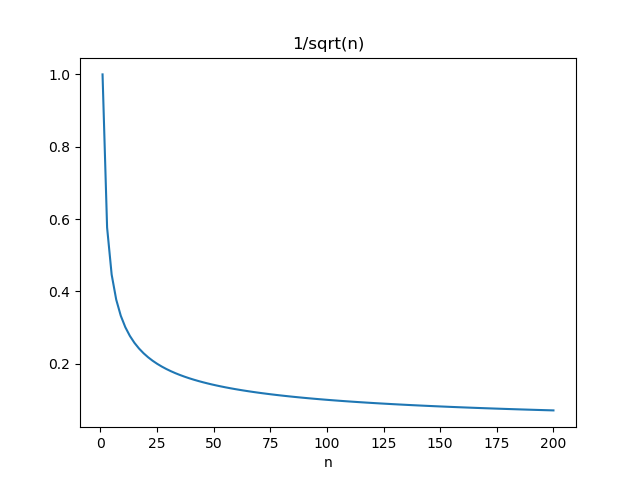
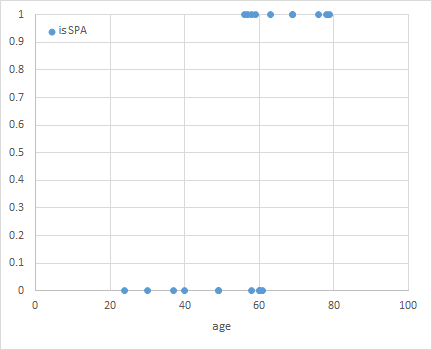
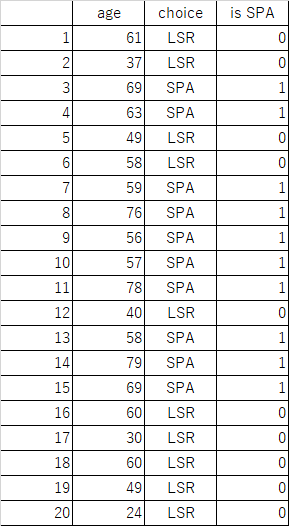
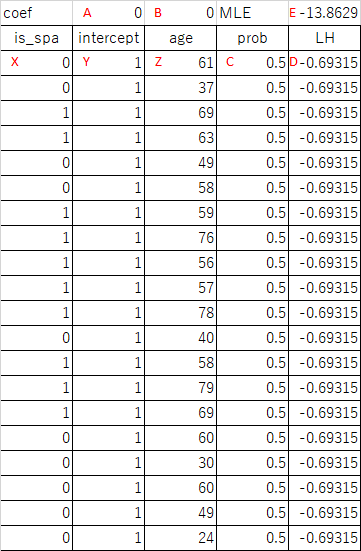

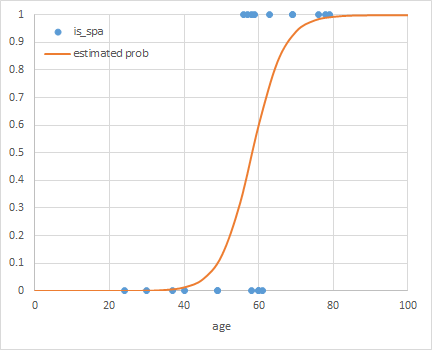
 で表し、
で表し、 となる確率が
となる確率が であるとする。
であるとする。
 回繰り返したとき、
回繰り返したとき、 が生じる回数の確率分布が二項分布(Binomial distribution)で、
が生じる回数の確率分布が二項分布(Binomial distribution)で、 のように表示される。二項分布の例には以下のようなものがある。
のように表示される。二項分布の例には以下のようなものがある。 回起こるケースは、
回起こるケースは、 通りなので、二項分布の確率は以下のように表せる。
通りなので、二項分布の確率は以下のように表せる。
 の確率の和が全事象の確率であり、
の確率の和が全事象の確率であり、

 の二項分布のグラフをPythonで描くと以下のようになる。
の二項分布のグラフをPythonで描くと以下のようになる。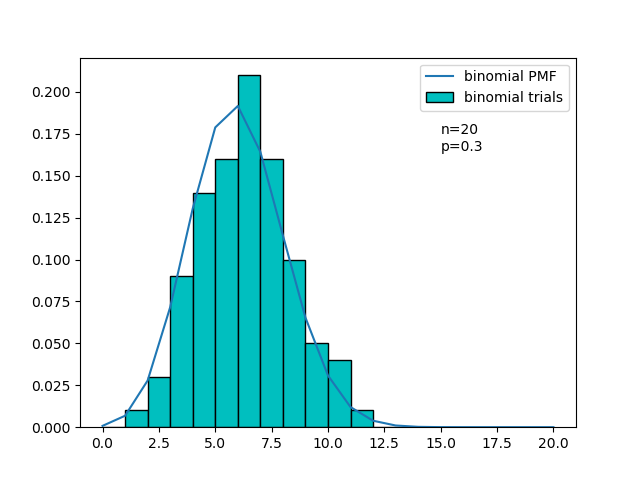
 が十分大きいとき(具体的には5より大きいとき)、平均
が十分大きいとき(具体的には5より大きいとき)、平均 、分散
、分散 の正規分布で近似できる(ド・モアブル-ラプラスの定理)。
の正規分布で近似できる(ド・モアブル-ラプラスの定理)。
 の平均と分散がnp, np(1 − p)であることからわかる。
の平均と分散がnp, np(1 − p)であることからわかる。 の3つずつの組み合わせに対する、二項分布と正規分布の一致具合を比べたもの。表示範囲は、正規分布とみなしたときの
の3つずつの組み合わせに対する、二項分布と正規分布の一致具合を比べたもの。表示範囲は、正規分布とみなしたときの に対応する範囲で設定している。
に対応する範囲で設定している。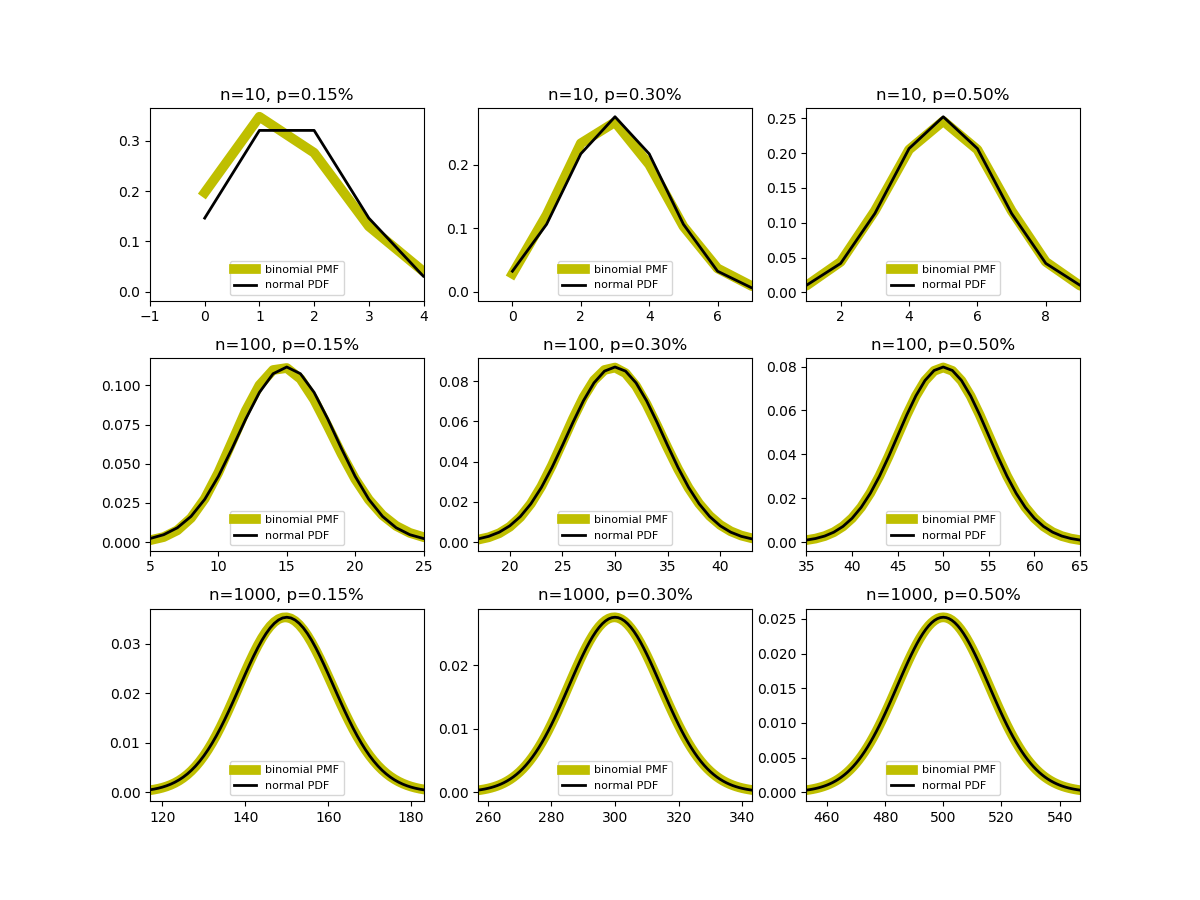
 である。
である。