概要
一様分布をとる乱数によってランダムな到着をシミュレートし、ポアソン過程の時間間隔や到着回数を理論上の確率分布と比較してみた。
手順
- 表計算ソフトで0 ~1の間で平均して10個の発生するように乱数を発生させる
- 0~1で10個
- 0~10で100個
- 0~100で1000個
- その値を昇順にソート(到着事象の到着時刻順にあたる)
- 到着時刻の分布を確認
- 到着時間間隔の分布と指数分布の比較
- 各到着時刻間の時間間隔を計算
- 時間間隔データの頻度(確率密度に相当)を棒グラフで表示し、指数分布の密度関数のグラフを重ねて比較
- 時間間隔データの累積頻度(確率分布に相当)を棒グラフで表示し、指数分布関数のグラフを重ねて表示
- 到着回数の分布とPoisson分布の比較
指数分布のデータを得る手順については、 (参考)データ数10個の場合到着時間間隔の計算手順を参照。
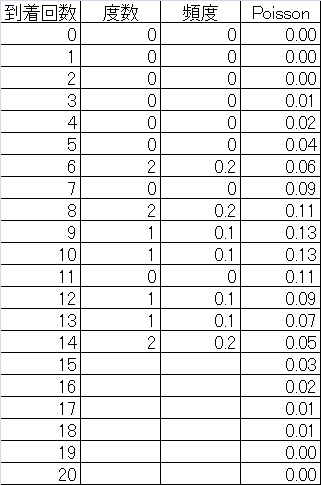
Poisson分布のデータを得る手順については、(参考)データ数100個の場合の到着数の計算手順を参照。
以下、データ数10、100、1000の場合の到着時刻の分布、到着間隔の確率密度と確率分布について比較していく。
到着時刻の分布の比較
データ数10、100、1000に対する到着時刻の分布を以下に示す。
データ数が多くなるほどグラフは平滑になるが、1000個と比較的多くのデータでもばらつきが見られる。
データ数:10
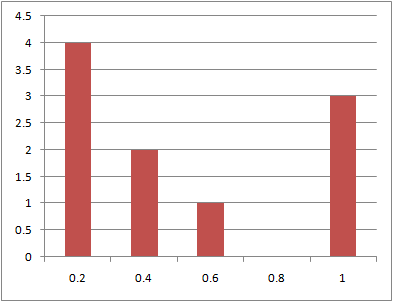
データ数:100
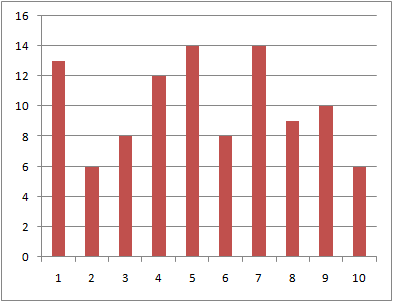
データ数:1000
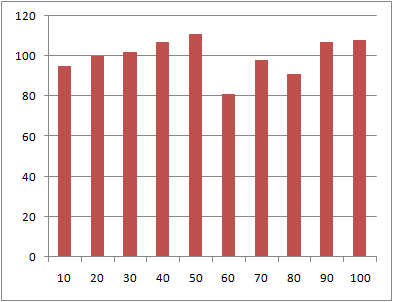
到着時間間隔と指数分布の比較
頻度(確率密度)
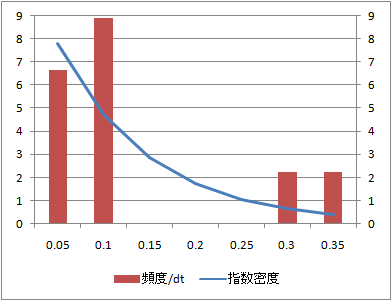
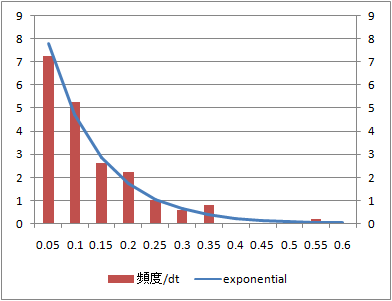
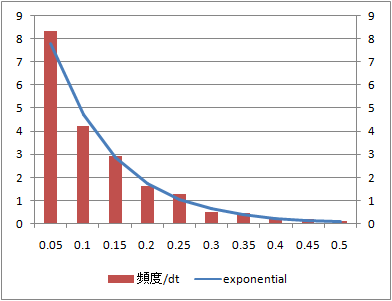
データ数10、100、1000に対する到着時間間隔の頻度分布とこれに相当する指数分布の確率密度関数を比較する。
到着時刻の分布に比べてデータ数100からシミュレーション値と理論値がよく整合している。
データ数:10
データ数100
データ数1000
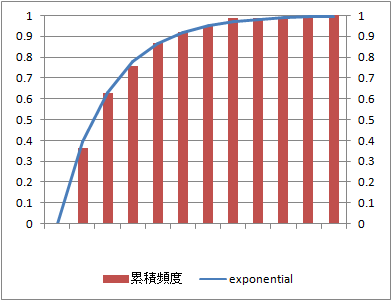
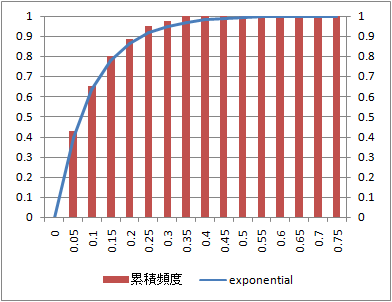
累積頻度(確率分布)
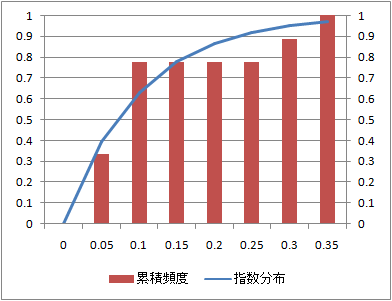
同じデータの累積頻度とこれに相当する指数分布の確率分布関数を比較する。
確率分布に関しては、データ数10と少ないデータでも理論値と類似している。
データ数:10
データ数:100
データ数:1000
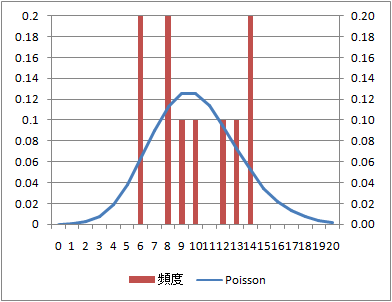
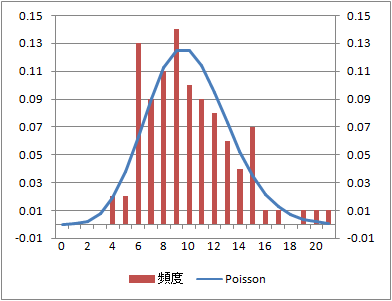
到着数の分布とPoisson分布の比較
到着数の分布をみるためには、データ数10個の場合はデータセットにならないため、データ数100、1000で比較してみる。データ数100を10組に、データ数100は100組のデータセットを得ることができる。
到着数の分布と理論上のPoisson分布との整合性は、データセット数100でもそれほどよくない。
データ数:100(データセット数:10)
データ数:1000(データセット数100)
(参考)データ数10個の場合到着時間間隔の計算手順
以下の表は、0~1の範囲で10個の乱数を発生させ、それらを昇順にソートして発生間隔を計算したもの。
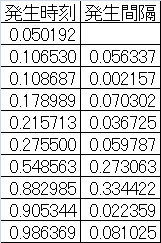
まず、これらの発生時刻を、一定の階級幅で度数分布に分ける。データ数が10個の場合はばらつきが大きいが、データ数が多くなると、これが一様分布に近づくと期待される。
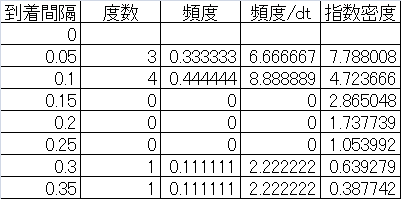
次に、到着時間間隔の度数分布とその頻度を計算する。これを指数分布の密度関数と比較するため、時間間隔dtで除している。一番右の欄は、到着率10の指数分布の密度関数の値。
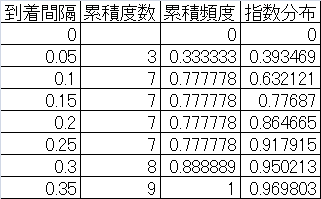
最後に、指数分布の確率関数と比較をするため、到着間隔の累積度数と頻度を計算する。一番右の欄は、到着率10の確率分布関数の値。
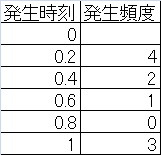
(参考)データ数100個の場合の到着数の計算手順
元データは、到着時刻を昇順にソートしたもの。

これらのデータの、0以上1未満、1以上2未満、・・・・、9以上10未満の10組ごとのデータ数を数える。
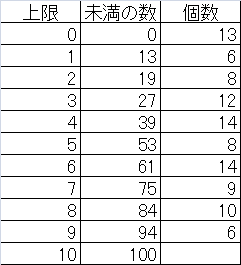
これらについて、到着回数ごとの頻度分布に整理する。下表一番右の欄は、到着率10に対するPoisson確率値。