概要
sklearn.datasets.make_circles()はクラス分類のためのデータを生成する。2つのクラスのデータが同心円状に分布し、各クラスの半径の差異、データのばらつきを指定できる。
得られるデータの形式
2つの配列X, yが返され、配列Xは列が特徴量、行がレコードの2次元配列。ターゲットyはレコード数分のクラス属性値の整数で0か1の値をとる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from sklearn.datasets import make_circles X, y = make_circles(n_samples=10, random_state=0) print("X:\n{}".format(X)) print("y:{}".format(y)) # X: # [[-0.80901699 0.58778525] # [-0.6472136 -0.4702282 ] # [ 0.30901699 -0.95105652] # [ 0.2472136 -0.76084521] # [ 0.30901699 0.95105652] # [ 0.2472136 0.76084521] # [-0.6472136 0.4702282 ] # [-0.80901699 -0.58778525] # [ 1. 0. ] # [ 0.8 0. ]] # y:[0 1 0 1 0 1 1 0 0 1] |
パラメーターの指定
|
1 |
sklearn.datasets.make_circles(n_samples=100, *, shuffle=True, noise=None, random_state=None, factor=0.8) |
n_samples- 総データ数で、奇数の場合は内側のデータが1つ多くなる。2要素のタプルで指定した場合、1つ目が外側、2つ目が内側のデータ数となる。デフォルトは100
shuffle- データをシャッフルするかどうかを指定。Falseにすると、前半がクラス0、後半がクラス1となるように並ぶ。デフォルトはTrue。
noise- ガウス分布のノイズを標準偏差で指定。デフォルトはNoneでノイズなし。
random_state- データを生成する乱数系列を指定。デフォルトはNone
factor- 外側に対する内側のデータのスケールファクター。デフォルトは0.8。
利用例
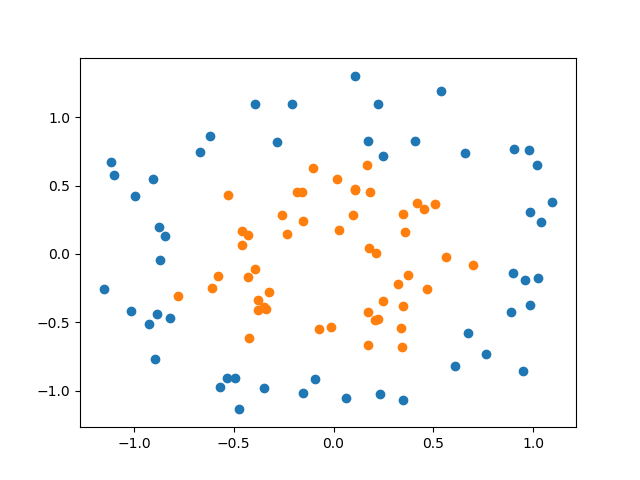
以下はスケールファクターを0.5、ノイズを0.15としてデフォルトの100個のデータを生成した例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_circles X, y = make_circles(factor=0.5, noise=0.15) X0 = X[y==0] X1 = X[y==1] fig, ax = plt.subplots() ax.scatter(X0[:, 0], X0[:, 1]) ax.scatter(X1[:, 0], X1[:, 1]) plt.show() |
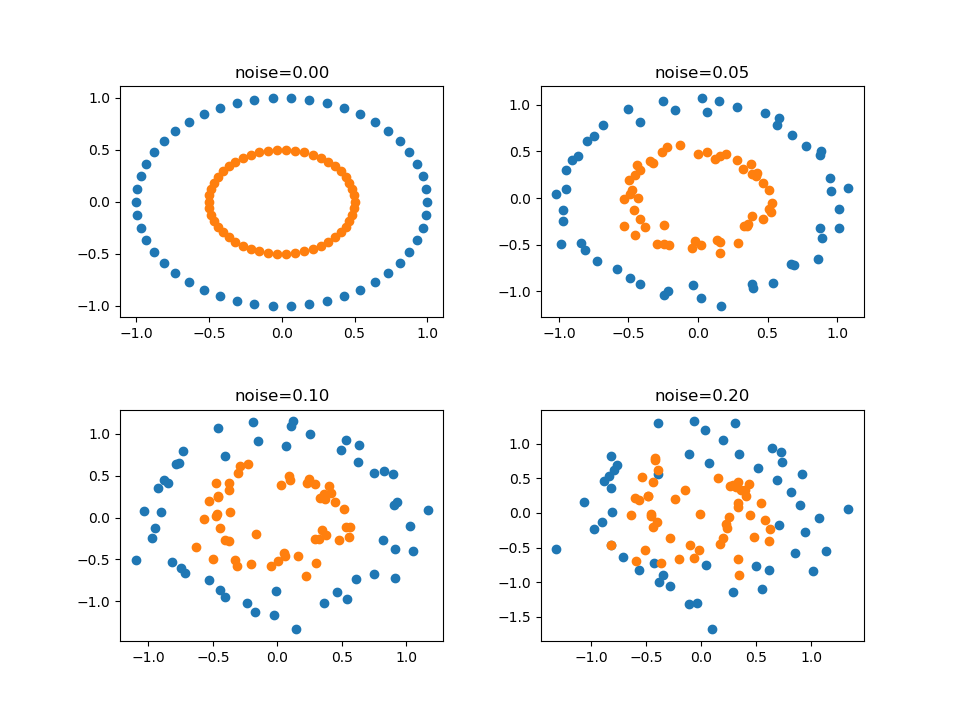
以下はノイズの程度を変化させた例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_circles scale_factors = [0, 0.4, 0.6, 0.8] fig = plt.figure(figsize=(9.6,7.2)) axs = fig.subplots(2, 2) for ax, factor in zip(axs.reshape(axs.size), scale_factors): X, y = make_circles(noise=0.1, factor=factor, random_state=0) ax.scatter(X[y==0][:, 0], X[y==0][:, 1]) ax.scatter(X[y==1][:, 0], X[y==1][:, 1]) ax.set_title("factor={:3.1f}".format(factor)) fig.subplots_adjust(wspace=0.3, hspace=0.4) plt.show() |
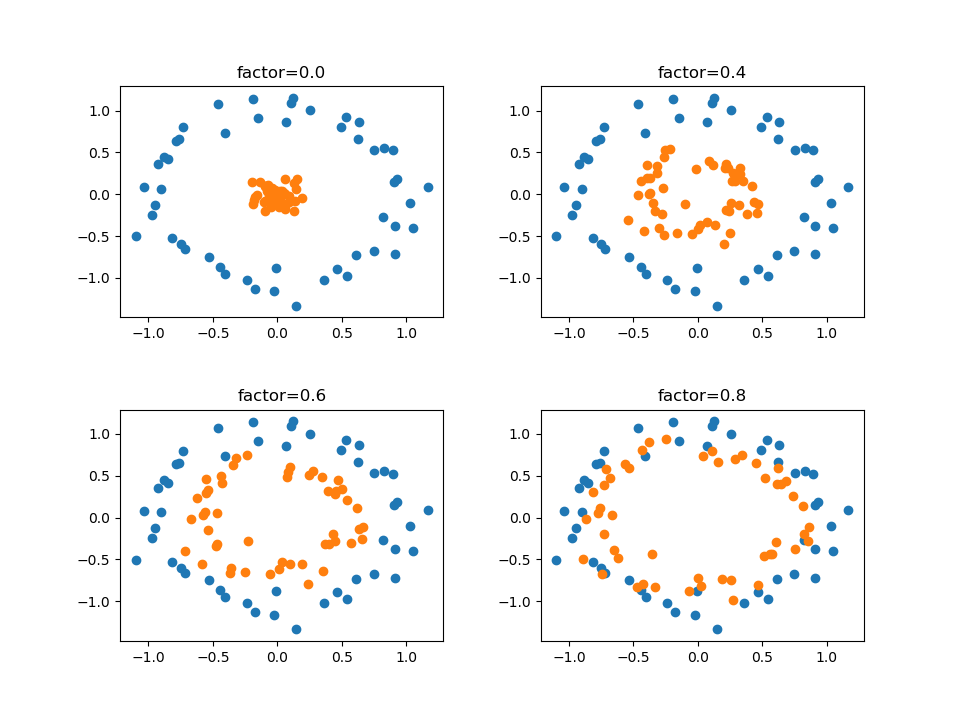
以下はスケールファクターを変化させた例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_circles scale_factors = [0, 0.4, 0.6, 0.8] fig = plt.figure(figsize=(9.6,7.2)) axs = fig.subplots(2, 2) for ax, factor in zip(axs.reshape(axs.size), scale_factors): X, y = make_circles(noise=0.1, factor=factor, random_state=0) ax.scatter(X[y==0][:, 0], X[y==0][:, 1]) ax.scatter(X[y==1][:, 0], X[y==1][:, 1]) ax.set_title("factor={:3.1f}".format(factor)) fig.subplots_adjust(wspace=0.3, hspace=0.4) plt.show() |