概要
sklearn.datasets.make_moons()はクラス分類のためのデータを生成する。上向き、下向きの弧が相互にかみ合う形で生成され、単純な直線では分離できないデータセットを提供する。クラス数は常に2クラス。
得られるデータの形式
2つの配列X, yが返され、配列Xは列が特徴量、行がレコードの2次元配列。ターゲットyはレコード数分のクラス属性値の整数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from sklearn.datasets import make_moons X, y = make_moons(n_samples=10, random_state=0) print("X:\n{}".format(X)) print("y:{}".format(y)) # X: # [[ 6.12323400e-17 1.00000000e+00] # [ 1.70710678e+00 -2.07106781e-01] # [-1.00000000e+00 1.22464680e-16] # [ 2.00000000e+00 5.00000000e-01] # [ 7.07106781e-01 7.07106781e-01] # [ 2.92893219e-01 -2.07106781e-01] # [ 1.00000000e+00 -5.00000000e-01] # [-7.07106781e-01 7.07106781e-01] # [ 1.00000000e+00 0.00000000e+00] # [ 0.00000000e+00 5.00000000e-01]] # y:[0 1 0 1 0 1 1 0 0 1] |
利用例
以下の例では、noiseパラメーターを変化させている。
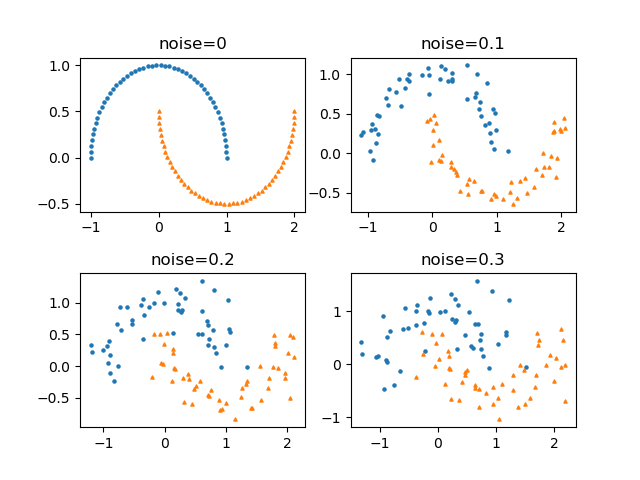
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import matplotlib.pyplot as plt from sklearn.datasets import make_moons noises = [0, 0.1, 0.2, 0.3] fig, axs = plt.subplots(2, 2) axs_1d = axs.reshape(axs.size) for ax, noise in zip(axs_1d, noises): plt.subplots_adjust(hspace=0.4) X, y = make_moons(noise=noise, random_state=0) ax.scatter(X[y==0][:, 0], X[y==0][:, 1], s=5, marker='o') ax.scatter(X[y==1][:, 0], X[y==1][:, 1], s=5, marker='^') ax.set_title("noise={}".format(noise)) plt.show() |
パラメーターの指定
|
1 |
sklearn.datasets.make_moons(n_samples=100, shuffle=True, noise=None, random_state=None) |
n_samples
- 1つの数値で与えた場合は全データ数、2要素のタプルで与えた場合はそれぞれのクラスのデータ数。デフォルトは100。
shuffle- データをシャッフルするかどうか。デフォルトはTrue。
noise- データに加えられるノイズの標準偏差。デフォルトはノイズなし。
random_state- データ生成の乱数系列。