概要
Pythonを使った統計計算と図示の練習のため、コンビニエンスストアで単回帰分析をやってみた。
コンビニの店舗数は「商業動態統計年報」の2016年データを使い、説明変数として2015年の国勢調査人口、2018年の国土地理院による都道府県面積、2017年道路統計年報の道路実延長データを使った。
計算コードは以下の通り。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import numpy as np import matplotlib.pyplot as plt master_data = np.loadtxt('conv-store-data.csv', delimiter=',', skiprows=2, usecols=(1, 2), encoding='utf8') print(master_data) y = num_stores = master_data[:,0] x = population = master_data[:,1] sxy = np.sum((x - x.mean())*(y - y.mean())) sxx = np.sum((x - x.mean())**2) syy = np.sum((y - y.mean())**2) a = sxy / sxx b = y.mean() - a*x.mean() r = sxy / np.sqrt(sxx * syy) n = len(num_stores) ESS = n * sxy**2 / sxx TSS = n * syy R2 = ESS / TSS max_population = 15000000 max_stores = 8000 plt.xlim(0, max_population) plt.ylim(0, max_stores) plt.xlabel('population') plt.ylabel('number of stores') plt.scatter(population, num_stores, label='#stores') x = np.linspace(0, max_population) plt.plot(x, a*x + b, color='m') plt.text(1000000, 7600, 'a = ' + str(a)) plt.text(1000000, 7300, 'b = ' + str(b)) plt.text(1000000, 7000, 'r = '+str(r)) plt.text(1000000, 6700, 'R2 = '+str(R2)) plt.show() |
人口との関係
コンビニ店舗数と人口の散布図と回帰式を以下に示す。
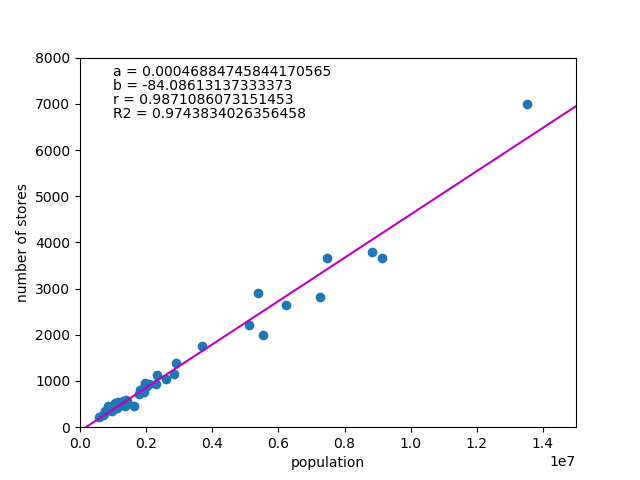
相関係数が極めて高いのは当然で、やはりコンビニの出店計画には人口ファクターが強く作用していることがわかる。
定数項bが店舗数のオーダーに比べてほぼゼロというのも興味深い。
係数aの値からは5万人弱で1店舗ということになるが、人口10万くらいの都市で2店舗しかないことになり、ちょっと少ないような気がする。もしかすると、一定規模以上の市町村単位や都市単位くらいで層化して出店計画を立てているのかもしれない。
面積との関係
店舗数と面積の関係
次に店舗数と都道府県面積の関係を見てみた。
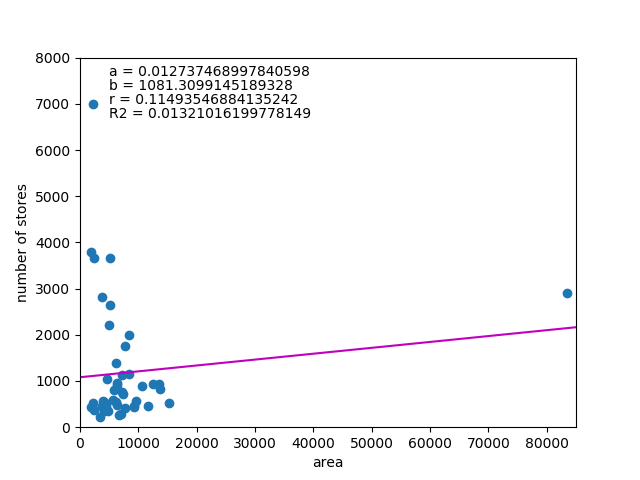
この結果はかなりはずれで、データを見ても人口が少なく面積が群を抜いて大きい北海道の影響を大きく受けている。
ここで、面積が極端に大きい北海道(83423.83㎢~1位、2906店舗~5位)と面積が小さいが集積度が極端に高い東京都(2193.96㎢~45位、7003店舗~1位)の2つを除いて計算してみる。
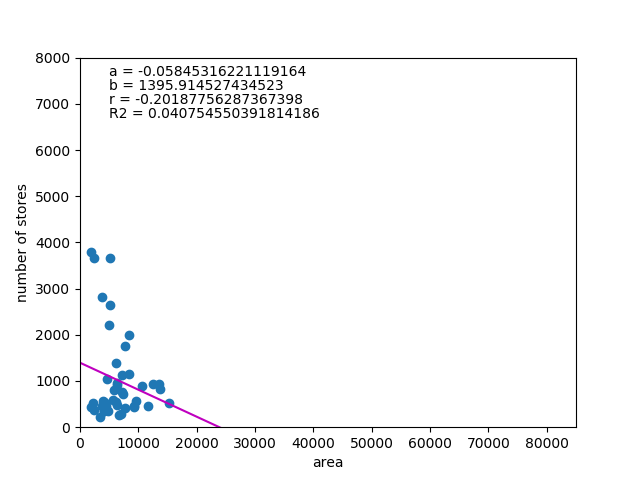
これはさらにおかしな結果で、面積が小さいほど店舗数が多いことになる。
考えてみれば、集客数を期待するなら人口が集積している地域が有利だから、人口密度に比例する可能性を考えた方がいいのかもしれない。もし面積が小さい県の方が集積度が高いと想定すると、面積だけを取り出したときに逆の関係になるとも考えられるが、相関係数や決定係数が小さすぎるので考察は難しい。
人口密度
以下は人口密度との関係。
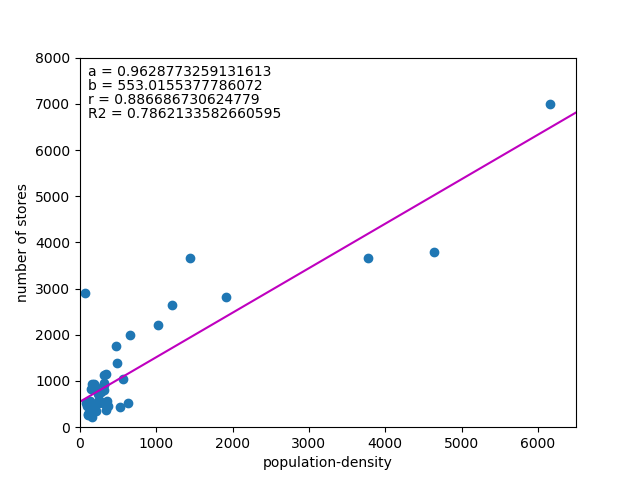
今度はかなりきれいに相関の高さが出ている。
直接的な計算式に入れているかどうかわからないが、GISなどで出店計画を立てるとしたら、人口密度の高いエリアを選んでいくだろうことが想定される。
ただ、店舗数は人口などといった売り上げに直結するデータから導かれるのが普通で、人口密度が高くても人口が少なければ出店インセンティブにはならない。
人口と人口密度の関係
試しに人口を説明変数、人口密度を被説明変数として両者の関係を見てみると、驚くことに「人口が多いほど人口密度が高くなる(あるいはその逆)」という関係になる。
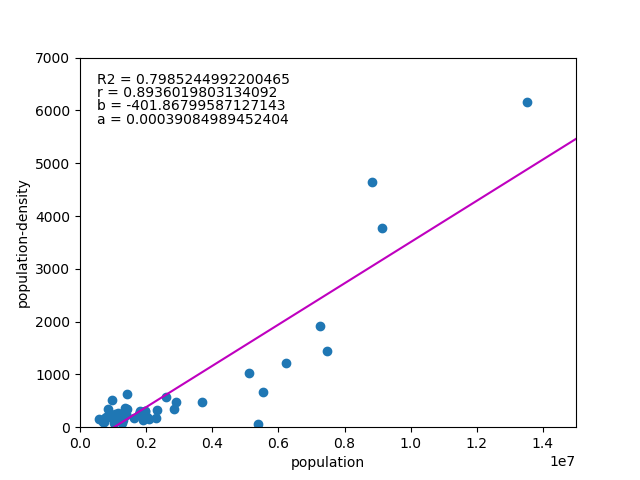
ここから先は人口論や地域論になりそうなので置いておくが、少なくとも日本においては、「狭いところほど人が集まっている傾向がある」ということになりそうである。
もちろんこれは他の国でも一般に当てはまることかもしれないが、朝のラッシュ時に特定の車両に無理やり乗り込んでいる割に離れた車両がすいているとか、1本電車を遅らせたらガラガラだったとか、そのあたりの行動パターンを見ていると、何となく日本に特有のような気がする。
道路延長との関係
最後に道路延長との関係を見てみる。
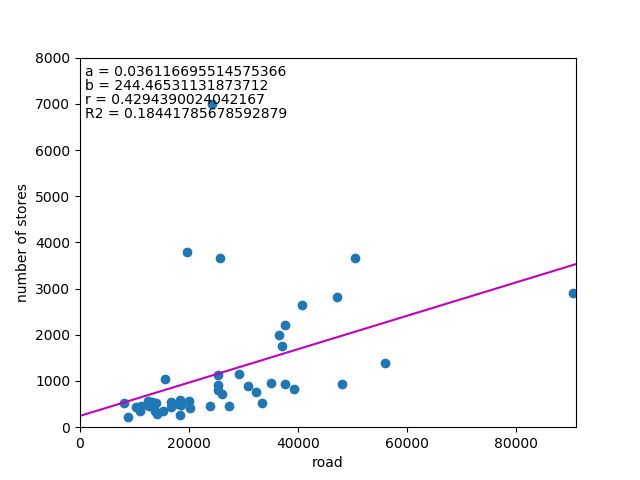
東京のように稠密な都市は例外とすると、概ね関係はありそうである。ただし相関係数、決定係数は高くない。
コンビニ店舗が道路の利便性に依っていることは推測できるが、やはり人口という売り上げ直結のデータに比べると関係は弱い。
高速道路の延長についても見てみたが、こちらはほとんど関係は見られなかった。
ただ、高速道路の延伸に伴ってコンビニエンスストアの店舗数が伸びているようであり、マクロな延長というよりも物流上のインパクトが大きいことは予想される。
 への線形関係を扱うのに対して、重回帰は複数の説明変数
への線形関係を扱うのに対して、重回帰は複数の説明変数 と
と の線形関係を扱う。
の線形関係を扱う。 に対して以下の線形式で最も説明性の高いものを求める。
に対して以下の線形式で最も説明性の高いものを求める。
 の平方和が最小となるような係数
の平方和が最小となるような係数 を最小二乗法により求める。
を最小二乗法により求める。 組が次のように得られているとする。
組が次のように得られているとする。



 ,
,  ,
,  ,
,  とおいて
とおいて












 は対象行列なので転置しても同じ行列となり、行列の微分の公式から以下のようになることを利用している。
は対象行列なので転置しても同じ行列となり、行列の微分の公式から以下のようになることを利用している。

 を消去する。
を消去する。
 、
、 と表している。
と表している。
 と2つの間に完全な線形関係がある場合、分散・共分散の性質から以下の関係が成り立つ。
と2つの間に完全な線形関係がある場合、分散・共分散の性質から以下の関係が成り立つ。
![\begin{align*} &\left[ \begin{array}{ccccccc} V_{11} & \cdots & V_{1i} & \cdots & V_{1j} & \cdots & V_{1m}\\ \vdots && \vdots && \vdots && \vdots\\ V_{i1} & \cdots & V_{ii} & \cdots & V_{ij} & \cdots & V_{im}\\ \vdots && \vdots && \vdots && \vdots\\ V_{j1} & \cdots & V_{ji} & \cdots & V_{jj} & \cdots & V_{jm}\\ \vdots && \vdots && \vdots && \vdots\\ V_{m1} & \cdots & V_{mi} & \cdots & V_{mj} & \cdots & V_{mm} \end{array} \right]\\ &= \left[ \begin{array}{ccccccc} V_{11} & \cdots & V_{1i} & \cdots & aV_{1i} & \cdots & V_{1m}\\ \vdots && \vdots && \vdots && \vdots\\ V_{i1} & \cdots & V_{ii} & \cdots & aV_{ii} & \cdots & V_{im}\\ \vdots && \vdots && \vdots && \vdots\\ aV_{i1} & \cdots & aV_{ii} & \cdots & a^2V_{ii} & \cdots & aV_{im}\\ \vdots && \vdots && \vdots && \vdots\\ V_{m1} & \cdots & V_{mi} & \cdots & aV_{mi} & \cdots & V_{mm} \end{array} \right] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-933b818b8ef3c6cf4b6a70d1805f71a8_l3.png "Rendered by QuickLaTeX.com")