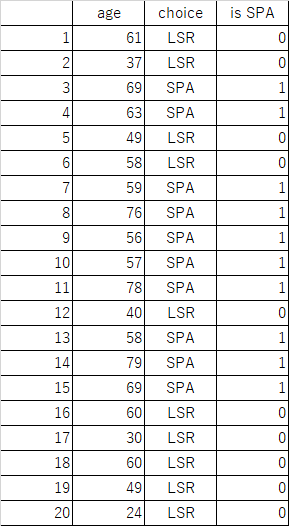
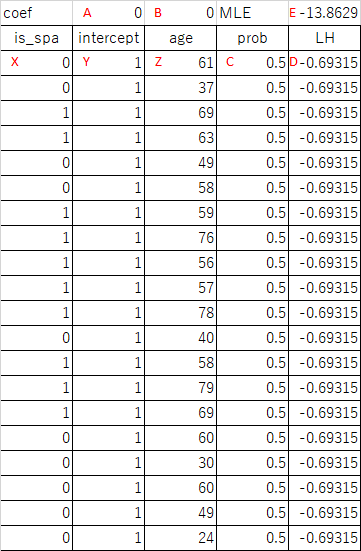
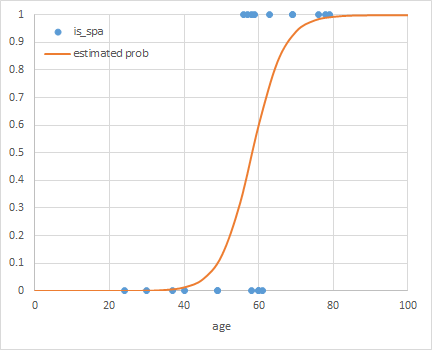
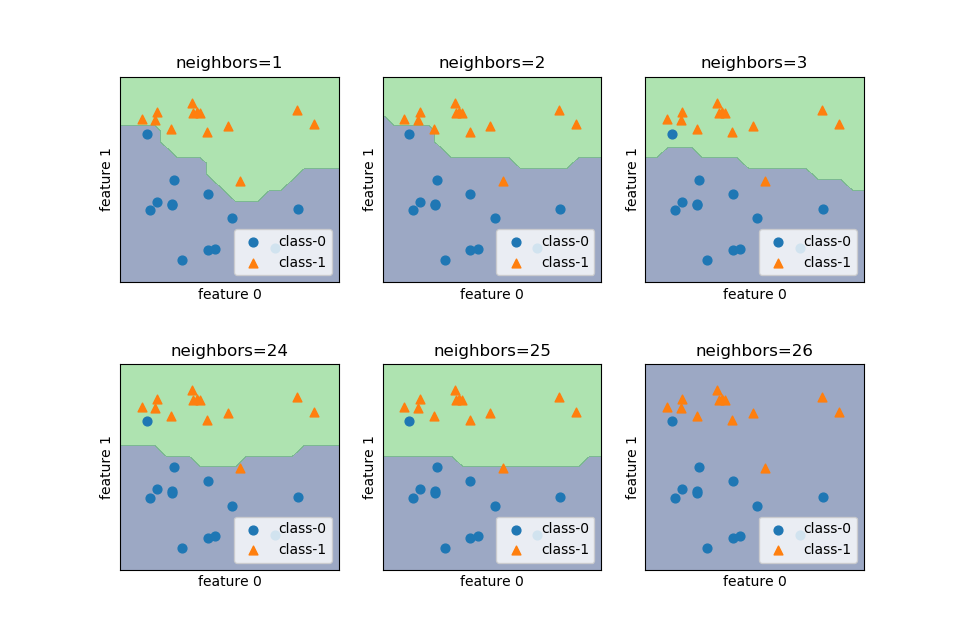
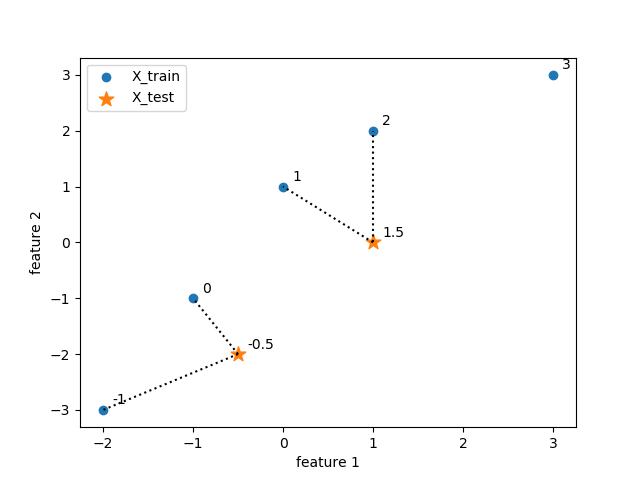
概要
過学習(over fitting)の例として、多項式の係数を線形回帰で予測した場合の挙動をまとめてみた。
複数の点(xi, yi)に対して、以下の線形式の項数を変化させて、Pythonのパッケージ、scikit-learnにあるLinearRegressionでフィッティングさせてみる。
(1) 
データ数が少ない場合
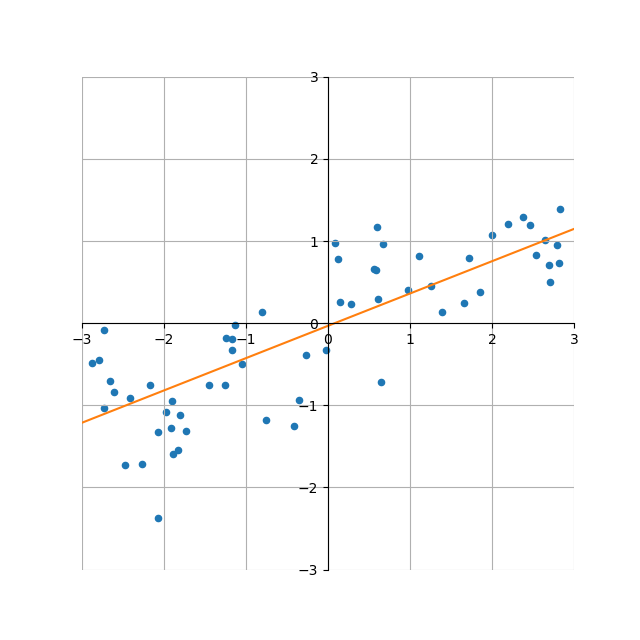
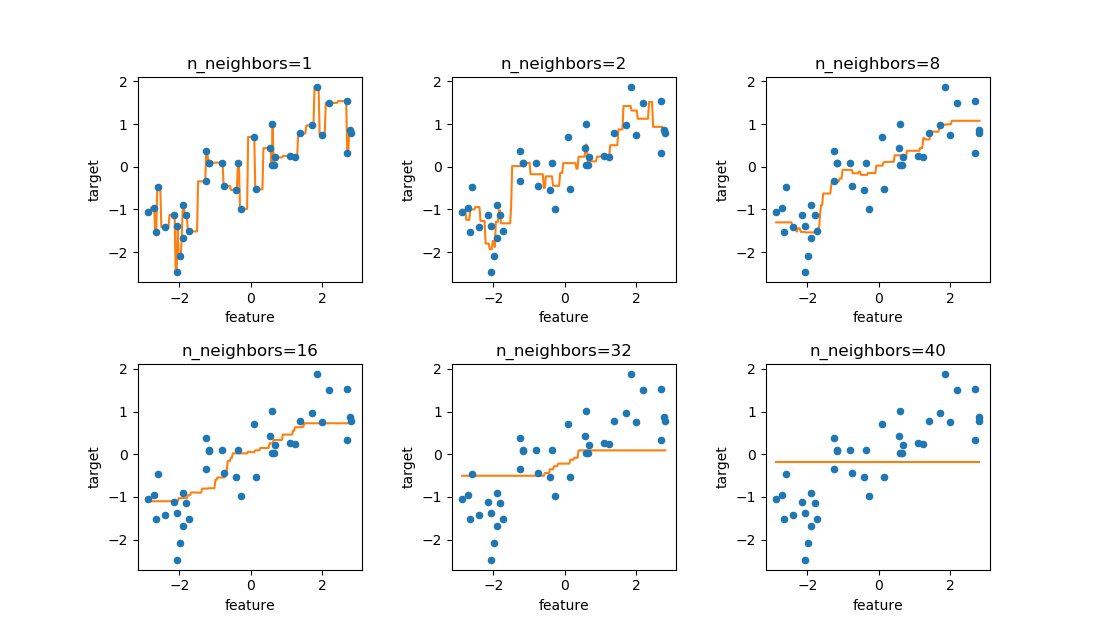
以下の例は、[-3, 1]の間で等間隔な4つの値を発生させ、(x, ex)となる4つの点を準備、これらのデータセットに対して、多項式の項数(すなわちxの次数)を1~6まで変化させてフィッティングした結果。たとえばn_terms=3の場合は の4つの係数を決定することになる。
の4つの係数を決定することになる。
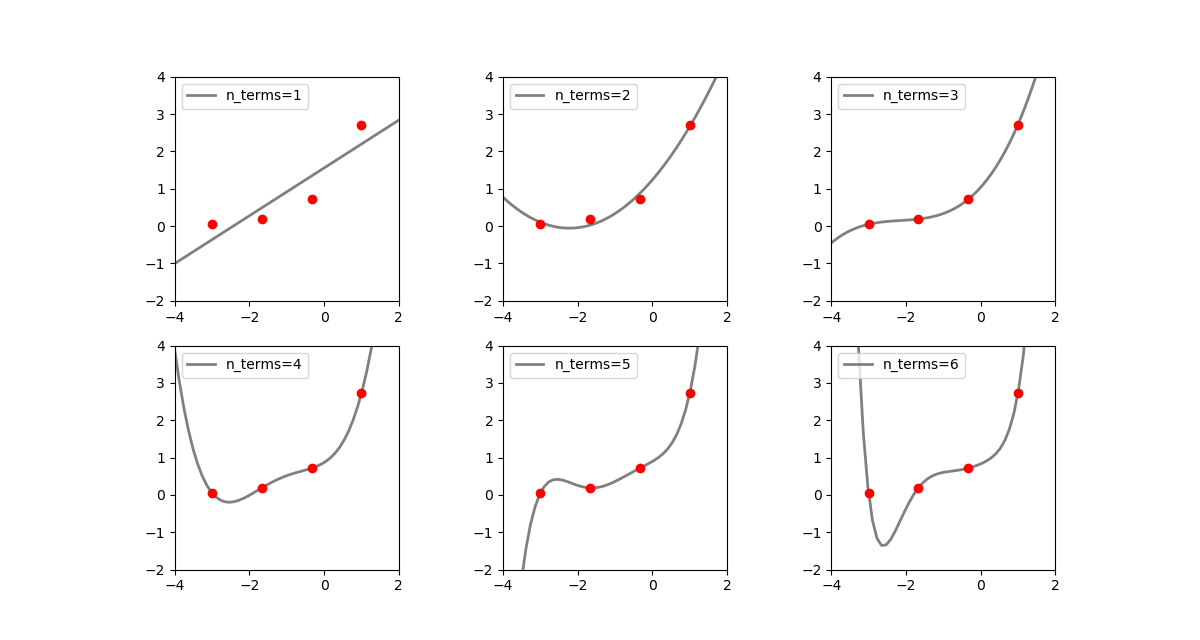
n_terms=1の場合は単純な線形関数で、データセットの曲線関係を表しているとは言えない。n_terms=2になるとかなり各点にフィットしているが、x < −1の範囲で本来の関数の値と離れていく。n_terms=3はデータ数より項数(特徴量の数)が1つ少ない。各点にほぼぴったり合っていて、最も「それらしい」(ただしデータセットの外側の範囲でも合っているとは限らない/指数関数に対してxの有限の多項式ではどこかで乖離していく)n_terms=4はデータ数と項数(特徴量の数)が等しい。予測曲線がすべての点を通っているが、無理矢理合わせている感があり、データセットの左側で関数形が跳ね上がっている。n_terms=5はデータ数より特徴量数の方が多くなる。予測曲線は全ての点を通っているが、1番目の点と2番目の点の間で若干曲線が歪んでいるn_terms=6になると歪が大きくなる
上記の実行コードは以下の通り。
- 7~8行目は、切片・係数のセットとxの値を与えて多項式の値を計算する関数。
- 19行目で
n_data=4個のxの値を発生させ、20行目で指数関数の値を計算している。後のために乱数でばらつかせる準備をしているが、ここではばらつかせていない - 23~24行目でxnの特徴量を生成している
- 35行目で線形回帰モデルのフィッティングを行っている。
n_termsで指定した項数(=次数)までをフィッティングに使っている。 - 36行目で、フィッティングの結果予測された切片と係数を使って、予測曲線の値を計算している。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
import numpy as np import random as rnd import pandas as pd from sklearn.linear_model import LinearRegression import matplotlib.pyplot as plt def poly(intercept, coef, x): return intercept + sum([w * x**(n + 1) for n, w in enumerate(coef)]) rnd.seed(0) xmin, xmax = -3, 1 xlim_min, xlim_max = -4, 2 ylim_min, ylim_max = -2, 4 n_data = 4 n_features = 20 n_terms_list = [1, 2, 3, 4, 5, 6] x = np.linspace(xmin, xmax, n_data) y = np.exp(x) + [rnd.uniform(-0.0, 0.0) for n in range(n_data)] df = pd.DataFrame(y, columns=['y']) for n in range(n_features): df["x^{}".format(n+1)] = x**(n+1) print(df) fig, axs = plt.subplots(2, 3, figsize=(12, 6.4)) axs_1d = axs.reshape(1, -1)[0] linreg = LinearRegression() x_graph = np.linspace(xlim_min, xlim_max) for ax, n_terms in zip(axs_1d, n_terms_list): linreg.fit(df.iloc[:, 1:n_terms+1], df['y']) y_linreg = poly(linreg.intercept_, linreg.coef_, x_graph) ax.scatter(df['x^1'], df['y'], c='r', zorder=10) ax.plot(x_graph, y_linreg, c='gray', linewidth=2, label="n_terms={}".format(n_terms)) ax.set_xlim(xlim_min, xlim_max) ax.set_ylim(ylim_min, ylim_max) ax.set_aspect('equal') ax.legend(loc='upper left') plt.show() |
異常値がある場合
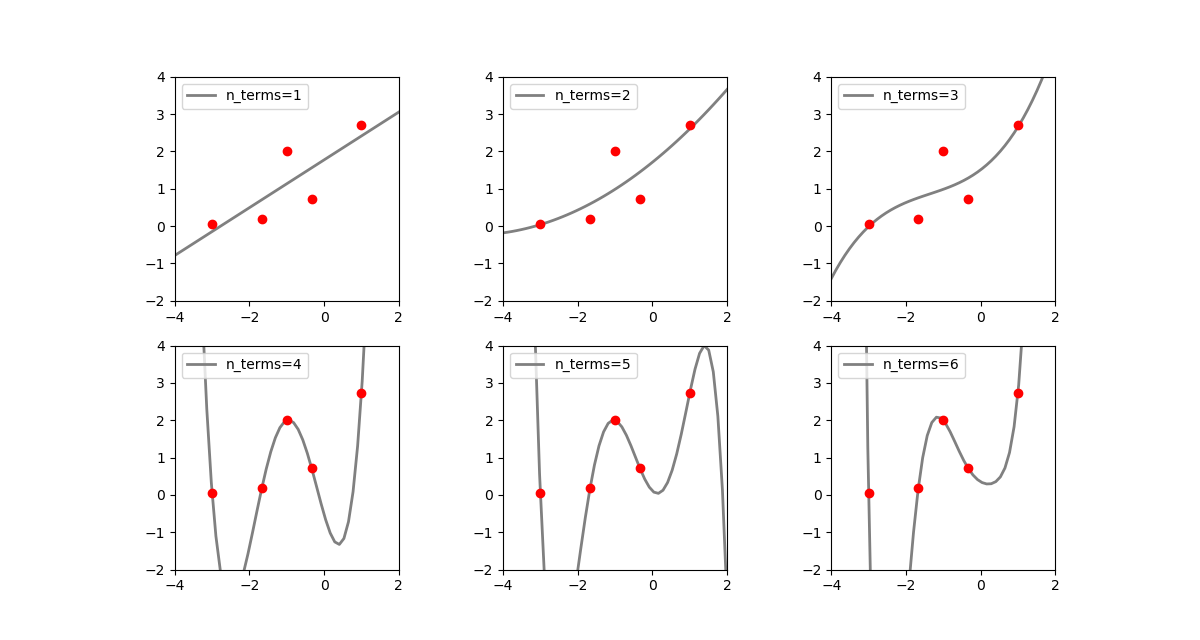
上記の整然とした指数関数のデータに1つだけ飛び離れた異常値を入れてみる。
|
1 2 3 4 |
x = np.linspace(xmin, xmax, n_data) y = np.exp(x) + [rnd.uniform(-0.0, 0.0) for n in range(n_data)] x = np.append(x, -1) y = np.append(y, 2) |
先の例に比べて不安定性=曲線の振動の度合いが大きくなっている。
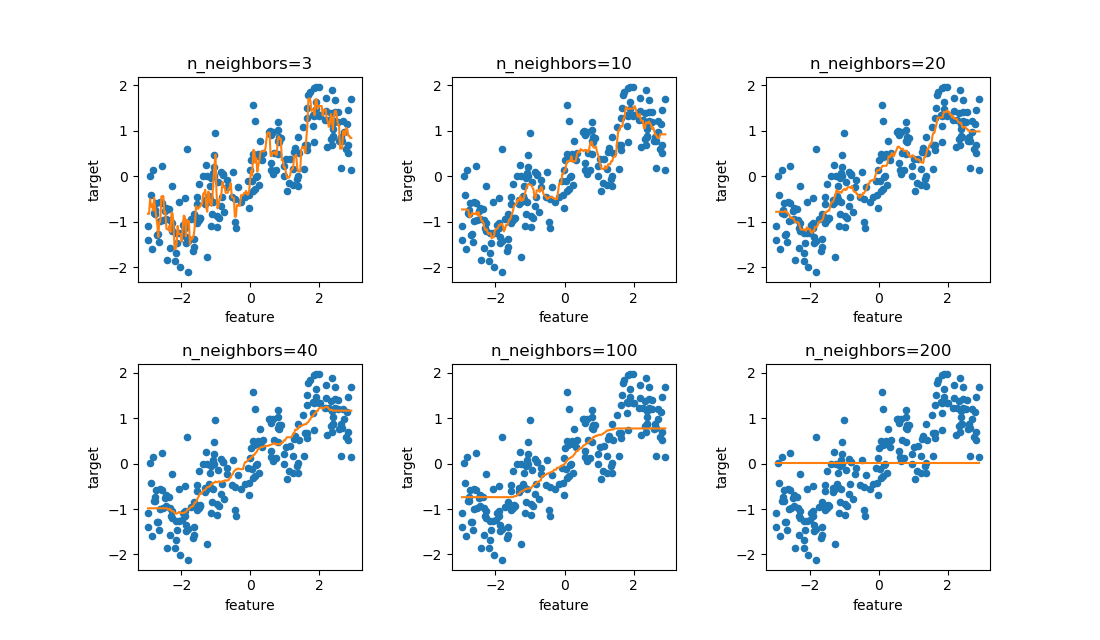
データ数を多くした場合
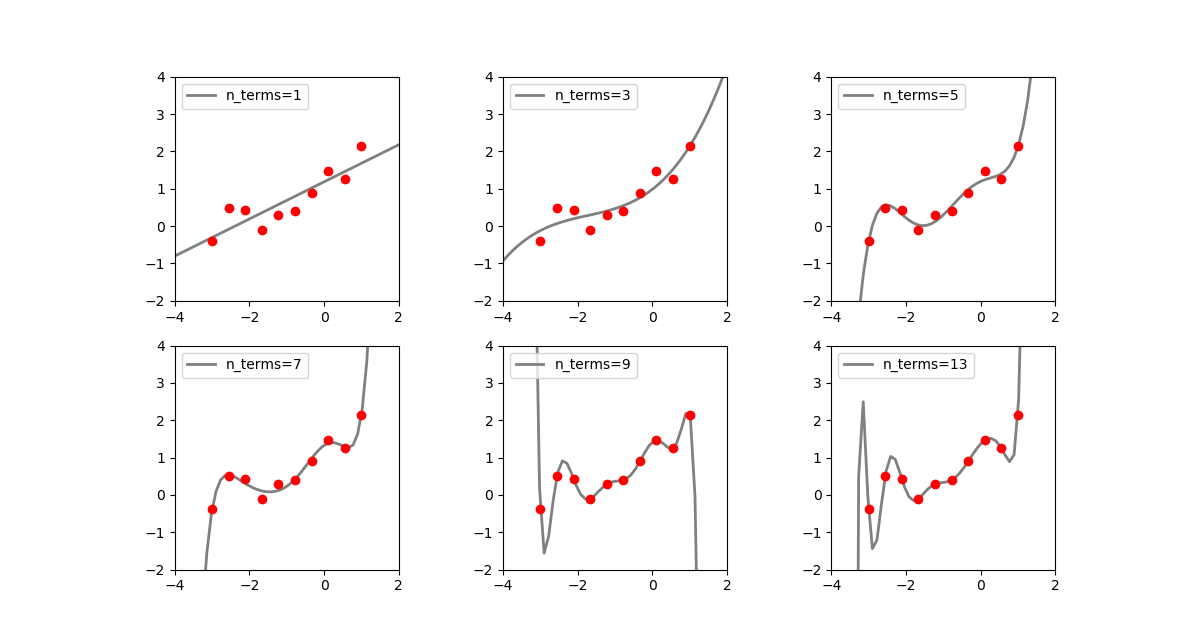
点の数を10個とし、乱数で擾乱を与えてみる(乱数系列も変えている)。
|
1 2 3 4 5 6 7 8 9 10 |
rnd.seed(1) ..... n_data = 10 n_features = 20 n_terms_list = [1, 3, 5, 7, 9, 13] x = np.linspace(xmin, xmax, n_data) y = np.exp(x) + [rnd.uniform(-0.6, 0.6) for n in range(n_data)] |
n_terms=5あたりから、全ての点に何とかフィットさせようと曲線が揺れ始め、特徴量数がデータ数と同じ値となる前後から振動が大きくなっている。





![\begin{equation*} \left[ \begin{array}{cccc} n & S_1 & \cdots & S_m \\ S_1 & S_{11} + \alpha & & S_{1m} \\ \vdots & \vdots & & \vdots \\ S_m & S_{m1} & \cdots & S_{mm} + \alpha \end{array} \right] \left[ \begin{array}{c} w_0 \\ w_1 \\ \vdots \\ w_m \end{array} \right] = \left[ \begin{array}{c} S_y \\S_{1y} \\ \vdots \\ S_{my} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-7e7bba69bc36153a376daa558ddbf28a_l3.png "Rendered by QuickLaTeX.com")
 を消去して、以下の連立方程式を得る。
を消去して、以下の連立方程式を得る。![\begin{align*} &\left[ \begin{array}{ccc} ( S_{11} + \alpha ) - \dfrac{{S_1}^2}{n} & \cdots & S_{1m} - \dfrac{S_1 S_m}{n} \\ \vdots & & \vdots \\ S_{m1} - \dfrac{S_m S_1}{n} & \cdots & ( S_{mm} + \alpha )- \dfrac{{S_2}^2}{n} \end{array} \right] \left[ \begin{array}{c} w_1 \\ \vdots \\ w_m \end{array} \right] \\&= \left[ \begin{array}{c} S_{1y} - \dfrac{S_1 S_y}{n} \\ \vdots \\ S_{my} - \dfrac{S_m S_y}{n} \end{array} \right] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-17a68647af45d80bac08fd44b3135e4c_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \left[ \begin{array}{ccc} V_{11} + \dfrac{\alpha}{n} & \cdots & V_{1m} \\ \vdots & & \vdots \\ V_{m1} & \cdots & V_{mm} + \dfrac{\alpha}{n} \end{array} \right] \left[ \begin{array}{c} w_1 \\ \vdots \\ w_m \end{array} \right] = \left[ \begin{array}{c} V_{1y} \\ \vdots \\ V_{my} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-3a7696ac06d6f37063cc1e74c39f4bab_l3.png "Rendered by QuickLaTeX.com")
 とすると、
とすると、
![\begin{align*} \left[ \begin{array}{ccccccc} V_{11} + \dfrac{\alpha}{n} & \cdots & V_{1i} & \cdots & aV_{1i} & \cdots & V_{1m}\\ \vdots && \vdots && \vdots && \vdots\\ V_{i1} & \cdots & V_{ii} + \dfrac{\alpha}{n} & \cdots & aV_{ii} & \cdots & V_{im}\\ \vdots && \vdots && \vdots && \vdots\\ aV_{i1} & \cdots & aV_{ii} & \cdots & a^2V_{ii} + \dfrac{\alpha}{n} & \cdots & aV_{im}\\ \vdots && \vdots && \vdots && \vdots\\ V_{m1} & \cdots & V_{mi} & \cdots & aV_{mi} & \cdots & V_{mm} + \dfrac{\alpha}{n} \end{array} \right] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-6eff526fb57f5dc6657a032f7dc7da8d_l3.png "Rendered by QuickLaTeX.com")