イベント制御による分析
時刻制御(time driven)では微小な時間間隔の間において到着イベントを確率的に発生させた。そこでは結果としての到着時間間隔の指数分布や到着数のPoisson分布は前提にはおかれていない。
イベント制御(event driven)の考え方では、ある到着があった後、次の到着までの時間間隔を指数分布に従う乱数を発生させて計算する。計算にはR言語を使う。
イベント制御の考え方の概要やその他の考え方についてはRによるポアソン過程のシミュレーションを参照。
到着イベントの時系列
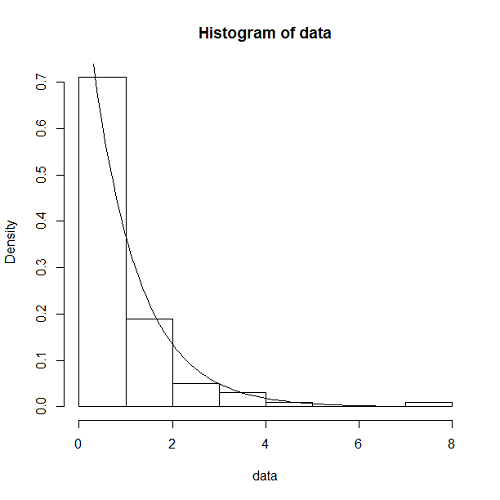
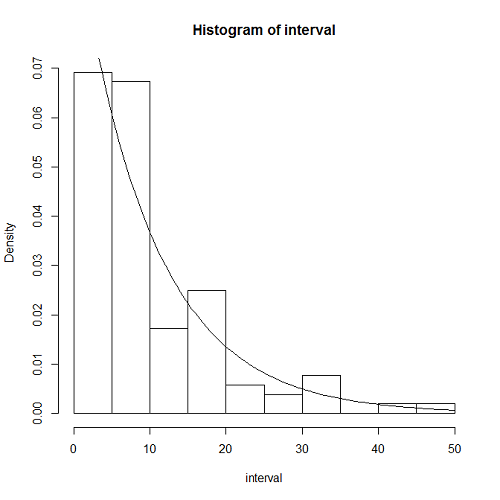
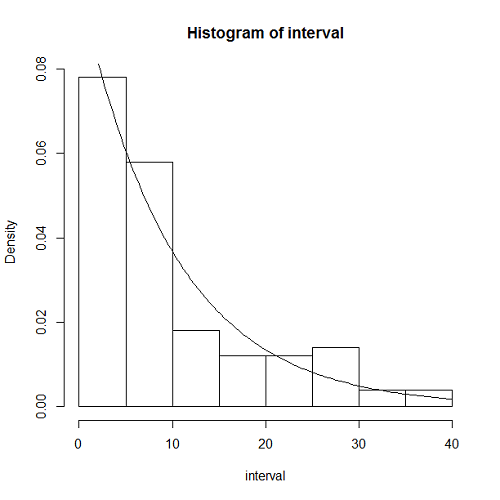
ここでは、到着率はこれまでと同じλ = 1/10として、時刻t = 0からt ≤ 1000秒の間、到着の時間間隔が確率密度 の指数分布に従うような乱数を発生させていく。
の指数分布に従うような乱数を発生させていく。
指数分布に従う乱数を生成するには逆関数法を使う。
指数分布の確率分布関数は以下の通り。
(1) 
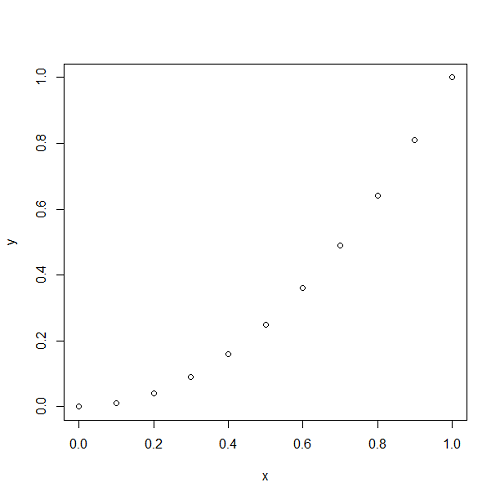
一様乱数runifを与えて指数分布に従う乱数を得るには、一様乱数を分布関数の逆関数に適用すればよい。
(2) 
|
1 2 3 4 5 6 7 |
lambda <- 1/ 10 data <- c() for (i in 1:1000) { r <- (1 - log(runif(1))) / lambda data <- c(data, r) } |
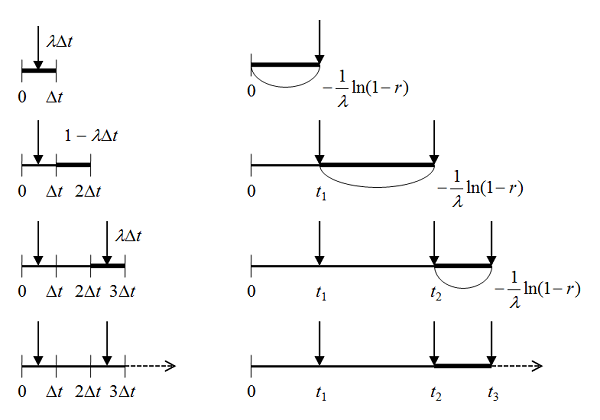
時刻0を起点として、1番目の到着時刻をこの指数乱数で決定し、その次の到着時刻も指数乱数で・・・と繰り返して、時刻が上限を超えるまで時系列として記録する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
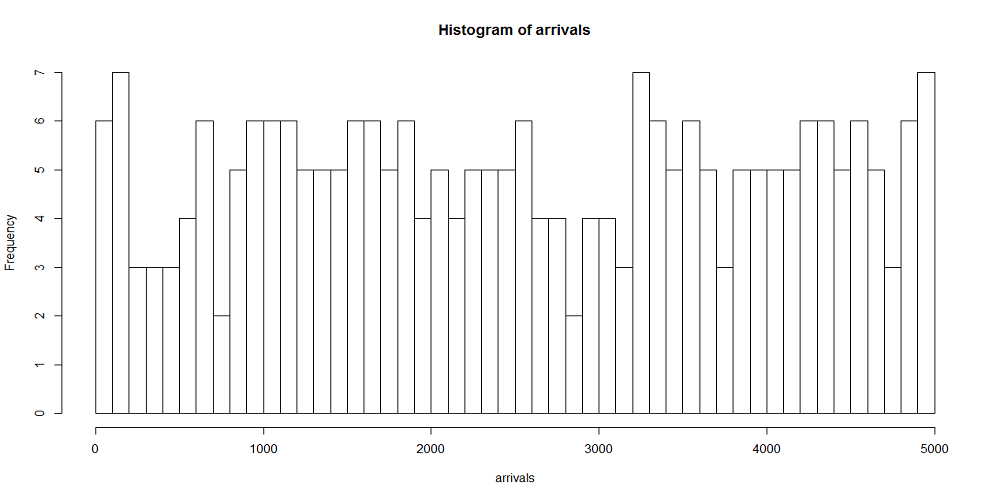
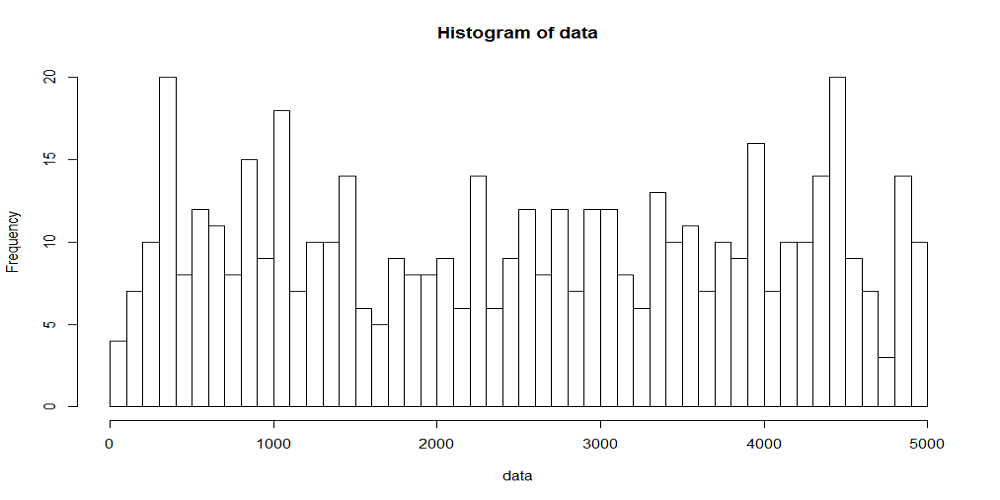
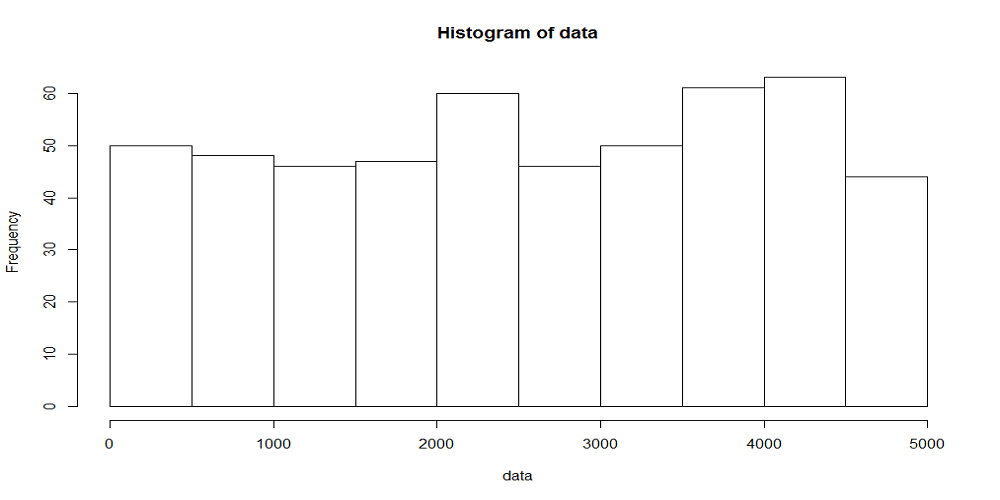
interval <- function(lambda) return( (1 - log(runif(1))) / lambda ) lambda <- 1/ 10 t.obs <- 5000 rank.width <- 100 t <- 0 arrivals <- c() while (t < t.obs) { arrivals <- c(arrivals, t) t <- t + interval(lambda) } hist(arrivals, breaks=seq(0, t.obs, rank.width)) |
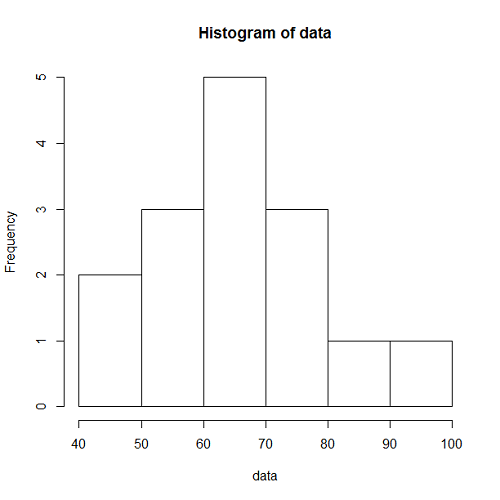
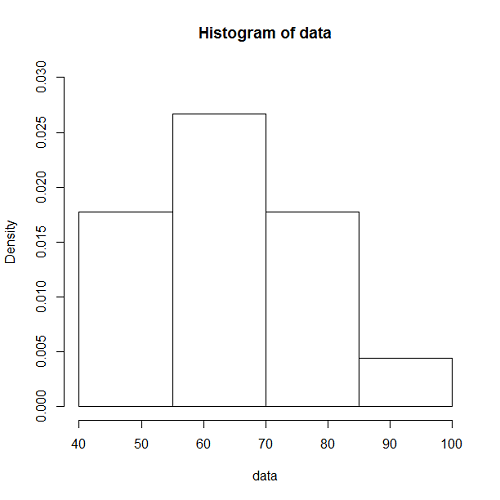
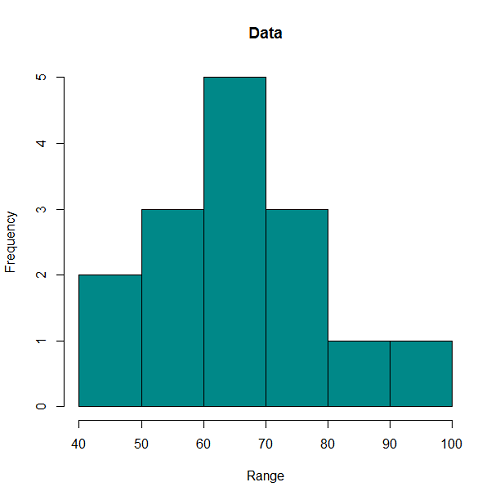
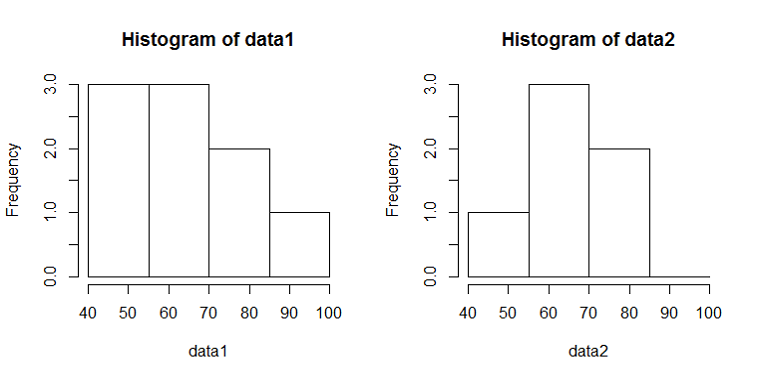
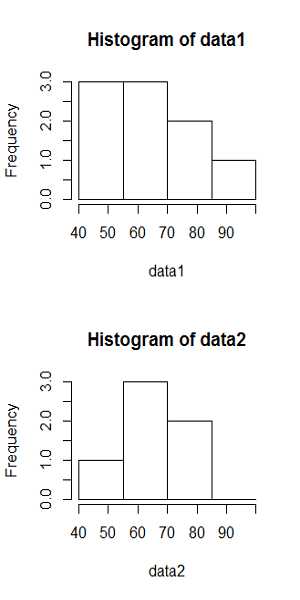
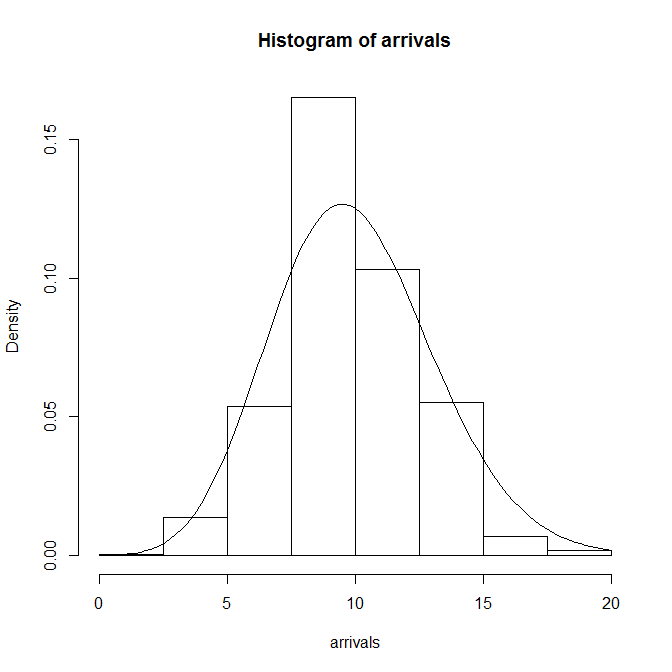
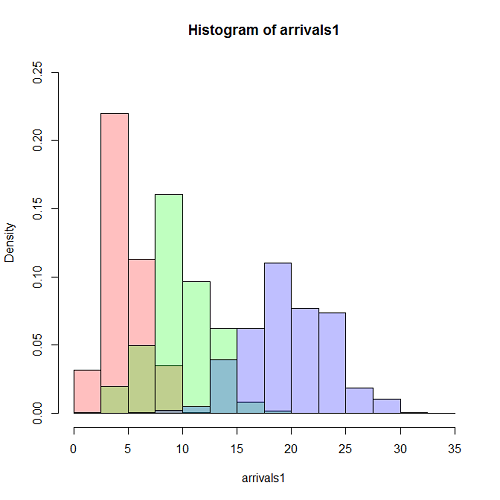
一様乱数による場合と同じく、到着率1/10、観測時間5000秒として、階級幅100秒、500秒の場合の時系列を生成したのが下図。階級あたりのデータ数と分布の平滑さの関係は、一様乱数による場合やtime drivenの場合と同じ。
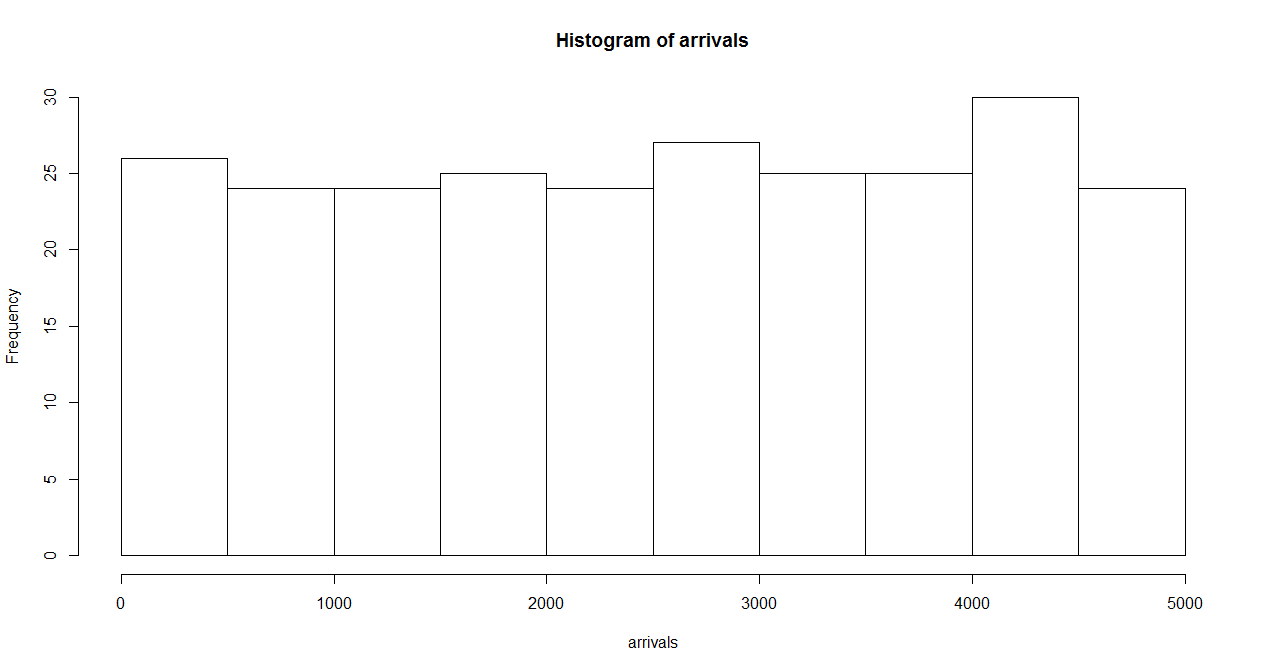
到着数の分布
到着数の確率分布は、一様乱数による場合やtime drivenと同じように集計する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
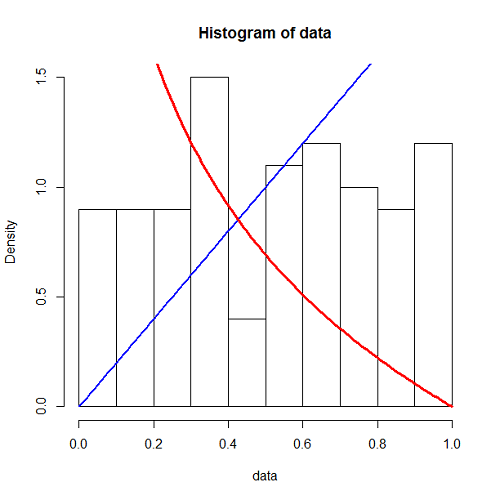
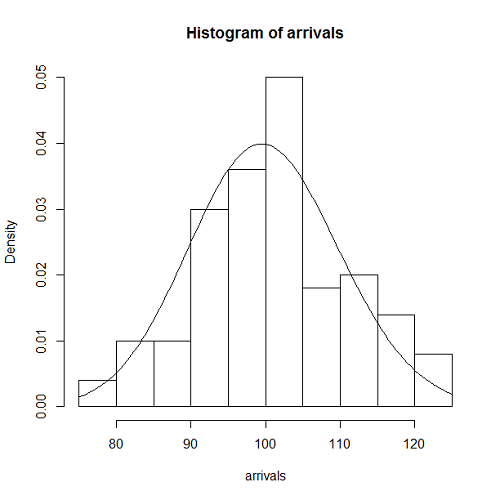
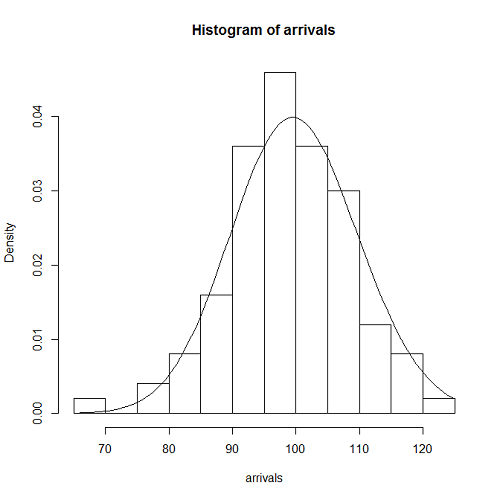
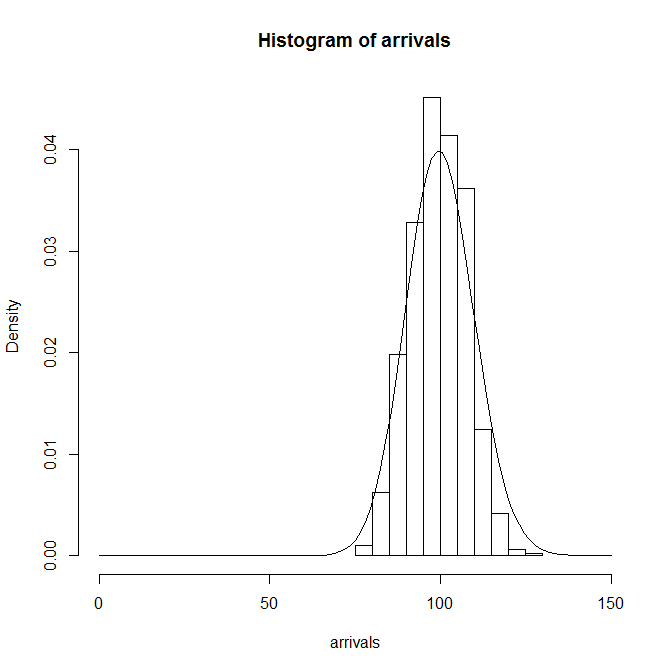
interval <- function(lambda) return( -log(1 - runif(1)) / lambda ) generate <- function(t.obs, lambda) { t <- 0 data <- c() while (t < t.obs) { data <- c(data, t) t <- t + interval(lambda) } return (length(data)) } lambda <- 1/ 10 t.obs <- 1000 n.loop <- 100 arrivals <- rep(0, n.loop) for (i in 1:n.loop) arrivals[i] <- (generate(t.obs, lambda)) hist(arrivals, freq=FALSE) curve((lambda*t.obs)^x/factorial(x)*exp(-lambda*t.obs), add=TRUE) |
結果は、Poisson分布の理論式ともよくあっている。
関連リンク
 となる。この条件下で、以下のことを確認する。
となる。この条件下で、以下のことを確認する。
 が確率分布
が確率分布 に、確率変数
に、確率変数 が
が 上の一様分布に従うとする。このとき
上の一様分布に従うとする。このとき は確率分布
は確率分布 に従う。
に従う。



 とおくと、
とおくと、 だから、
だから、
 が確率分布
が確率分布 に従うことを意味している。
に従うことを意味している。
 に一様乱数列を入れることで、計算結果は指数分布に従う乱数列として得られる。
に一様乱数列を入れることで、計算結果は指数分布に従う乱数列として得られる。