概要
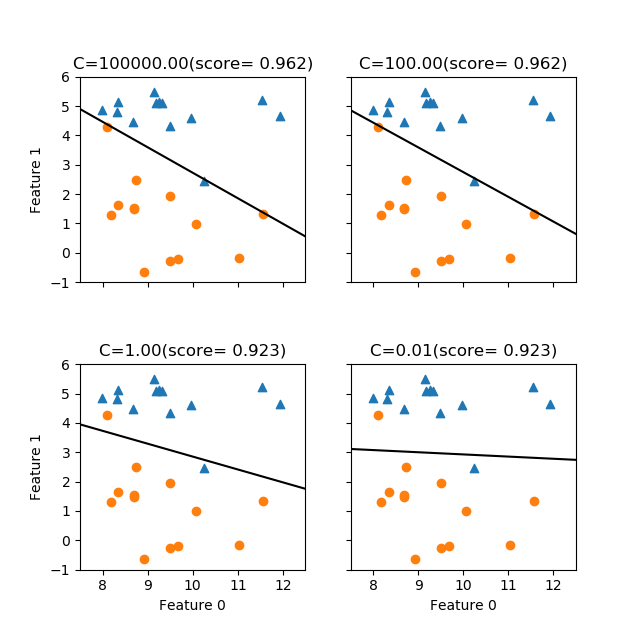
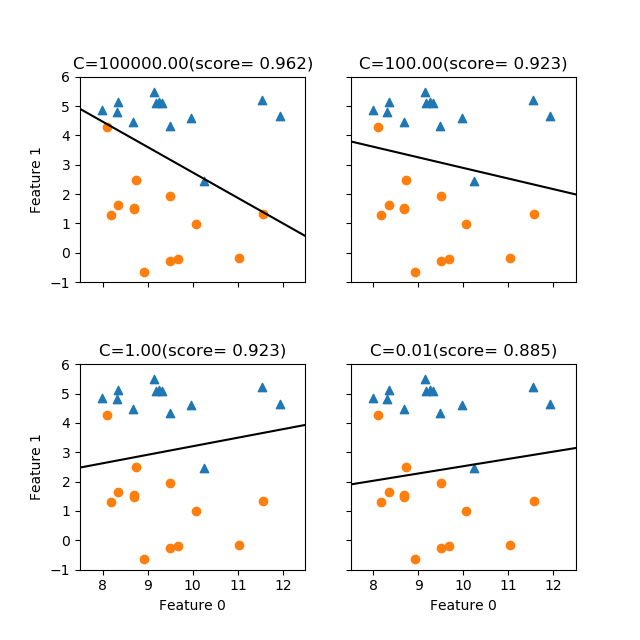
scikit-learnのLogisticRegressionモデルはLogistic回帰のモデルを提供する。利用方法の概要は以下の手順で、LinearRegressionなど他の線形モデルとほぼ同じだが、モデルインスタンス生成時に与える正則化パラメーターCはRidge/Lassoのalphaと逆で、正則化の効果を強くするにはCを小さくする(Cを大きくすると正則化が弱まり、訓練データに対する精度は高まるが過学習の可能性が高くなる)。
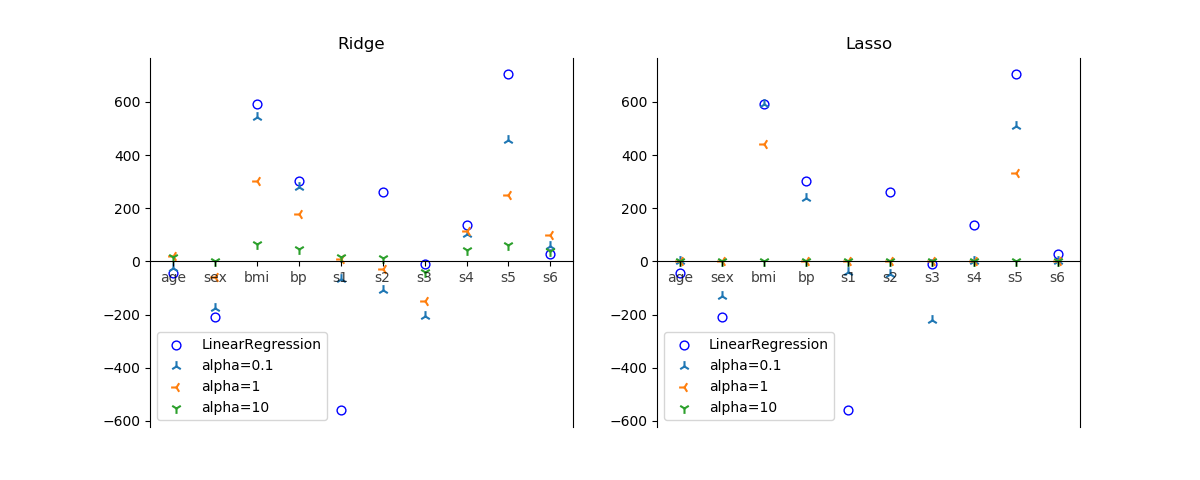
また、正則化の方法をL1正則化、L2正則化、Elastic netから選択できる。
LogisticRegressのクラスをインポートする- ハイパーパラメーター
C、正則化方法、solver(収束計算方法)などを指定し、モデルのインスタンスを生成する fit()メソッドに訓練データを与えて学習させる
学習済みのモデルの利用方法は以下の通り。
score()メソッドにテストデータを与えて適合度を計算するpredict()メソッドに説明変数を与えてターゲットを予測- モデルインスタンスのプロパティーからモデルのパラメーターを利用
- 切片は
intercept_、重み係数はcoef_(末尾のアンダースコアに注意)
- 切片は
利用例
以下は、breast_cancerデータセットに対してLogisticRegressionを適用した例。デフォルトのsolverは'lbfgs'でデフォルトの最大収束回数(100)では収束しなかったため、max_iter=3000を指定している。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression ds = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split( ds.data, ds.target, stratify=ds.target, random_state=42) logreg = LogisticRegression(max_iter=3000).fit(X_train, y_train) print("") print("Training score: {}".format(logreg.score(X_train, y_train))) print("Test score : {}".format(logreg.score(X_test, y_test))) print("Prediction") for i in range(3): print("{} -> {}".format(y_test[i], logreg.predict(X_test[i].reshape(1, -1)))) # Training score: 0.9577464788732394 # Test score : 0.958041958041958 # Prediction # 1 -> [1] # 0 -> [0] # 1 -> [1] |
利用方法
LogisticRgressionの主な利用方法はLineaRegressionとほとんど同じで、以下は特有の設定を中心にまとめる。
モデルクラスのインポート
scikit-learn.linear_modelパッケージからLogisticRegressonクラスをインポートする。
|
1 |
from sklearn.linear_model import LogisticRegression |
モデルのインスタンスの生成
LogisticRegressionでは、ハイパーパラメーターCによって正則化の強さを指定する。このCはRidge/Lassoのalphaと異なり、正則化の効果を強めるためには値を小さくする。デフォルトはC=1.0。
|
1 2 3 4 |
logreg = LogisticRegression(penalty='l2', *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, warm_start=False, n_jobs=None, l1_ratio=None) |
以下、RidgeとLassoに特有のパラメーターのみ説明。LinearRegressionと共通のパラメーターはLinearRegressionを参照。
penalty'l1','l2','elasticnet','none'で正則化項のノルムのタイプを指定する。ソルバーの'newton-cg','sag','lbfgs'はL2正則化のみサポートし、'elasticnet'は'saga'のみがサポートする。デフォルトは'none'で正則化は適用されない('liblinear'は'none'に対応しない)。tol- 収束計算の解の精度で、デフォルトは1e-4。
C- 正則化の強さの逆数。正の整数で指定し、デフォルトは1.0。
solver'newton-cg'、'lbfgs'、'liblinear'、'sag'、'saga'のうちから選択される。デフォルトは'lbfgs'。小さなデータセットには'liblnear'が適し、大きなデータセットに対しては'sag'、'saga'の計算が速い。複数クラスの問題には、'newton-cg'、'sag'、'saga'、'lbfgs'が対応し、'liblinear'は一対他しか対応しない。その他ノルムの種類とソルバーの対応。max_iter- 収束計算の制限回数を指定する。デフォルト値は100。
random_state- データをシャッフルする際のランダム・シードで、
solver='sag'の際に用いる。 l1_ratio- Elastic-Netのパラメーター。[0, 1]の値で、
penalty='elasticnet'の時のみ使われる。
モデルの学習
fit()メソッドに特徴量とターゲットの訓練データを与えてモデルに学習させる(回帰係数を決定する)。
|
1 |
lr.fit(X, y) |
X- 特徴量の配列。2次元配列で、各列が各々の説明変数に対応し、行数はデータ数を想定している。変数が1つで1次元配列の時は
reshape(-1, 1)かスライス([:, n:n+1])を使って1列の列ベクトルに変換する必要がある。 y- ターゲットの配列で、通常は1変数で1次元配列。
3つ目の引数sample_weightは省略。
適合度の計算
score()メソッドに特徴量とターゲットを与えて適合度を計算する。
|
1 |
lr.score(X, y) |
その他のメソッド
decision_function(X)densiffy()predict_proba(X)predict_log_proba()sparsify()


![\begin{equation*} \boldsymbol{X} = \left[ \begin{array}{ccc} x_{11} & \cdots & x_{m1} \\ \vdots & & \vdots \\ x_{1n} & \cdots & x_{mn} \\ \end{array} \right] \left[ \begin{array}{c} y_1 \\ \vdots \\ y_n \end{array} \right] \quad \Rightarrow \quad y = f(\boldsymbol{x}) \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-5b14ad219de55ad4863d239600cada5a_l3.png "Rendered by QuickLaTeX.com")






 の4つの係数を決定することになる。
の4つの係数を決定することになる。


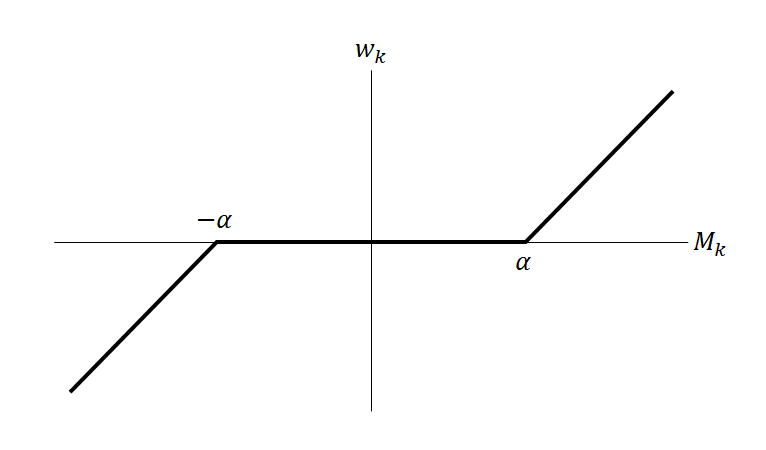
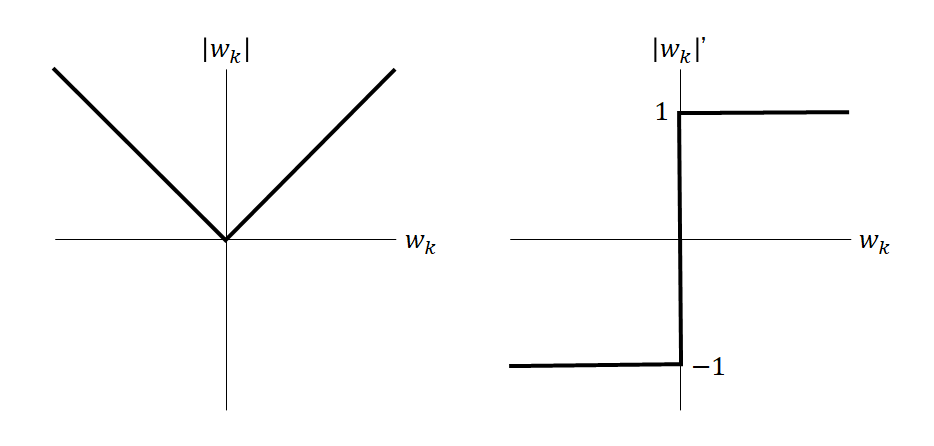
 と表し、左辺のwk以外に関わる項をMk、wkの係数となっている2乗和をSkkと表す。
と表し、左辺のwk以外に関わる項をMk、wkの係数となっている2乗和をSkkと表す。




![\begin{equation*} \frac{d |x|}{dx} = \left\{ \begin{array}{cl} -1 & (x < 0) \\ \left[ -1, 1 \right] & (x = 0) \\ 1 & (x > 0) \end{array} \right. \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-1aadd0e8e3a8da8daf0db2c69a068fd7_l3.png "Rendered by QuickLaTeX.com")
![\begin{gather*} w_k = 0 \quad \rightarrow \quad M_k +w_k S_{kk} + \alpha \left[ -1, 1 \right] = \left[ M_k - \alpha , M_k + \alpha \right] = 0\\ M_k - \alpha \le 0 \le M_k + \alpha \quad \rightarrow \quad -\alpha \le M_k \le \alpha \quad \rightarrow \quad w_k = 0 \end{gather*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-567b5403ac4d6ca5907d235f1b760dcc_l3.png "Rendered by QuickLaTeX.com")