概要
scikit-learnのLinearRegressionは、最も単純な多重線形回帰モデルを提供する。
モデルの利用方法の概要は以下の手順。
LinearRegressionのクラスをインポートする- モデルのインスタンスを生成する
fit()メソッドに訓練データを与えて学習させる
学習済みのモデルの利用方法は以下の通り。
score()メソッドにテストデータを与えて適合度を計算するpredict()メソッドに説明変数を与えてターゲットを予測- モデルインスタンスのプロパティーからモデルのパラメーターを利用
- 切片は
intercept_、重み係数はcoef_(末尾のアンダースコアに注意)
- 切片は
利用例
配列による場合
以下はscikit-learnのBoston hose pricesデータのうち、2つの特徴量RM(1戸あたり部屋数)とLSTAT(下位層の人口比率)を取り出して、線形回帰のモデルを適用している。
特徴量の一部をとりだすのに、ファンシー・インデックスでリストの要素に2つの変数のインデックスを指定している。また、特徴量データXとターゲットデータyをtrain_test_split()を使って訓練データとテストデータに分けている。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression ds = load_boston() X = ds.data[:, [5, 12]] y = ds.target X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) lr = LinearRegression() lr.fit(X_train, y_train) print("Score:{}".format(lr.score(X_test, y_test))) print("Prediction for (7, 5):{}".format(lr.predict([[7, 5]]))) print("Intercept:{}".format(lr.intercept_)) print("Coefficients:{}".format(lr.coef_)) # Score:0.5692445415835343 # Prediction for (7, 5):[31.14766768] # Intercept:-0.6047107435077521 # Coefficients:[ 5.01785312 -0.67451869] |
DataFrameによる場合
以下の例では、データセットの本体(data)をpandasのDataFrameとして構成し、2つの特徴量RMとLSTATを指定して取り出している。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import pandas as pd from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression ds = load_boston() df = pd.DataFrame(ds.data, columns=ds.feature_names) X = df[['RM', 'LSTAT']] y = ds['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) lr = LinearRegression() lr.fit(X_train, y_train) print("Score:{}".format(lr.score(X_test, y_test))) print("Prediction for (7, 5):{}".format(lr.predict([[7, 5]]))) print("Intercept:{}".format(lr.intercept_)) print("Coefficients:{}".format(lr.coef_)) # Score:0.5692445415835343 # Prediction for (7, 5):[31.14766768] # Intercept:-0.6047107435077521 # Coefficients:[ 5.01785312 -0.67451869] |
利用方法
モデルクラスのインポート
scikit-learn.linear_modelパッケージからLinearRegressionクラスをインポートする。
|
1 |
from sklearn.linear_model import LinearRegression |
モデルのインスタンスの生成
LinearRegressionの場合、ハイパーパラメーターの指定はない。
|
1 |
lr = LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=None) |
fit_intercept- 切片を計算しない場合
Falseを指定。デフォルトはTrueで切片も計算されるが、原点を通るべき場合にはFalseを指定する。 normalizeTrueを指定すると、特徴量Xが学習の前に正規化(normalize)される(平均を引いてL2ノルムで割る)。デフォルトはFalse。fit_intercept=Falseにセットされた場合は無視される。説明変数を標準化(standardize)する場合はこの引数をFalseにしてsklearn.preprocessing.StandardScalerを使う。copy_XTrueを指定するとXはコピーされ、Falseの場合は上書きされる。デフォルトはTrue。n_jobs- 計算のジョブの数を指定する。デフォルトはNoneで1に相当。n_targets > 1のときのみ適用される。
モデルの学習
fit()メソッドに特徴量とターゲットの訓練データを与えてモデルに学習させる(回帰係数を決定する)。
|
1 |
lr.fit(X, y) |
X- 特徴量の配列。2次元配列で、各列が各々の説明変数に対応し、行数はデータ数を想定している。変数が1つで1次元配列の時は
reshape(-1, 1)かスライス([:, n:n+1])を使って1列の列ベクトルに変換する必要がある。 y- ターゲットの配列で、通常は1変数で1次元配列。
3つ目の引数sample_weightは省略。
適合度の計算
score()メソッドに特徴量とターゲットを与えて適合度を計算する。
|
1 |
lr.score(X, y) |
戻り値は適合度を示す実数で、回帰計算の決定係数R2で計算される。
(1) 
モデルによる予測
predict()メソッドに特徴量を与えて、ターゲットの予測結果を得る。
|
1 |
y_pred = lr.predict(X) |
ここで特徴量Xは複数のデータセットの2次元配列を想定しており、1組のデータの場合でも2次元配列とする必要がある。
|
1 |
y_pred = lr.pred([[x1, x2,..., xm]]) |
また、結果は複数のデータセットに対する1次元配列で返されるため、ターゲットが1つの場合でも要素数1の1次元配列となる。
切片・係数の利用
fit()メソッドによる学習後、モデルの学習結果として切片と特徴量に対する重み係数を得ることができる。
各々モデル・インスタンスのプロパティーとして保持されており、切片はintercept_で1つの実数、重み係数はcoeff_で特徴量の数と同じ要素数の1次元配列となる(特徴量が1つの場合も要素数1の1次元配列)。
|
1 2 |
ic = lr.intercept_ cf = lr.coef_ |
末尾のアンダースコアに注意。
実行例


 と表し、左辺のwk以外に関わる項をMk、wkの係数となっている2乗和をSkkと表す。
と表し、左辺のwk以外に関わる項をMk、wkの係数となっている2乗和をSkkと表す。




![\begin{equation*} \frac{d |x|}{dx} = \left\{ \begin{array}{cl} -1 & (x < 0) \\ \left[ -1, 1 \right] & (x = 0) \\ 1 & (x > 0) \end{array} \right. \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-1aadd0e8e3a8da8daf0db2c69a068fd7_l3.png "Rendered by QuickLaTeX.com")
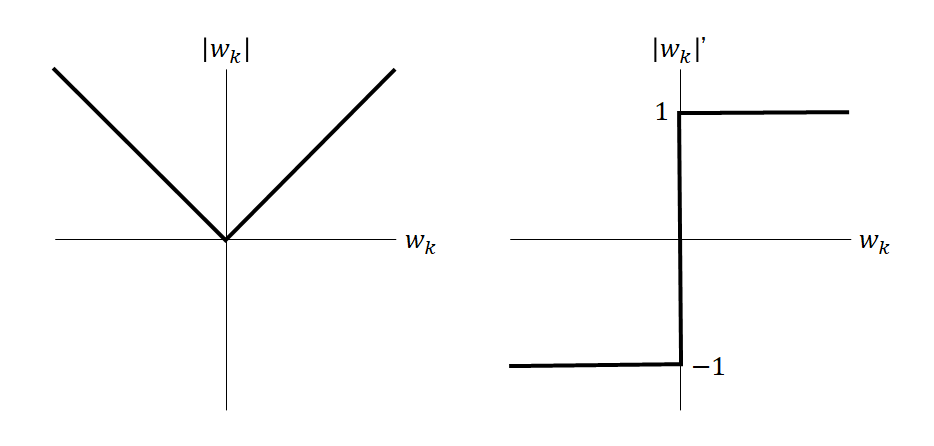
![\begin{gather*} w_k = 0 \quad \rightarrow \quad M_k +w_k S_{kk} + \alpha \left[ -1, 1 \right] = \left[ M_k - \alpha , M_k + \alpha \right] = 0\\ M_k - \alpha \le 0 \le M_k + \alpha \quad \rightarrow \quad -\alpha \le M_k \le \alpha \quad \rightarrow \quad w_k = 0 \end{gather*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-567b5403ac4d6ca5907d235f1b760dcc_l3.png "Rendered by QuickLaTeX.com")

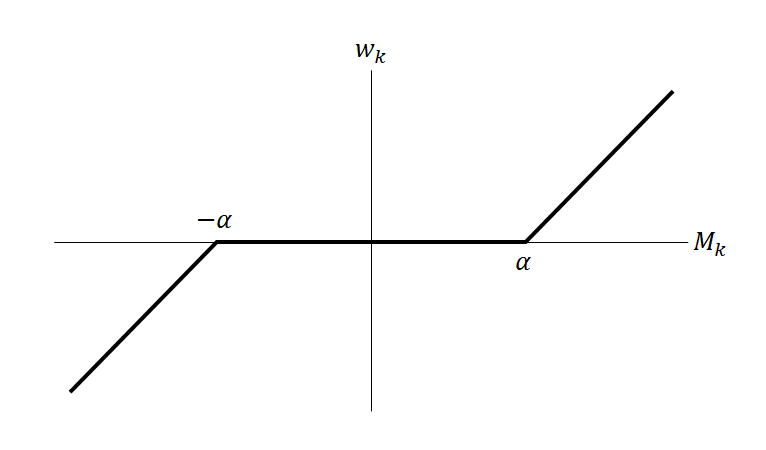



 の形になるが、不等式の両辺をaで割ることで、このような表現とすることは差し支えない。
の形になるが、不等式の両辺をaで割ることで、このような表現とすることは差し支えない。





 と置いて最適化問題を解く。
と置いて最適化問題を解く。
 を満足する。この停留点が極値だということが分かっていれば、これが問題の解ということになる。
を満足する。この停留点が極値だということが分かっていれば、これが問題の解ということになる。

 として問題を解いてみる。
として問題を解いてみる。
 の条件でLagrangeの未定乗数法によって解く。
の条件でLagrangeの未定乗数法によって解く。
 として、
として、
 を満たしており、このうち最小値となる解と目的関数の値は以下の通り。
を満たしており、このうち最小値となる解と目的関数の値は以下の通り。
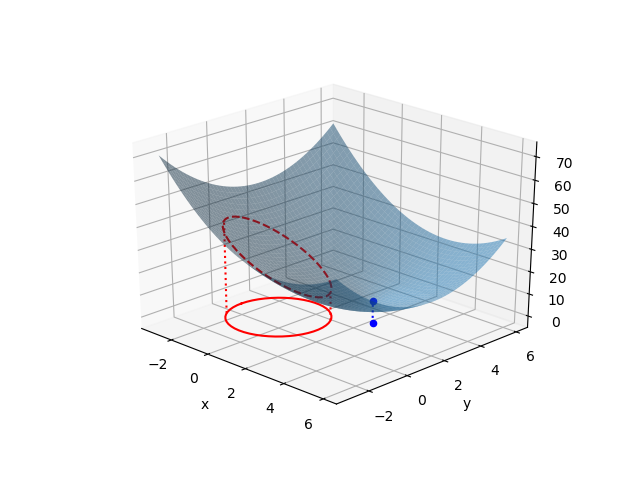

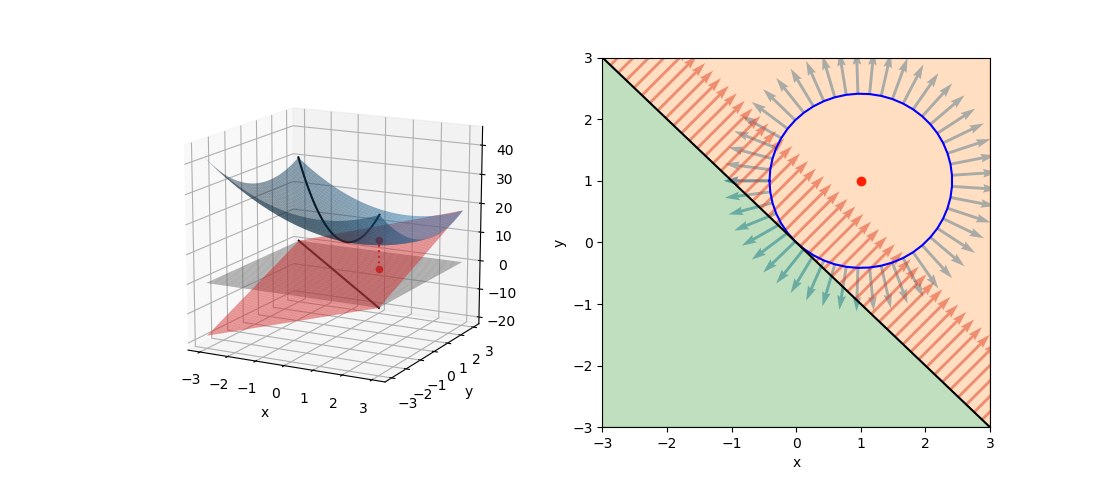


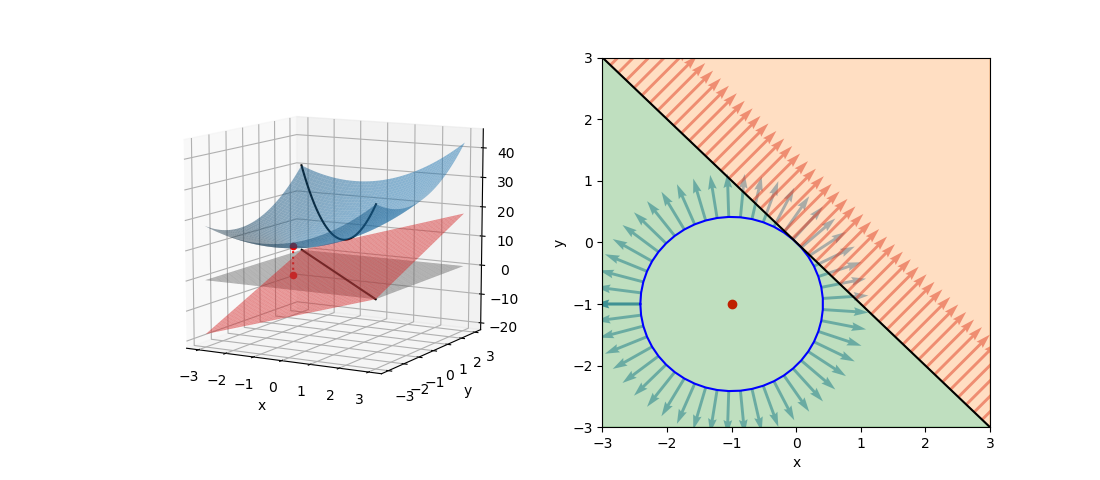


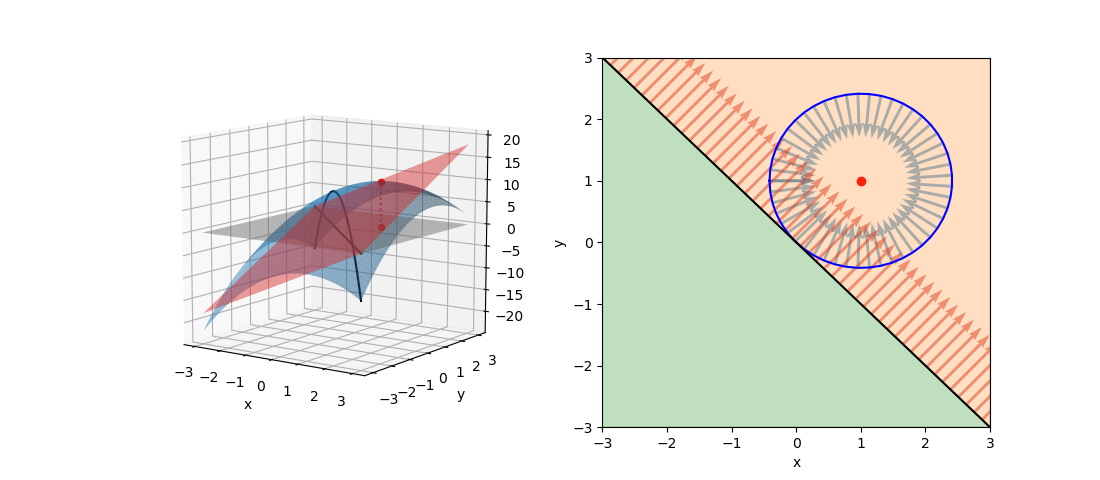















![\begin{equation*} \left[ \begin{array}{cccc} n & S_1 & \cdots & S_m \\ S_1 & S_{11} + \alpha & & S_{1m} \\ \vdots & \vdots & & \vdots \\ S_m & S_{m1} & \cdots & S_{mm} + \alpha \end{array} \right] \left[ \begin{array}{c} w_0 \\ w_1 \\ \vdots \\ w_m \end{array} \right] = \left[ \begin{array}{c} S_y \\S_{1y} \\ \vdots \\ S_{my} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-7e7bba69bc36153a376daa558ddbf28a_l3.png "Rendered by QuickLaTeX.com")
 を消去して、以下の連立方程式を得る。
を消去して、以下の連立方程式を得る。![\begin{align*} &\left[ \begin{array}{ccc} ( S_{11} + \alpha ) - \dfrac{{S_1}^2}{n} & \cdots & S_{1m} - \dfrac{S_1 S_m}{n} \\ \vdots & & \vdots \\ S_{m1} - \dfrac{S_m S_1}{n} & \cdots & ( S_{mm} + \alpha )- \dfrac{{S_2}^2}{n} \end{array} \right] \left[ \begin{array}{c} w_1 \\ \vdots \\ w_m \end{array} \right] \\&= \left[ \begin{array}{c} S_{1y} - \dfrac{S_1 S_y}{n} \\ \vdots \\ S_{my} - \dfrac{S_m S_y}{n} \end{array} \right] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-17a68647af45d80bac08fd44b3135e4c_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \left[ \begin{array}{ccc} V_{11} + \dfrac{\alpha}{n} & \cdots & V_{1m} \\ \vdots & & \vdots \\ V_{m1} & \cdots & V_{mm} + \dfrac{\alpha}{n} \end{array} \right] \left[ \begin{array}{c} w_1 \\ \vdots \\ w_m \end{array} \right] = \left[ \begin{array}{c} V_{1y} \\ \vdots \\ V_{my} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-3a7696ac06d6f37063cc1e74c39f4bab_l3.png "Rendered by QuickLaTeX.com")
 とすると、
とすると、
![\begin{align*} \left[ \begin{array}{ccccccc} V_{11} + \dfrac{\alpha}{n} & \cdots & V_{1i} & \cdots & aV_{1i} & \cdots & V_{1m}\\ \vdots && \vdots && \vdots && \vdots\\ V_{i1} & \cdots & V_{ii} + \dfrac{\alpha}{n} & \cdots & aV_{ii} & \cdots & V_{im}\\ \vdots && \vdots && \vdots && \vdots\\ aV_{i1} & \cdots & aV_{ii} & \cdots & a^2V_{ii} + \dfrac{\alpha}{n} & \cdots & aV_{im}\\ \vdots && \vdots && \vdots && \vdots\\ V_{m1} & \cdots & V_{mi} & \cdots & aV_{mi} & \cdots & V_{mm} + \dfrac{\alpha}{n} \end{array} \right] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-6eff526fb57f5dc6657a032f7dc7da8d_l3.png "Rendered by QuickLaTeX.com")












