概要
勾配ブースティング(gradient boosthing)は、ランダムフォレストと同じく複数の決定木を組み合わせてモデルを強化する手法。ランダムフォレストと異なる点は、最初から複数の決定木を使うのではなく、1つずつ順番に決定木を増やしていく。その際に追加される決定木はそれぞれ深さ1~5くらいの浅い木(弱学習機:weak learner)で、直前の適合不足を補うように学習する。
勾配ブースティングの主なパラメーターは弱学習機の数(n_estimators)と学習率(learning_rate)で、学習率を大きくすると個々の弱学習機の補正を強化しモデルは複雑になる。
cancerデータへの適用
Pythonのscikit-learnにあるGradienBoostingClassifierをbreast_cancerデータに適用する例。”Pythonではじめる機械学習”の”2.3.6.2 勾配ブースティング回帰木”掲載のコードに沿って確認するが、バージョンの違いのためか、結果が異なる。いくつかのデフォルトのパラメーターを明示的に設定/変更してみたが、書籍に掲載されている結果には至っていない。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.ensemble import GradientBoostingClassifier ds = load_breast_cancer() X_train, X_test, y_train, y_test =\ train_test_split(ds.data, ds.target, random_state=0) gbcf = GradientBoostingClassifier(random_state=1) gbcf.fit(X_train, y_train) print("Training score: {:.3f}".format(gbcf.score(X_train, y_train))) print("Test score : {:.3f}".format(gbcf.score(X_test, y_test))) gbcf = GradientBoostingClassifier(max_depth=1, random_state=0) gbcf.fit(X_train, y_train) print("Training score: {:.3f}".format(gbcf.score(X_train, y_train))) print("Test score : {:.3f}".format(gbcf.score(X_test, y_test))) fig, ax = plt.subplots(figsize=(8, 4.8)) fig.subplots_adjust(left=0.3) ax.barh(ds.feature_names, gbcf.feature_importances_) ax.set_xlabel("feature importance") plt.show() gbcf = GradientBoostingClassifier(learning_rate=0.01, random_state=0) gbcf.fit(X_train, y_train) print("Training score: {:.3f}".format(gbcf.score(X_train, y_train))) print("Test score : {:.3f}".format(gbcf.score(X_test, y_test))) |
最初に試したのが以下のコード。ここでテストスコアが書籍にある0.958にならない。min_samples_split=5とすると書籍と同じ結果になるが、以降の特徴量重要度やlearning_rateの変更結果は再現されない。
|
1 2 3 4 5 6 7 |
gbcf = GradientBoostingClassifier(random_state=0) gbcf.fit(X_train, y_train) print("Training score: {:.3f}".format(gbcf.score(X_train, y_train))) print("Test score : {:.3f}".format(gbcf.score(X_test, y_test))) # Training score: 1.000 # Test score : 0.965 |
過剰適合に対してmax_depth=1と強力な枝刈りをした場合。この結果は小数点以下3桁の表示で書籍と一致している。
|
1 2 3 4 5 6 7 |
gbcf = GradientBoostingClassifier(max_depth=1, random_state=0) gbcf.fit(X_train, y_train) print("Training score: {:.3f}".format(gbcf.score(X_train, y_train))) print("Test score : {:.3f}".format(gbcf.score(X_test, y_test))) # Training score: 0.991 # Test score : 0.972 |
learning_rateをデフォルトの0.1から0.01に変更した場合の結果も書籍と一致する。今回の再現結果では、デフォルト状態からテストスコアは改善されていない。
|
1 2 3 4 5 6 7 |
gbcf = GradientBoostingClassifier(learning_rate=0.01, random_state=0) gbcf.fit(X_train, y_train) print("Training score: {:.3f}".format(gbcf.score(X_train, y_train))) print("Test score : {:.3f}".format(gbcf.score(X_test, y_test))) # Training score: 0.988 # Test score : 0.965 |
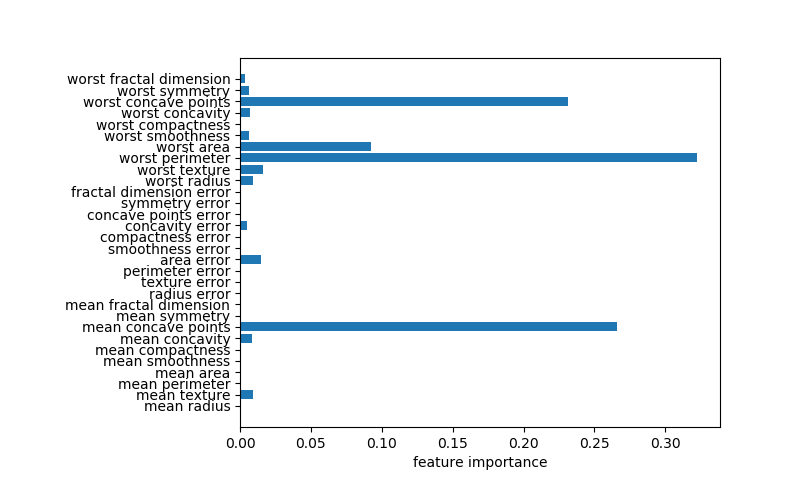
なお、事前剪定を強化したケースのグラフが、書籍と大きく異なる。横軸の値が倍ほどになっており、worst concave points、worst perimeter、mean concave pointsが重要度の大半を占めている。書籍では他の多くの特徴量も重要度がある程度高い点と異なっている。
|
1 2 3 4 5 6 7 8 |
gbcf = GradientBoostingClassifier(max_depth=1, random_state=0) gbcf.fit(X_train, y_train) fig, ax = plt.subplots(figsize=(8, 4.8)) fig.subplots_adjust(left=0.3) ax.barh(ds.feature_names, gbcf.feature_importances_) ax.set_xlabel("feature importance") plt.show() |
今後確認したい点
- 勾配ブースティングの基本的な考え方の整理
- 簡単な事例での勾配ブースティングの挙動確認
- 回帰への適用
- 異なるモデルの組み合わせ