SVMの定式化
SVMのクラス分類の条件
2つの特徴量を持つデータが2つのクラスに分かれているとする。ここで下図のように、1つの直線によって、2つのクラスを完全に分離できるとする。
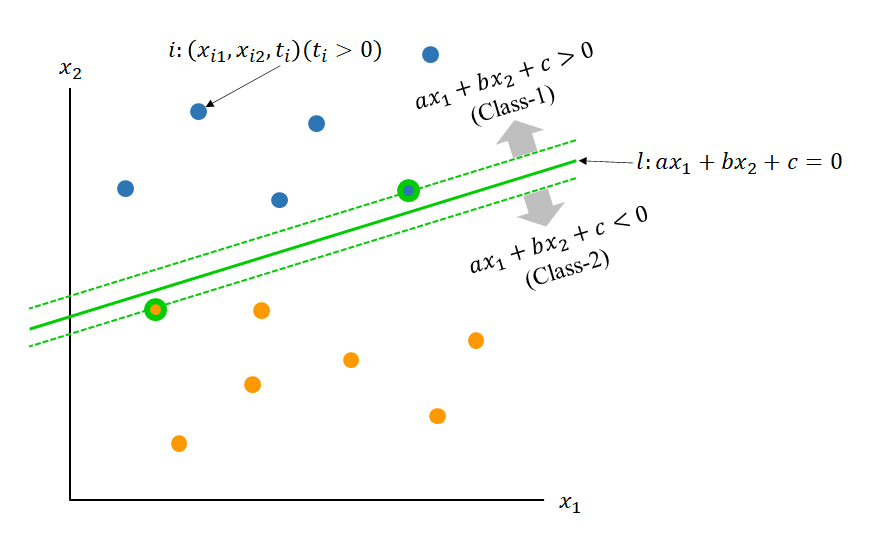
このとき、直線lによって分割したとして、以下の符号によってクラスを分離する。
(1) 
ここでラベル変数tiを導入する。tiはデータiがClass1/2のいずれに属するかを示す変数で、Class1ならti > 0、Class2ならti < 0と定義する。
(2) 
このラベル変数を用いて、クラスの条件式は以下のように統一される。
(3) 
SVMにおいては、すべてのデータについてこの式が満足されるようにa, b, cを決定する。これらはすべてa, b, cに対する制約条件だが、どのようにこれらの値を求めるべきか、その目的関数が必要になる。SVMでは、これをマージン最大化により行う。
マージン最大化
ある直線l1によって、下図のようにデータセットがClass1/2に分類できるとする。このときl1に対してClass1/2の最も直線に近いデータを”サポートベクター”と呼ぶ。また、これらのサポートベクターに対応するl1と平行な直線間の距離を”マージン”と呼ぶ。
ところで、l1とは異なる別の直線l2を選ぶと、異なるサポートベクターに対してより大きなマージンを得ることができる。SVMでは、式(3)のもとでこのマージンを最大化するような直線lを探すこととなる。
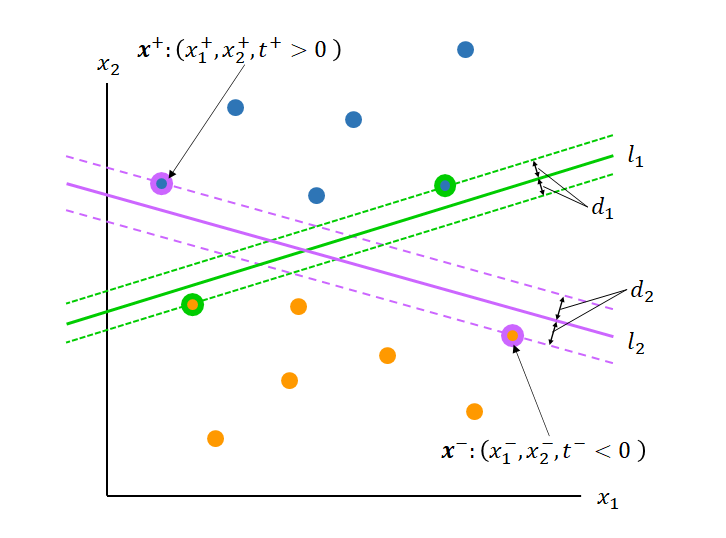
直線lに対するサポートベクターの対を(x+, x−)とすると、それぞれからlへの距離dは以下のように表現される。
(4) 
ここで直線lはマージンの端にある平行な2つの直線の中央にあることから、上式の分子は同じ値となる。この値でdを除したものを改めて と置くと、dの最大化問題は
と置くと、dの最大化問題は の最小化問題となる。これに式(3)の制約条件を加味して、問題は以下の制約条件付き最小化問題となる。
の最小化問題となる。これに式(3)の制約条件を加味して、問題は以下の制約条件付き最小化問題となる。
(5) 
今後の課題
- ここから先の定式化
- ソフトマージンの導出