準備
長方形の面積最大化
たとえば2変数の問題として、長方形の周囲長 を一定として、その面積が最大となる長方形の形状と面積はどのようになるかを考える。この場合、長方形の辺の長さを
を一定として、その面積が最大となる長方形の形状と面積はどのようになるかを考える。この場合、長方形の辺の長さを とすると、問題は以下のように表せる。
とすると、問題は以下のように表せる。
(1) 
これは以下のように代数的に簡単に解けて、答えは正方形とわかる。
(2) 
ただし変数の数が増えたり、目的関数や制約条件が複雑になると、解析的に解くのが面倒になる。
Lgrangeの未定乗数法による解
解法から先に示す。Lagrangeの未定乗数法では、目的関数 に対して以下の問題となる。
に対して以下の問題となる。
(3) 
 を最大化するために、
を最大化するために、 で偏微分した以下の方程式を設定する。
で偏微分した以下の方程式を設定する。
(4) 
これを計算すると
(5) 
Lagrangeの未定乗数法の一般形
一般には、変数 について、目的関数
について、目的関数 を制約条件
を制約条件 の下で最大化/最小化する問題として与えられる。
の下で最大化/最小化する問題として与えられる。
(6) 
この等式制約条件付き最大化/最小化問題は、以下のように を導入して、連立方程式として表現される。
を導入して、連立方程式として表現される。
(7) 
例題
例題1:平面と円
平面 について、制約条件
について、制約条件 の下での極値を求める。
の下での極値を求める。
(8) 
lagrangeの未定乗数を導入して問題を定式化すると以下のようになる。
(9) 
(10) 
この連立方程式を解くと以下のようになり、解として2つの極値を得るが、それらは最大値と最小値に相当する。
(11) 
これを目的関数のコンターと制約条件の線で表すと以下の通り。
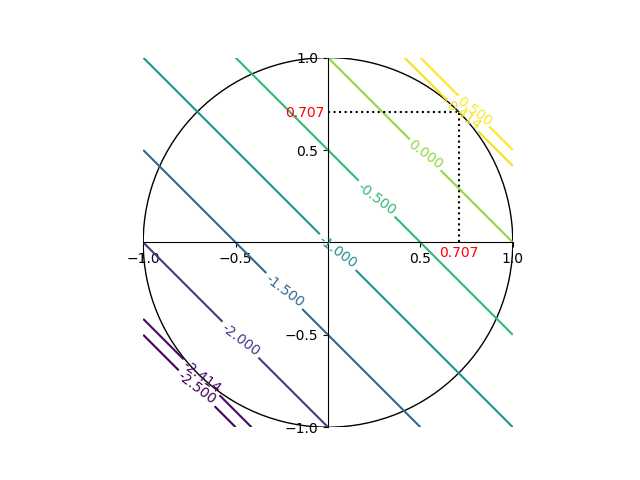
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as patches x = np.linspace(-1, 1, 20) y = np.linspace(-1, 1, 20) x, y = np.meshgrid(x, y) z = x + y - 1 fig = plt.figure() ax = fig.add_subplot(111) cntr = ax.contour(x, y, z ,levels=[-2.5, -2.414, -2, -1.5, -1, -0.5, 0, 0.414, 0.5]) ax.clabel(cntr) crc = patches.Circle(xy=(0, 0), radius=1, fill=False) ax.add_patch(crc) s2 = 1 / np.sqrt(2) ax.plot((0, s2), (s2, s2), c='k', linestyle='dotted') ax.plot((s2, s2), (0, s2), c='k', linestyle='dotted') ax.set_xlim((-1, 1)) ax.set_ylim((-1, 1)) ax.set_xticks([-1, -0.5, 0.5, 1]) ax.set_yticks([-1, -0.5, 0.5, 1]) ax.spines['bottom'].set_position('zero') ax.spines['left'].set_position('zero') ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) ax.text(0.6, -0.08, "0.707", c='r') ax.text(-0.23, 0.68, "0.707", c='r') ax.set_aspect('equal') plt.show() |
例題2:凸関数と直線
下に凸な関数について、直線 の制約条件下での最小値を求める。
の制約条件下での最小値を求める。
(12) 
ここでlagrangeの未定乗数を導入して問題を定式化すると以下のようになる。
(13) 
(14) 
この連立方程式を解くと以下のようになり、解は最小値1つとなる。
(15) 
これを目的関数のコンターと制約条件の線で表すと以下の通り。
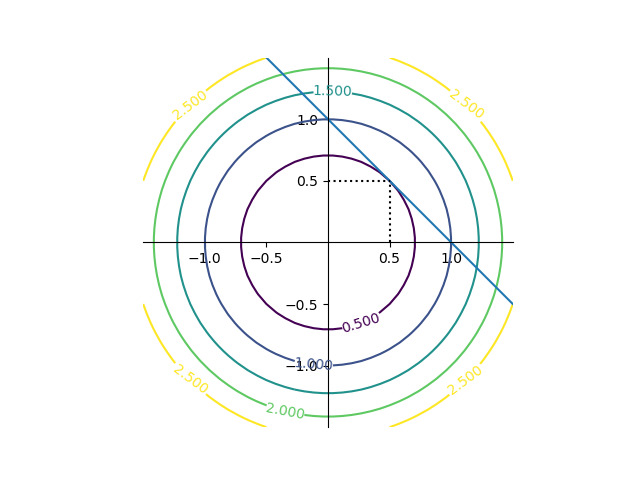
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import numpy as np import matplotlib.pyplot as plt x = np.linspace(-1.5, 1.5, 40) y = np.linspace(-1.5, 1.5, 40) x, y = np.meshgrid(x, y) z = x * x + y * y fig = plt.figure() ax = fig.add_subplot(111) cntr = ax.contour(x, y, z, levels=[0.5, 1, 1.5, 2, 2.5]) ax.clabel(cntr) ax.plot([-0.5, 1.5], [1.5, -0.5]) ax.plot((0, .5), (.5, .5), c='k', linestyle='dotted') ax.plot((.5, .5), (0, .5), c='k', linestyle='dotted') ax.set_xticks([-1, -0.5, 0.5, 1]) ax.set_yticks([-1, -0.5, 0.5, 1]) ax.spines['bottom'].set_position('zero') ax.spines['left'].set_position('zero') ax.spines['right'].set_visible(False) ax.spines['top'].set_visible(False) ax.set_aspect('equal') plt.show() |
なお、これを3次元で表示すると以下のようになる。青い曲面が目的関数で、赤い直線が制約条件となる。最適化問題は、制約条件を満たす曲面上の点(図中、赤い放物線)の最小値を求めることになる。
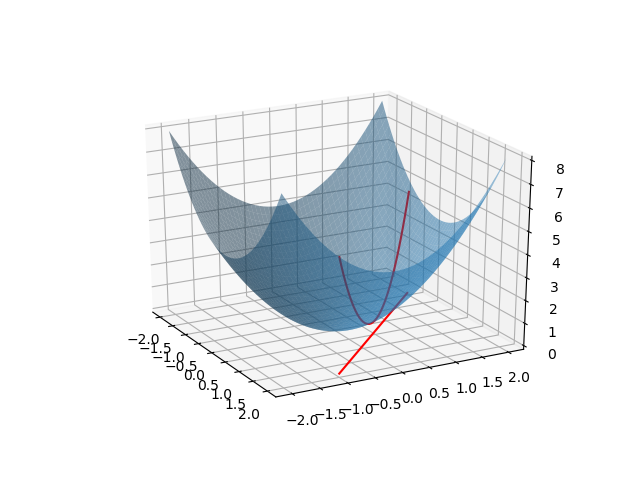
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D xmin, xmax = -2, 2 ymin, ymax = -2, 2 x = np.linspace(xmin, xmax) y = np.linspace(ymin, ymax) x_paraboloid, y_paraboloid = np.meshgrid(x, y) z_paraboloid = x_paraboloid**2 + y_paraboloid**2 x_constraint = x.copy() y_constraint = 1 - x z_constraint = x_constraint**2 + y_constraint**2 for i, v in enumerate(y_constraint): if v <= ymin or v >= ymax: x_constraint[i] = np.nan y_constraint[i] = np.nan z_constraint[i] = np.nan fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.plot_surface(x_paraboloid, y_paraboloid, z_paraboloid, alpha=0.5) ax.plot(x_constraint, y_constraint, z_constraint, color='r') ax.plot(x_constraint, y_constraint, 0, color='r') plt.show() |
幾何学的説明
式(7)は以下のように書ける。
(16) ![\begin{gather*} \left[ \begin{array}{c} \dfrac{\partial f}{\partial x_1} \\ \vdots \\ \dfrac{\partial f}{\partial x_n} \end{array} \right] = \lambda \left[ \begin{array}{c} \dfrac{\partial g}{\partial x_1} \\ \vdots \\ \dfrac{\partial g}{\partial x_n} \end{array} \right] \\ g(x_1, \ldots, x_n) = 0 \end{gather*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-c297beeeabd64856118393aad789fe1a_l3.png "Rendered by QuickLaTeX.com")
さらにgradientで表すと
(17) 
すなわちこの式の解 は、制約条件である
は、制約条件である を満足し、その曲線上にある。さらに解の点において
を満足し、その曲線上にある。さらに解の点において の勾配ベクトルとゼロ平面上における
の勾配ベクトルとゼロ平面上における の勾配ベクトルが平行になる。これはゼロ平面上の解の点において制約条件の曲線とのコンターのうち特定の曲線が接するのと同義であり、この点は停留点(stationary point)である。
の勾配ベクトルが平行になる。これはゼロ平面上の解の点において制約条件の曲線とのコンターのうち特定の曲線が接するのと同義であり、この点は停留点(stationary point)である。
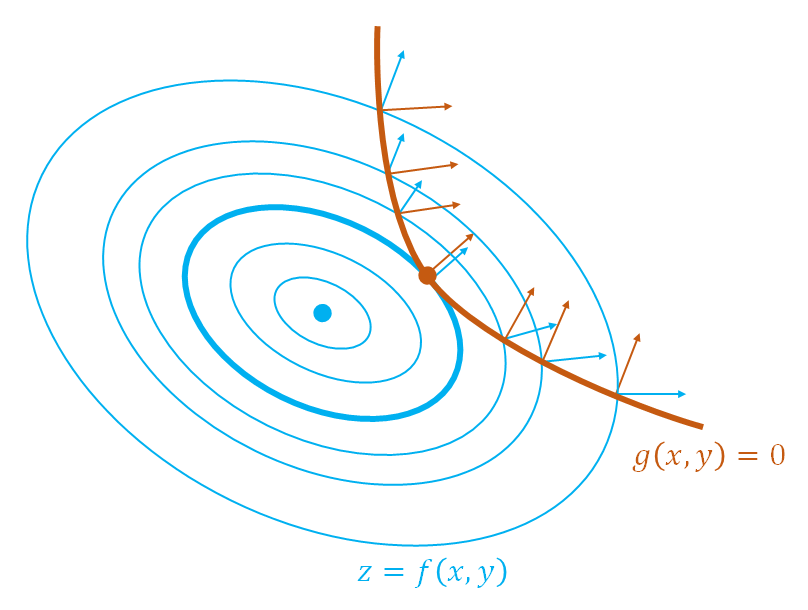
つまりこのような停留点を発見する手順は、制約条件を満たす(制約条件の線上にある)点のうち、その点において目的関数のgradientと制約条件の関数のgradientが平行となる点を求めるということになる。再度これを式で表すと、
(18) 
となるが、これをLangrange関数 と定義したうえで各変数で偏微分したものをゼロと置いた方程式を解くと表現している。未定乗数λは停留点における目的関数のgradientと制約条件の関数のgradientの比を表している。
と定義したうえで各変数で偏微分したものをゼロと置いた方程式を解くと表現している。未定乗数λは停留点における目的関数のgradientと制約条件の関数のgradientの比を表している。
λの符号
λの符号に意味があるかどうか。
たとえば、以下の制約条件付き最適化問題を考える。
(19) 
(20) 
この問題の制約条件を変更して以下のようにした場合。
(21) 
(22) 
このように、制約条件の正負を反転するとλの符号が逆になるが解は変わらない。これを表したのが以下の図。
等式制約条件の場合、制約条件の線上でgradientが平行になりさえすればよいので、λ符号(制約条件式の正負)には拘らなくてよい。
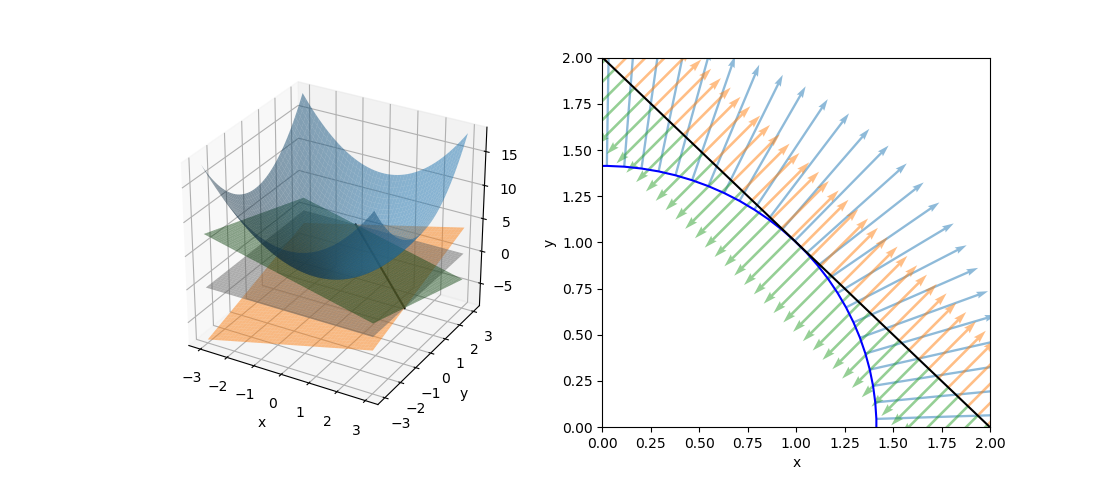
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as patch from mpl_toolkits.mplot3d import Axes3D xmin, xmax = -3, 3 ymin, ymax = -3, 3 xls, xle = -1, 3 yls, yle = 3, -1 xs = np.linspace(xmin, xmax) ys = np.linspace(ymin, ymax) xm, ym = np.meshgrid(xs, ys) zero_plain = np.full_like(xm, 0) z_prb = xm**2 + ym**2 z_pl1 = xm + ym - 2 z_pl2 = - xm - ym + 2 r = np.sqrt(2) t = np.linspace(-np.pi, np.pi, num=100) xc = r * np.cos(t) yc = r * np.sin(t) uqc = 2 * xc vqc = 2 * yc xql = np.linspace(xls, xle, num=80) yql = np.linspace(yls, yle, num=80) uql1 = np.full_like(xql, 1) vql1 = np.full_like(yql, 1) uql2 = np.full_like(xql, -1) vql2 = np.full_like(yql, -1) fig = plt.figure(figsize=(11, 4.8)) ax1 = fig.add_subplot(121, projection='3d') ax2 = fig.add_subplot(122) ax1.plot_surface(xm, ym, zero_plain, color='gray', alpha=0.5) ax1.plot_surface(xm, ym, z_prb, color='tab:blue', alpha=0.5) ax1.plot_surface(xm, ym, z_pl1, color='tab:orange', alpha=0.5) ax1.plot_surface(xm, ym, z_pl2, color='tab:green', alpha=0.5) ax1.plot([xls, yls], [xle, yle], [0, 0], c='k') ax1.set_xlabel("x") ax1.set_ylabel("y") ax2.plot(xc, yc, c='b') ax2.plot([xls, yls], [xle, yle], c='k') ax2.quiver(xc, yc, uqc, vqc, scale_units='xy', scale=4, color='tab:blue', alpha=0.5) ax2.quiver(xql, yql, uql1, vql1, scale_units='xy', scale=4, color='tab:orange', alpha=0.5) ax2.quiver(xql, yql, uql2, vql2, scale_units='xy', scale=4, color='tab:green', alpha=0.5) ax2.set_xlabel("x") ax2.set_ylabel("y") ax2.set_xlim(0, 2) ax2.set_ylim(0, 2) plt.show() |
停留点が極致とならない例
以下の最適化問題の解をみてみる。
(23) 
(24) 
第1式から第2式を引き、第3式を適用して、
(25) 
ここで の曲面と制約条件
の曲面と制約条件 に対する曲面上の軌跡を描くと下図左のようになる。下図の右は
に対する曲面上の軌跡を描くと下図左のようになる。下図の右は として曲線を表したもので、
として曲線を表したもので、 で勾配は水平になっており、停留点ではあるが極大/極小となっていない。
で勾配は水平になっており、停留点ではあるが極大/極小となっていない。
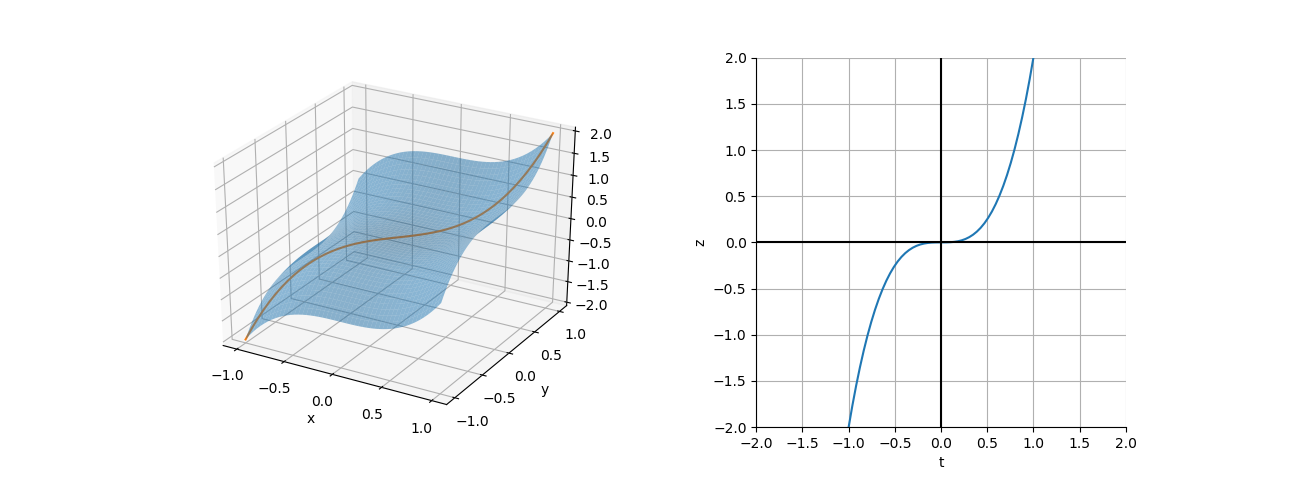
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D x = np.linspace(-1, 1) y = np.linspace(-1, 1) xs, ys = np.meshgrid(x, y) zs = xs**3 + ys**3 t = np.linspace(-1, 1) xp = yp = t zp = xp**3 + yp**3 fig = plt.figure(figsize=(13, 4.8)) ax1 = fig.add_subplot(121, projection='3d') ax2 = fig.add_subplot(122) ax1.plot_surface(xs, ys, zs, alpha=0.5) ax1.plot(xp, yp, zp) ax1.set_xlabel("x") ax1.set_ylabel("y") ax1.set_xticks(np.arange(-1, 1.5, 0.5)) ax1.set_yticks(np.arange(-1, 1.5, 0.5)) ax2.plot(t, zp) ax2.plot((-2, 2), (0, 0), c='k') ax2.plot((0, 0), (-2, 2), c='k') ax2.set_xlim(-2, 2) ax2.set_ylim(-2, 2) ax2.spines['top'].set_visible(False) ax2.spines['right'].set_visible(False) ax2.set_xlabel("t") ax2.set_ylabel("z") ax2.set_aspect('equal') ax2.grid(True) plt.show() |
参考サイト
本記事をまとめるにあたって、下記サイトが大変参考になったことに感謝したい。
![\begin{equation*} a_i \ge 0 \quad \Rightarrow \quad \sum_{i=1}^{n} a_i \ge n \sqrt[n]{\prod_{i=1}^{n} a_i} \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-7316e733b885728513bce2577cd689f4_l3.png "Rendered by QuickLaTeX.com")



 、点
、点 の距離を考える。直線と各点の記号、座標を以下のように定義する。
の距離を考える。直線と各点の記号、座標を以下のように定義する。
 が直線
が直線 は直線に平行なベクトル。
は直線に平行なベクトル。

 に対して上式が成り立つことから、
に対して上式が成り立つことから、 となり、ベクトル
となり、ベクトル から直線
から直線 とすると、
とすると、 なので、
なので、
 は直線
は直線


 との直行条件から、以下のようにも表現できる。
との直行条件から、以下のようにも表現できる。
 は平面に対する法線ベクトルであることがわかる。
は平面に対する法線ベクトルであることがわかる。 と平行であることから、
と平行であることから、

 から三次元平面
から三次元平面 への距離については、以下で表される。
への距離については、以下で表される。

 と上記の超平面との距離は以下で表される。
と上記の超平面との距離は以下で表される。
 の平均と分散は以下のようになる。
の平均と分散は以下のようになる。

 が乗じられていることから、以下の流れで変形している。
が乗じられていることから、以下の流れで変形している。 のとき1番目の項はゼロとなるので、和の開始値を
のとき1番目の項はゼロとなるので、和の開始値を とする
とする の分母において
の分母において とする
とする を
を と変形
と変形 と変形し、最終的に
と変形し、最終的に を引き出している。
を引き出している。 の指数も調整している
の指数も調整している とおくと、カウンターの範囲は
とおくと、カウンターの範囲は から
から となることから、
となることから、
 が各項に乗じられるが、これを
が各項に乗じられるが、これを と変形して、階乗のランクを下げるところがミソ。
と変形して、階乗のランクを下げるところがミソ。![\begin{alignat*}{1} V(X) &= E(X^2) - [E(X)]^2 \\ &= \sum_{k=0}^n k^2 {}_n C_k p^k (1-p)^{n-k} - (np)^2 \\ &= \sum_{k=0}^n \left( k(k-1) + k \right) {}_n C_k p^k (1-p)^{n-k} - (np)^2 \\ &= \sum_{k=2}^n k(k-1) {}_n C_k p^k (1-p)^{n-k} + \sum_{k=1}^n k {}_n C_k p^k (1-p)^{n-k} - (np)^2 \\ \end{alignat*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-443e6acf6b414d16761dcd5f2a012a8d_l3.png "Rendered by QuickLaTeX.com")
 が乗じられているのでカウンターを
が乗じられているのでカウンターを から、2項目は同じく
から、2項目は同じく と置いて、平均の時と同じ考え方で以下のように変形。
と置いて、平均の時と同じ考え方で以下のように変形。
 とおいて、
とおいて、

 の形に着目して、全事象の式を微分する方法。式展開が素直であり、平均の式を微分した結果がそのまま分散の式になってしまうところが美しい。
の形に着目して、全事象の式を微分する方法。式展開が素直であり、平均の式を微分した結果がそのまま分散の式になってしまうところが美しい。
 で微分する。
で微分する。
 をかける。
をかける。


 への線形関係を扱うのに対して、重回帰は複数の説明変数
への線形関係を扱うのに対して、重回帰は複数の説明変数 と
と の線形関係を扱う。
の線形関係を扱う。 に対して以下の線形式で最も説明性の高いものを求める。
に対して以下の線形式で最も説明性の高いものを求める。
 の平方和が最小となるような係数
の平方和が最小となるような係数 を最小二乗法により求める。
を最小二乗法により求める。 組が次のように得られているとする。
組が次のように得られているとする。



 ,
,  ,
,  ,
,  とおいて
とおいて












 は対象行列なので転置しても同じ行列となり、
は対象行列なので転置しても同じ行列となり、

 を消去する。
を消去する。
 、
、 と表している。
と表している。
 と2つの間に完全な線形関係がある場合、
と2つの間に完全な線形関係がある場合、
![\begin{align*} &\left[ \begin{array}{ccccccc} V_{11} & \cdots & V_{1i} & \cdots & V_{1j} & \cdots & V_{1m}\\ \vdots && \vdots && \vdots && \vdots\\ V_{i1} & \cdots & V_{ii} & \cdots & V_{ij} & \cdots & V_{im}\\ \vdots && \vdots && \vdots && \vdots\\ V_{j1} & \cdots & V_{ji} & \cdots & V_{jj} & \cdots & V_{jm}\\ \vdots && \vdots && \vdots && \vdots\\ V_{m1} & \cdots & V_{mi} & \cdots & V_{mj} & \cdots & V_{mm} \end{array} \right]\\ &= \left[ \begin{array}{ccccccc} V_{11} & \cdots & V_{1i} & \cdots & aV_{1i} & \cdots & V_{1m}\\ \vdots && \vdots && \vdots && \vdots\\ V_{i1} & \cdots & V_{ii} & \cdots & aV_{ii} & \cdots & V_{im}\\ \vdots && \vdots && \vdots && \vdots\\ aV_{i1} & \cdots & aV_{ii} & \cdots & a^2V_{ii} & \cdots & aV_{im}\\ \vdots && \vdots && \vdots && \vdots\\ V_{m1} & \cdots & V_{mi} & \cdots & aV_{mi} & \cdots & V_{mm} \end{array} \right] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-933b818b8ef3c6cf4b6a70d1805f71a8_l3.png "Rendered by QuickLaTeX.com")




 の固有値・固有ベクトルは以下で定義される。
の固有値・固有ベクトルは以下で定義される。





 に対しては、
に対しては、

 に対しては、
に対しては、



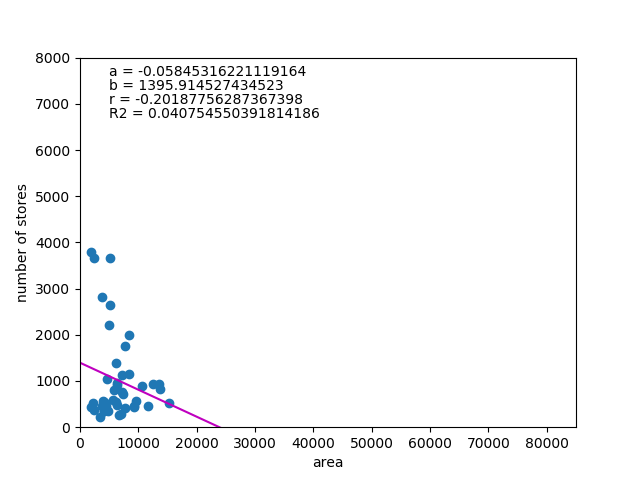
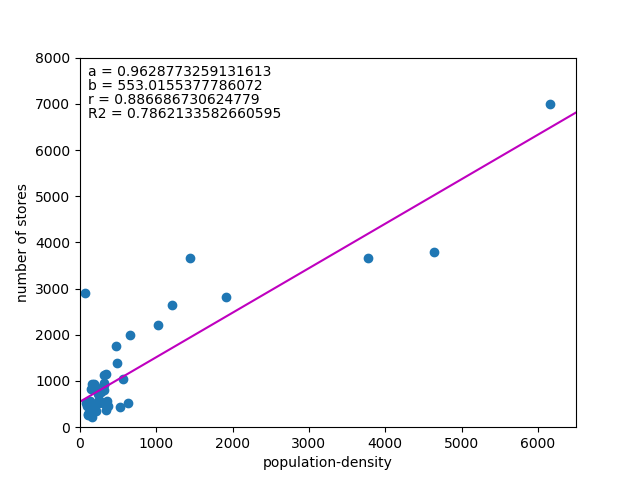
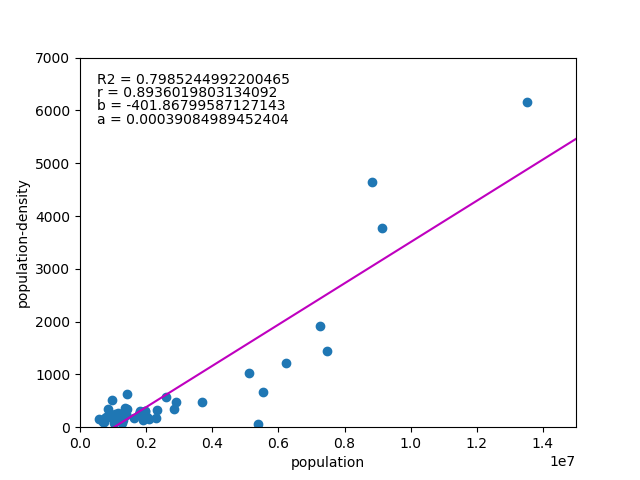
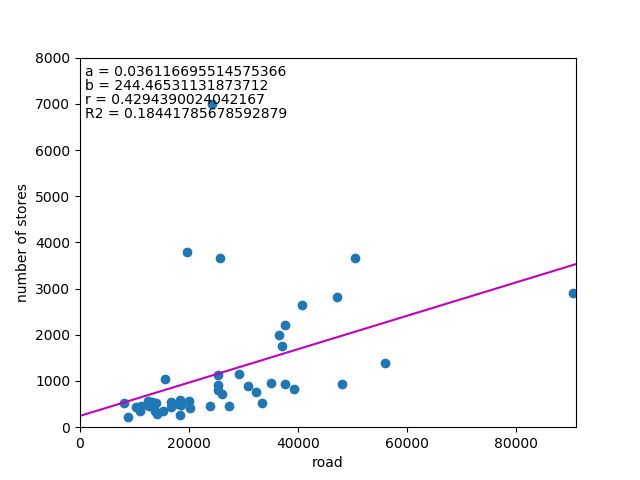
![\begin{eqnarray*} r &=& \frac{{\rm Cov}(X, Y)}{\sqrt{V(X) \cdot V(Y)}} \\ &=& \frac{E(X - \overline{X})(Y - \overline{Y})} {\sqrt{ ( E\left[ (X - \overline{X})^2 \right] E\left[ (Y - \overline{Y})^2 \right] }} \\ &=& \frac{\displaystyle \sum_{i=1}^{n}(x_i - \overline{x})(y_i - \overline{y})} {\left[ \displaystyle \sum_{i=1}^{n} (x_i - \overline{x})^2 \displaystyle \sum_{i=1}^{n} (y_i - \overline{y})^2 \right]^{1/2}} \end{eqnarray*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-b9969ab54d441dc3797aad03fd503747_l3.png "Rendered by QuickLaTeX.com")

![\begin{eqnarray*} r &=& \frac{ {\rm Cov}(X, aX+b) } { \left[ V(X) \cdot V(aX+b) \right]^{1/2} } \\ &=& \frac{ a {\rm Cov}(X, X) } { \left[ V(X) \cdot a^2 V(X) \right]^{1/2} } \\ &=& \frac{a}{\sqrt{a^2}} \cdot \frac{ {\rm Cov}(X, X) } { \left[ V(X) \cdot V(X) \right]^{1/2} } \\ &=& \frac{a}{|a|} \cdot \frac{ V(X) } { V(X) } \\ &=& 1 \; {\rm or} \; -1 \end{eqnarray*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-0d7ce9a0442d3932b94aab482cf5e5d2_l3.png "Rendered by QuickLaTeX.com")
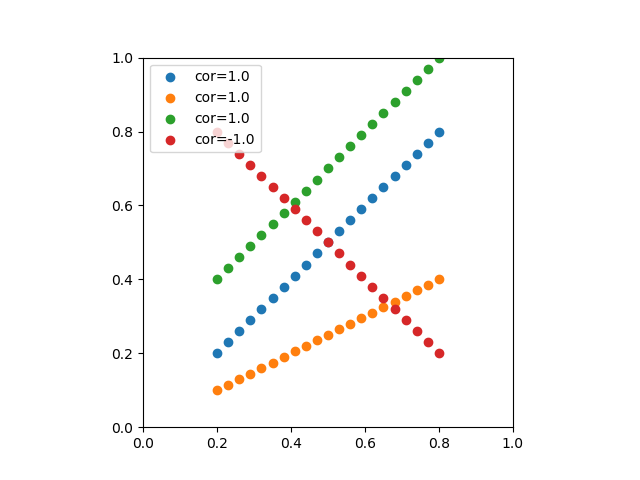
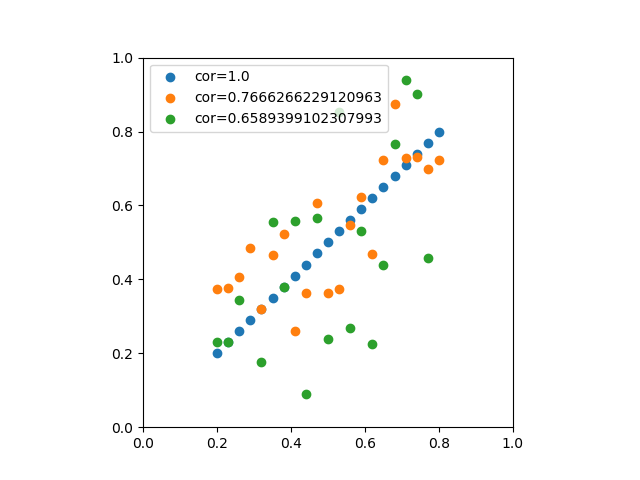
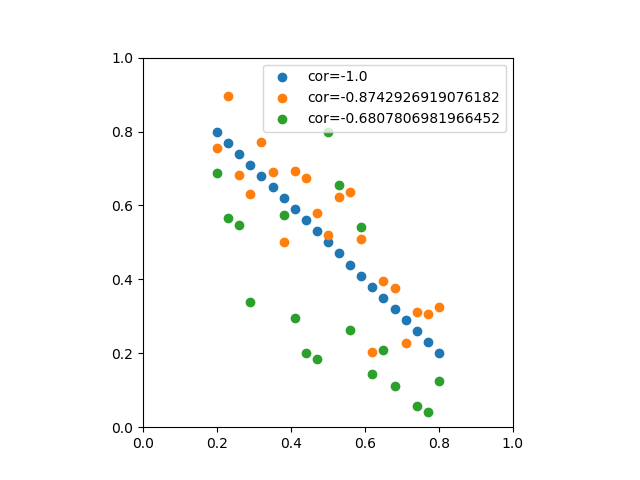
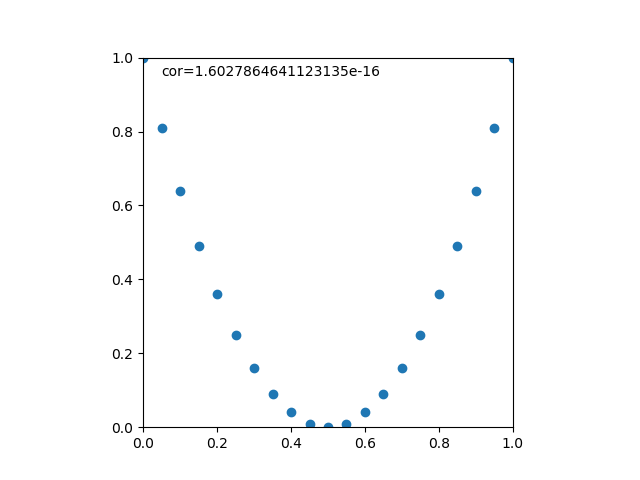
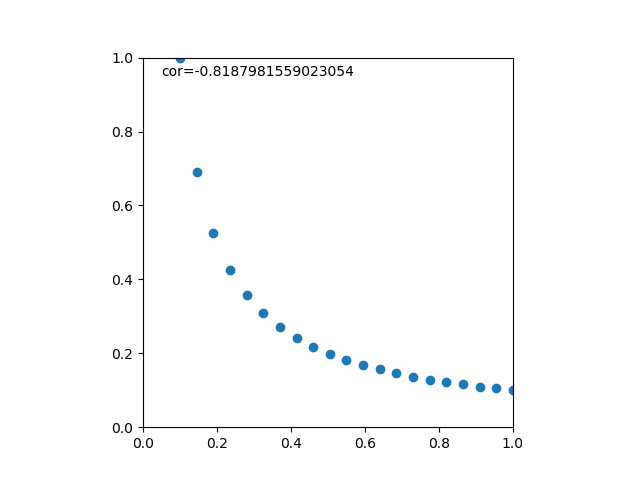
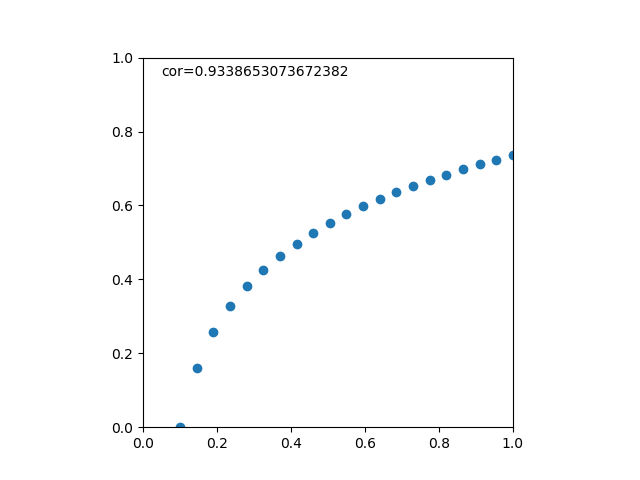
 のデータからなる複数の標本に対して、線形式で最も説明性の高いものを求める。
のデータからなる複数の標本に対して、線形式で最も説明性の高いものを求める。 に線形式を適用して得られた値
に線形式を適用して得られた値 と
と の差(残差)の平方和が最小となるような係数
の差(残差)の平方和が最小となるような係数 を求める(最小二乗法)。
を求める(最小二乗法)。


![\begin{equation*} \left[ \begin{array}{cc} S_{xx} & S_x \\ S_x & n \end{array} \right] \left[ \begin{array}{c} a \\ b \end{array} \right] = \left[ \begin{array}{c} S_{xy} \\ S_y \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-94c536b2251278801e9940f98a49312c_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \left[ \begin{array}{c} a \\ b \end{array} \right] = \left[ \begin{array}{c} \dfrac{n S_{xy} - S_x S_y}{n S_{xx} - {S_x}^2} \\ \dfrac{S_{xx} S_y - S_x S_{xy}}{n S_{xx} - {S_x}^2} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-5ab9943a0ccf9c81304d639401e154d8_l3.png "Rendered by QuickLaTeX.com")
 、
、


 で表す。
で表す。 によって、以下の変動が定義される。
によって、以下の変動が定義される。


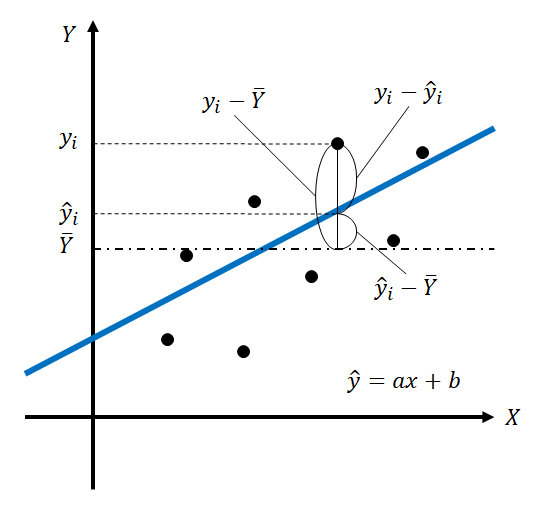







 を考慮して、
を考慮して、

 で表される。
で表される。
 すなわち全変動が回帰変動で全く説明できないときに0となる。
すなわち全変動が回帰変動で全く説明できないときに0となる。