一様乱数に基づく分析
R言語を使って、到着率をλ、観測時間をtとしてその間の到着時刻を一様乱数で発生させ、それらの分布や到着時間間隔、到着回数の分布などを確認する。
到着時刻の分布
以下の手順で到着時刻の乱数データを得てヒストグラムを描き、結果の一様性を確認する。
一様分布による到着確率の考え方の概要やその他の考え方についてはRによるポアソン過程のシミュレーションを参照。
- 観測時間tの間の平均到着数はλt
- ただしtの間で個数を指定して一様乱数を発生させると、全体の到着数を縛ることになる
- そこでtと同じ長さの余裕分をtの前後にとり、区間[–t, 2t)の間で3λt個の乱数を発生させる(到着時間の確率変数)
- そのデータから、区間[0, t)の範囲にあるデータを抽出し、ヒストグラムを描く
- その際、データの階級のレンジ~1レンジ幅の平均到着数も変化させてみる
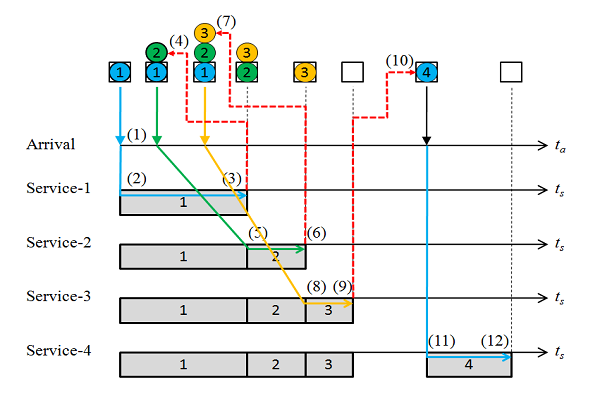
到着率λ = 1/10[回/秒]、観測時間5000[秒]、階級レンジ100秒としたときの、Rのコードは以下の通り。このとき各階級の平均的な到着回数は1/10 * 100 = 10回程度と予想される。
|
|
lambda <- 1 / 10 t.obs <- 5000 rank.width <- 100 num.data <- lambda * t.obs org.data <- (runif(floor(num.data * 3)) * 3 - 1) * t.obs data <- org.data[(org.data >= 0) & (org.data < t.obs)] ranks <- seq(0, t.obs, rank.width) hist(data, breaks=ranks) |
各変数の意味は、
lambda |
到着率λ |
t.obs |
観測時間t |
rank.width |
ヒストグラムの階級幅(時刻幅)。この幅の中の平均到着数はλ*rank_width回。 |
org.data |
前後に余裕幅を持たせた元データ |
data |
t.obsの範囲内だけを切り出したデータ |
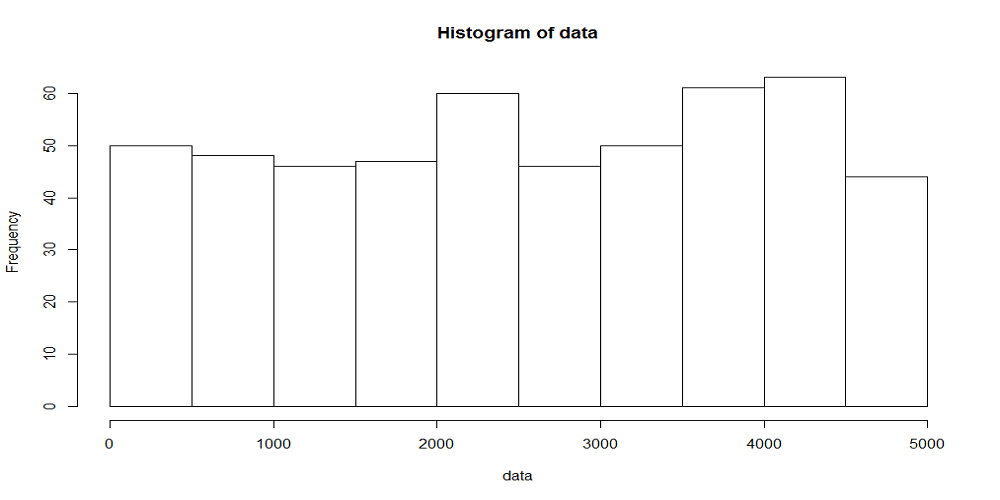
まず、rank.width = 100すなわち時刻幅あたりの平均到着数が10回の場合の分布をみてみる。
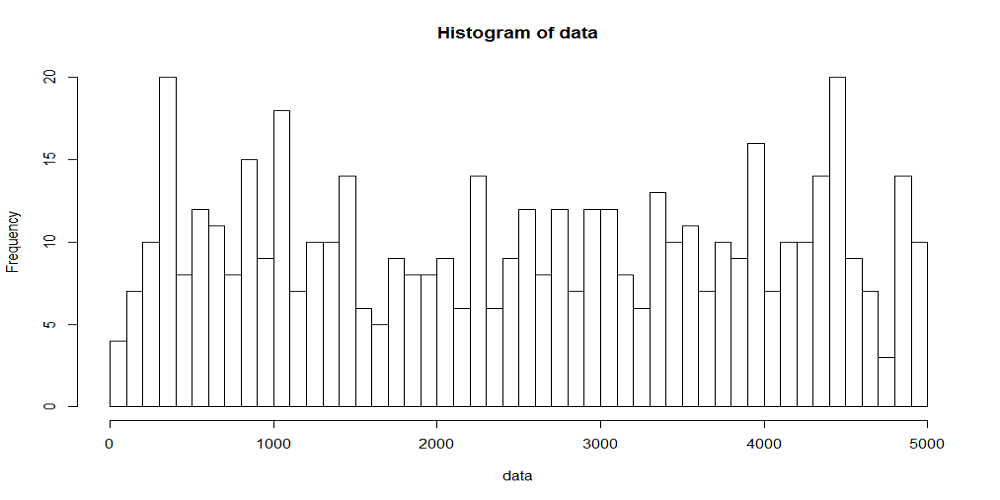
各時刻幅で到着数が変動していて、平均10回の到着が想定されるところに3~20回とばらついている。
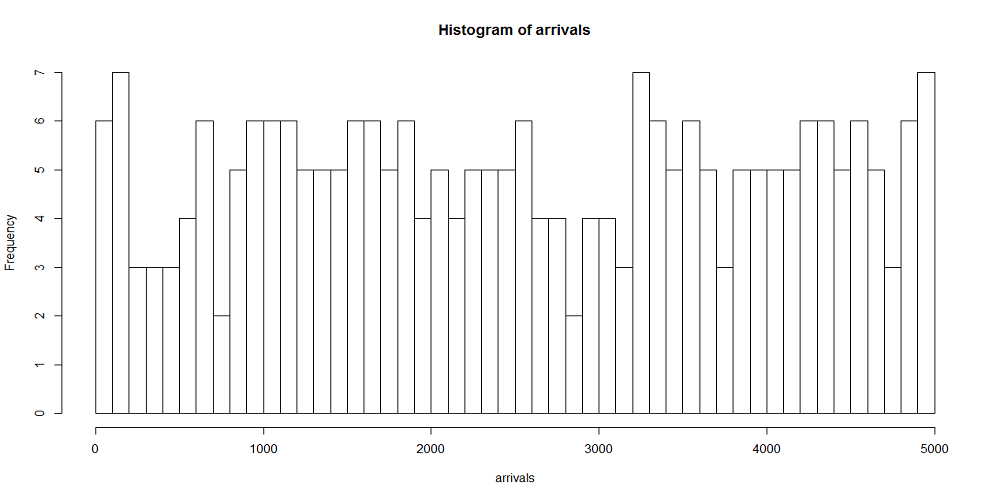
次にrank.width = 500すなわち時刻幅あたりの平均到着数が50回の場合の分布をみてみると、今度は随分と各時刻幅での到着回数が揃ってきているのが確認できる。
到着時間間隔の分布
到着時間間隔は、時系列上としてソートされた到着データてn番目の要素からn – 1番目の要素を引いて得られる。この計算は、到着データの先頭を除いたベクトルから最後尾のデータを除いたベクトルを引いて行っている。
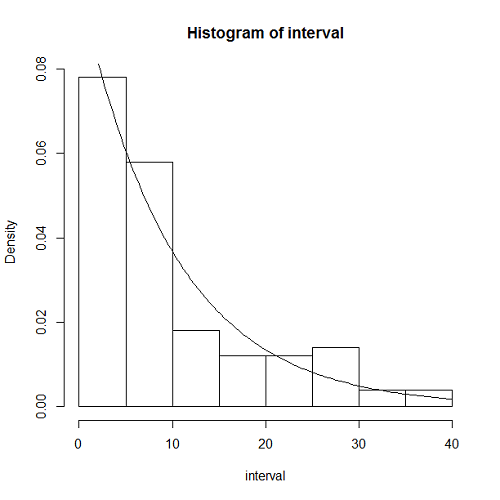
設定条件は到着率λ = 1/10[回/秒。観測時間は分布形には影響を与えず、データ数にのみ関係する。今回はt = 1000秒で、データ数はλt – 1 = 99個。
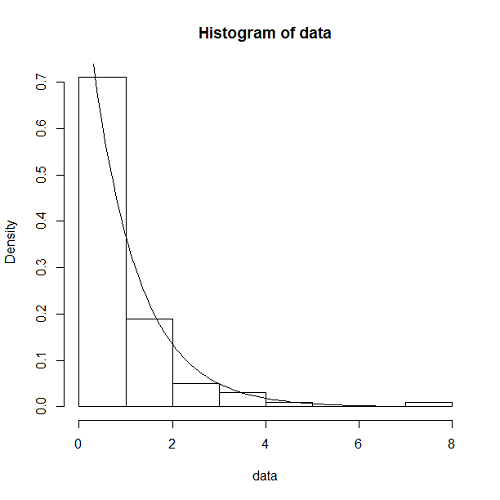
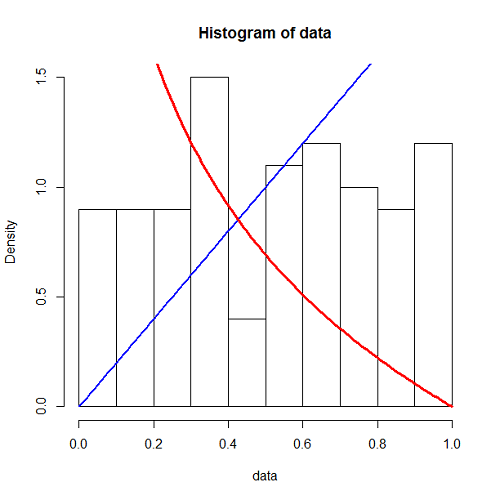
また、理論上の指数分布の密度関数の曲線をヒストグラムに重ね合わせている。
|
|
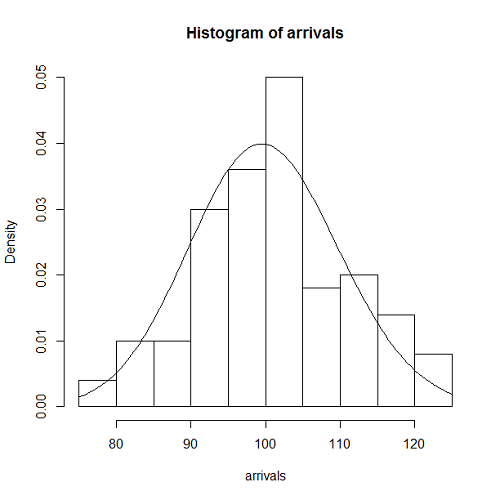
lambda <- 1 / 10 t.obs <- 1000 num.data <- lambda * t.obs org.data <- (runif(floor(num.data * 3)) * 3 - 1) * t.obs data <- sort(org.data[(org.data >= 0) & (org.data < t.obs)]) interval <- data[-1] - data[-length(data)] hist(interval, prob=TRUE, freq=FALSE) curve(dexp(x,rate=lambda), add=TRUE) |
この表示結果は以下のようになる。データ数は99だが、比較的よく指数分布の密度関数と整合している。
到着数の分布
以下の手順で観測時間tの間の到着数のデータを用意する。
- 必要回数分、以下を繰り返す
- 観測時間をtとして、区間[–t, 2t)で乱数を発生
- 0以上、t未満のデータを除いたデータを得てソート
- その個数を数える
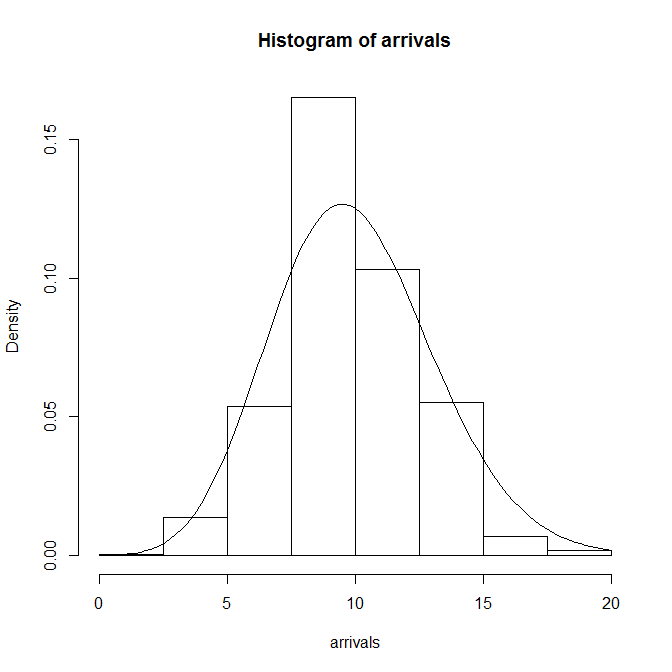
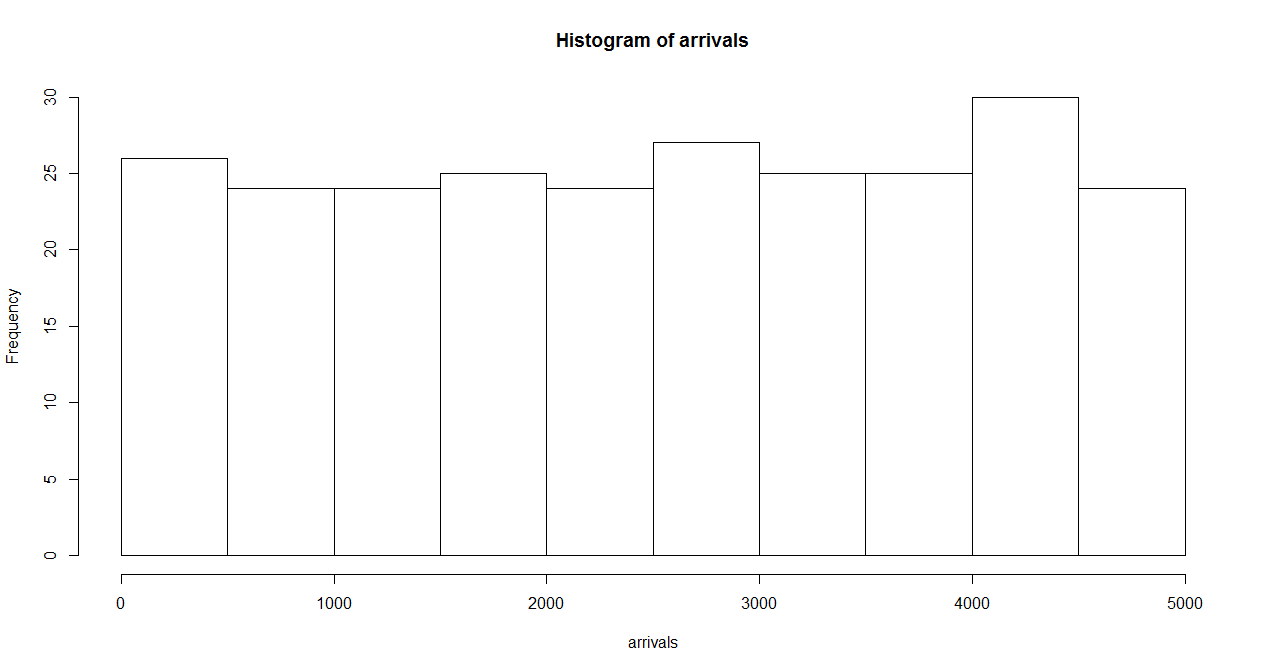
Rのコードは以下の通り。到着率はこれまでと同じ1/10、観測時間は100秒で、この観測時間内の期待到着数は10回だが、これがどの程度ばらつくかを確認するため、このデータを1000回発生させて、ヒストグラムを描かせている。
|
|
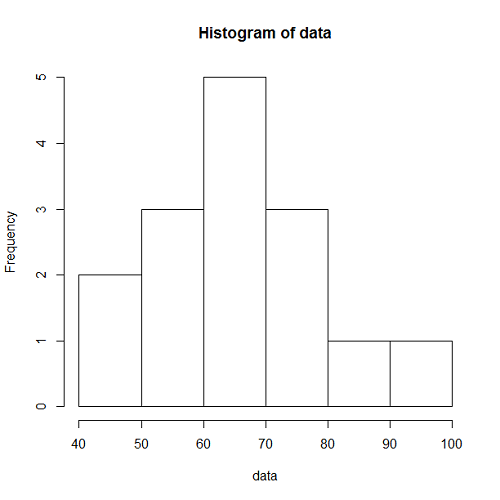
lambda <- 1 / 10 t.obs <- 100 num.data <- lambda * t.obs n.loop <- 1000 arrivals <- rep(0, num.data) for (i in 1:n.loop) { org.data <- (runif(floor(num.data * 3)) * 3 - 1) * t.obs data <- org.data[(org.data >= 0) & (org.data < t.obs)] arrivals[i] <- length(data) } hist(arrivals, prob=TRUE, xlim=c(0,20), breaks=seq(0,20,2.5)) |
到着率、観測時間が同じパラメータのPoisson分布もあわせて描いたのが以下のグラフ。
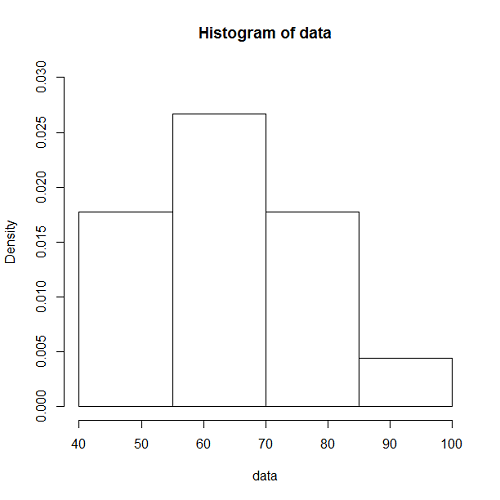
到着率を変えずに観測時間tを100→1000秒にした場合の分布は以下のようになる。
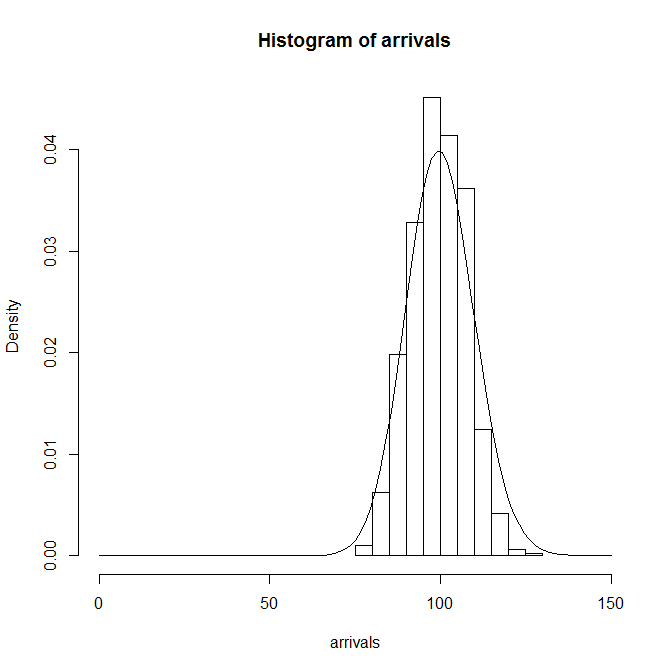
ここで縦軸に注意。頻度/確率のスケールが初めのものより小さくなっている。つまり、このグラフは最初のグラフに比べて、右の方へずれて、高さはぐっと低くなっている(この傾向はPoisson分布の傾向)。
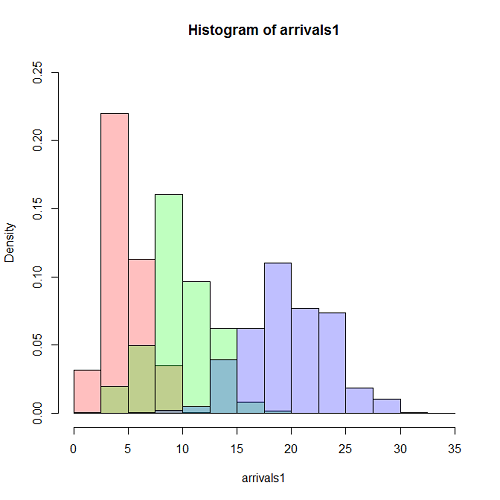
以下に、パラメータλtのtをj変化させたときのヒストグラムを重ね合わせてみる。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
generate <- function(dummy, lambda, t) { n <- lambda * t org.data <- (runif(floor(n * 3)) * 3 - 1) * t data <- org.data[(org.data >= 0) & (org.data < t)] return (length(data)) } lambda <- 1 / 10 t.obs <- 100 arrivals1 <- sapply(rep(0, 1000), generate, lambda, 50) arrivals2 <- sapply(rep(0, 1000), generate, lambda, 100) arrivals3 <- sapply(rep(0, 1000), generate, lambda, 200) xlm <- c(0, 35) ylm <- c(0, 0.25) brk <- seq(0, 35, 2.5) hist(arrivals1, prob=TRUE, col="#ff000040", xlim=xlm, ylim=ylm, breaks=brk) hist(arrivals2, prob=TRUE, col="#00ff0040", xlim=xlm, ylim=ylm, breaks=brk, add=TRUE) hist(arrivals3, prob=TRUE, col="#0000ff40", xlim=xlm, ylim=ylm, breaks=brk, add=TRUE) |
関連リンク
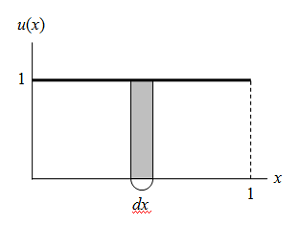
![\begin{equation*} \int_0^\infty u(x) dx = \int_0^\infty 1 dx = \left[ x \right]_0^\infty = 1 \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-03b0643bbf515230ca36a03c445086a5_l3.png "Rendered by QuickLaTeX.com")






















 の指数分布に従うような乱数を発生させていく。
の指数分布に従うような乱数を発生させていく。

 となる。この条件下で、以下のことを確認する。
となる。この条件下で、以下のことを確認する。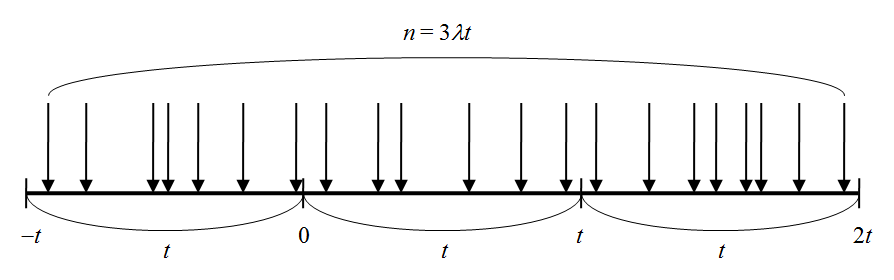
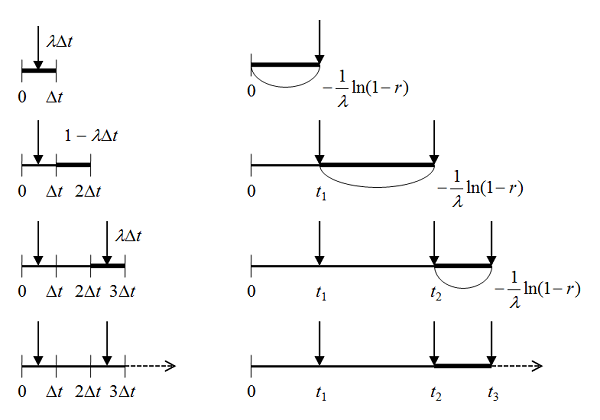
 が確率分布
が確率分布 に、確率変数
に、確率変数 が
が 上の一様分布に従うとする。このとき
上の一様分布に従うとする。このとき は確率分布
は確率分布 に従う。
に従う。



 とおくと、
とおくと、 だから、
だから、
 が確率分布
が確率分布 に従うことを意味している。
に従うことを意味している。
 に一様乱数列を入れることで、計算結果は指数分布に従う乱数列として得られる。
に一様乱数列を入れることで、計算結果は指数分布に従う乱数列として得られる。