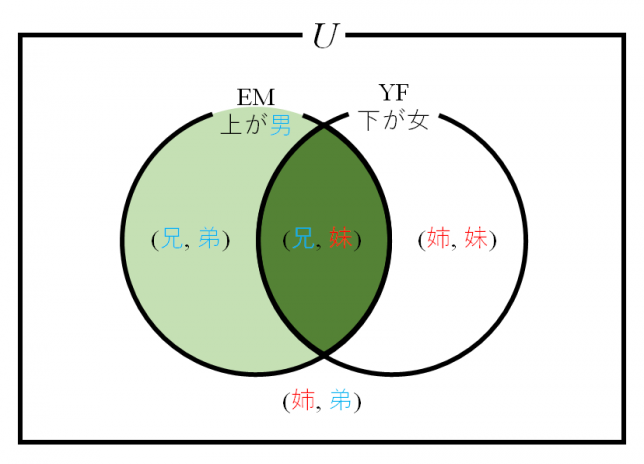
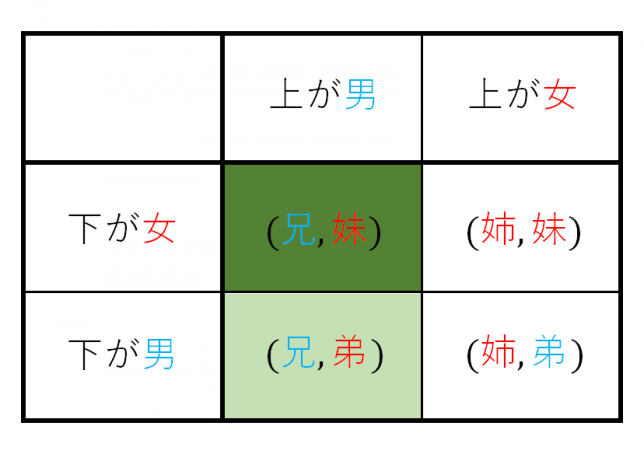
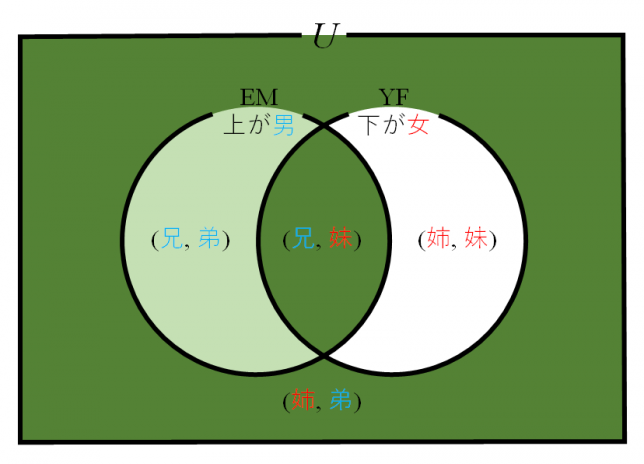
コインの例
最尤推定法(maximum likelihood estimation)は確率分布 のパラメーター
のパラメーター を、その母集団から得られたサンプルから推定する方法。
を、その母集団から得られたサンプルから推定する方法。
たとえば、表の出る確率が必ずしも1/2でないコインを50回投げた時、表が15回出たとすると、このコインの表が出る確率はいくらか、といった問題。20~30回くらいの間だと普通のコインで表/裏の確率は1/2かなと思うが、50回投げて表が15回しかでないとちょっと疑いたくなる。
ここで、表が出る確率を として、
として、 回の試行中表が
回の試行中表が 回出る確率は以下の通り。
回出る確率は以下の通り。
(1) 
先の問題の結果について、母集団の確率をいくつか仮定して計算してみると
(2) 
得られたサンプルの下では、少なくともぼ表が出る確率を1/2や1/4と考えるよりは、1/3と考えた方がこのサンプルのパターンが発生する確率が高い。
そこで、サンプルのパターンに対して母集団の確率を変化させてみると、以下のようになる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import numpy as np import matplotlib.pyplot as plt from scipy.stats import binom n = 50 k = 15 p = np.linspace(0, 1, 100) fig, ax = plt.subplots(figsize=(4.8, 3.6)) ax.plot(p, binom.pmf(k, n, p), c='navy') ax.plot((k/n, k/n), (0, binom.pmf(k, n, k/n)), c='gray', linestyle='dashed') ax.set_xlim(0, 1) ax.set_ylim(0, 0.15) ax.set_xticks(np.arange(0, 1.1, 0.1)) plt.show() |
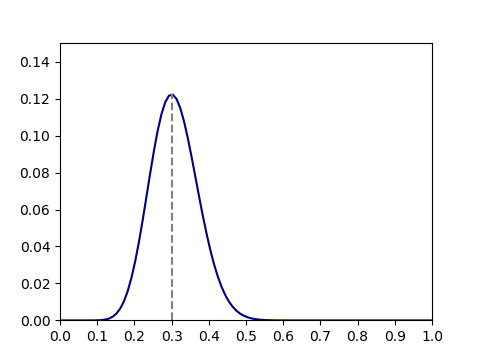
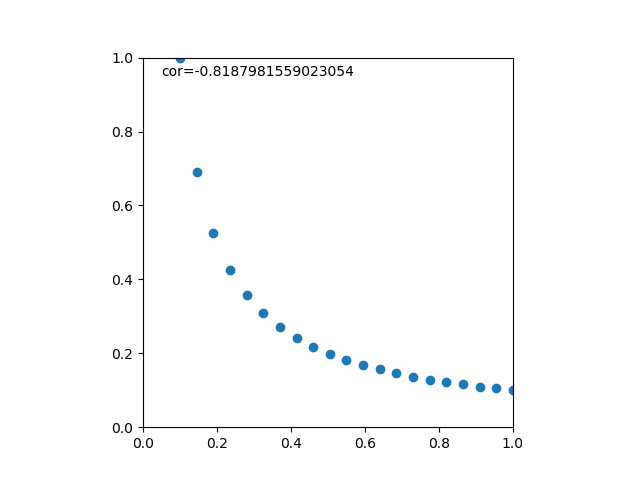
グラフ上は、母集団確率が15/50=0.3のときにサンプルパターンの発生確率が最も高くなっている。
解析的に確率が最大となる母集団確率を求めるために、式(1)をで微分してゼロとなる点を求める。
(3) 
上式の解は となるが、
となるが、 の場合は式(1)がゼロとなることから、確率が最大となるのは
の場合は式(1)がゼロとなることから、確率が最大となるのは であることがわかる。
であることがわかる。
尤度関数と最尤法
母集団の確率分布を 、母集団のパラメータを、得られたサンプルセットを
、母集団のパラメータを、得られたサンプルセットを とすると、パラメーターがである確率は
とすると、パラメーターがである確率は
(4) 
このとき、パラメーターに関する尤度関数は以下のように定義される。
(5) 
通常、尤度関数が最大となるパラメーターを求めるためには対数尤度関数が用いられる。
(6) 
サンプルの質と尤度
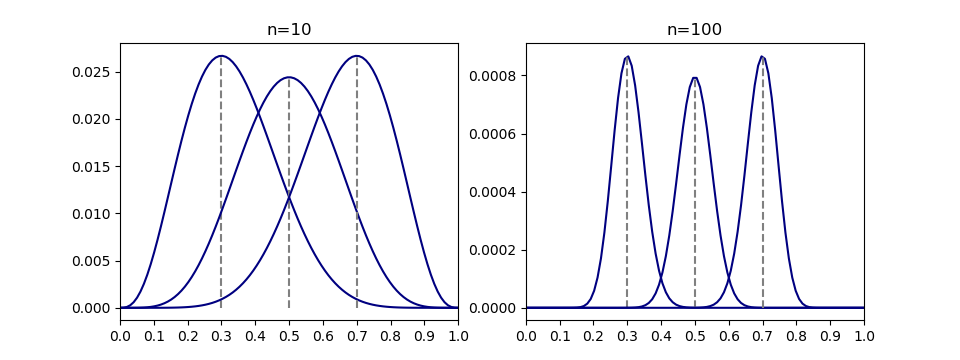
先のコインの問題で、試行数が10回の場合と100回の場合を比べてみる。それぞれについて、表の確率が0.3、0.5、0.7に対応する回数は試行回数が10回の場合は3回、5回、7回、試行回数100回に対しては30回、50回、70回である。それぞれの表の階数に対して、母集団確率の尤度関数を描くと以下のようになる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import numpy as np import matplotlib.pyplot as plt from functools import reduce def comb(n, k): numer = reduce(lambda x,y:x*y, range(n - k + 1, n)) denom = reduce(lambda x,y:x*y, range(1, k + 1)) return numer // denom def binom(n, k, p): return comb(n, k) * p**k * (1 - p)**(n - k) n = [10, 100] k = [np.array([3, 5, 7]), np.array([30, 50, 70])] p = np.linspace(0, 1, 100) fig, axs = plt.subplots(1, 2, figsize=(9.6, 3.6)) for ax, n, k in zip(axs, n, k): ax.set_title("n={}".format(n)) for t in k: p_mle = t / n prob = binom(n, t, p) ax.plot(p, prob, c='navy') ax.plot((p_mle, p_mle), (0, binom(n, t, p_mle)), c='gray', linestyle='dashed') ax.set_xlim(0, 1) ax.set_xticks(np.arange(0, 1.1, 0.1)) plt.show() |
試行回数が100回の場合には分布が尖っており、最尤推定されたパラメーターの確度が高いが、10回の場合には分布がなだらかで、最尤推定された値以外のパラメーターの確率も高くなっている。
最尤推定の場合、サンプルの規模が推定値の信頼度に関わってくる。
 の平均と分散は以下のようになる。
の平均と分散は以下のようになる。

 のとき1番目の項はゼロとなるので、和の開始値を
のとき1番目の項はゼロとなるので、和の開始値を とする
とする の分母において
の分母において とする
とする を
を と変形
と変形 と変形し、最終的に
と変形し、最終的に を引き出している。
を引き出している。 の指数も調整している
の指数も調整している とおくと、カウンターの範囲は
とおくと、カウンターの範囲は から
から となることから、
となることから、
 が各項に乗じられるが、これを
が各項に乗じられるが、これを と変形して、階乗のランクを下げるところがミソ。
と変形して、階乗のランクを下げるところがミソ。![\begin{alignat*}{1} V(X) &= E(X^2) - [E(X)]^2 \\ &= \sum_{k=0}^n k^2 {}_n C_k p^k (1-p)^{n-k} - (np)^2 \\ &= \sum_{k=0}^n \left( k(k-1) + k \right) {}_n C_k p^k (1-p)^{n-k} - (np)^2 \\ &= \sum_{k=2}^n k(k-1) {}_n C_k p^k (1-p)^{n-k} + \sum_{k=1}^n k {}_n C_k p^k (1-p)^{n-k} - (np)^2 \\ \end{alignat*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-443e6acf6b414d16761dcd5f2a012a8d_l3.png "Rendered by QuickLaTeX.com")
 が乗じられているのでカウンターを
が乗じられているのでカウンターを から、2項目は同じく
から、2項目は同じく と置いて、平均の時と同じ考え方で以下のように変形。
と置いて、平均の時と同じ考え方で以下のように変形。
 とおいて、
とおいて、

 の形に着目して、全事象の式を微分する方法。式展開が素直であり、平均の式を微分した結果がそのまま分散の式になってしまうところが美しい。
の形に着目して、全事象の式を微分する方法。式展開が素直であり、平均の式を微分した結果がそのまま分散の式になってしまうところが美しい。

 をかける。
をかける。


 への線形関係を扱うのに対して、重回帰は複数の説明変数
への線形関係を扱うのに対して、重回帰は複数の説明変数 と
と の線形関係を扱う。
の線形関係を扱う。 に対して以下の線形式で最も説明性の高いものを求める。
に対して以下の線形式で最も説明性の高いものを求める。
 の平方和が最小となるような係数
の平方和が最小となるような係数 を最小二乗法により求める。
を最小二乗法により求める。



 ,
,  ,
,  ,
,  とおいて
とおいて












 は対象行列なので転置しても同じ行列となり、
は対象行列なので転置しても同じ行列となり、

 を消去する。
を消去する。
 、
、 と表している。
と表している。
 と2つの間に完全な線形関係がある場合、
と2つの間に完全な線形関係がある場合、
![\begin{align*} &\left[ \begin{array}{ccccccc} V_{11} & \cdots & V_{1i} & \cdots & V_{1j} & \cdots & V_{1m}\\ \vdots && \vdots && \vdots && \vdots\\ V_{i1} & \cdots & V_{ii} & \cdots & V_{ij} & \cdots & V_{im}\\ \vdots && \vdots && \vdots && \vdots\\ V_{j1} & \cdots & V_{ji} & \cdots & V_{jj} & \cdots & V_{jm}\\ \vdots && \vdots && \vdots && \vdots\\ V_{m1} & \cdots & V_{mi} & \cdots & V_{mj} & \cdots & V_{mm} \end{array} \right]\\ &= \left[ \begin{array}{ccccccc} V_{11} & \cdots & V_{1i} & \cdots & aV_{1i} & \cdots & V_{1m}\\ \vdots && \vdots && \vdots && \vdots\\ V_{i1} & \cdots & V_{ii} & \cdots & aV_{ii} & \cdots & V_{im}\\ \vdots && \vdots && \vdots && \vdots\\ aV_{i1} & \cdots & aV_{ii} & \cdots & a^2V_{ii} & \cdots & aV_{im}\\ \vdots && \vdots && \vdots && \vdots\\ V_{m1} & \cdots & V_{mi} & \cdots & aV_{mi} & \cdots & V_{mm} \end{array} \right] \end{align*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-933b818b8ef3c6cf4b6a70d1805f71a8_l3.png "Rendered by QuickLaTeX.com")
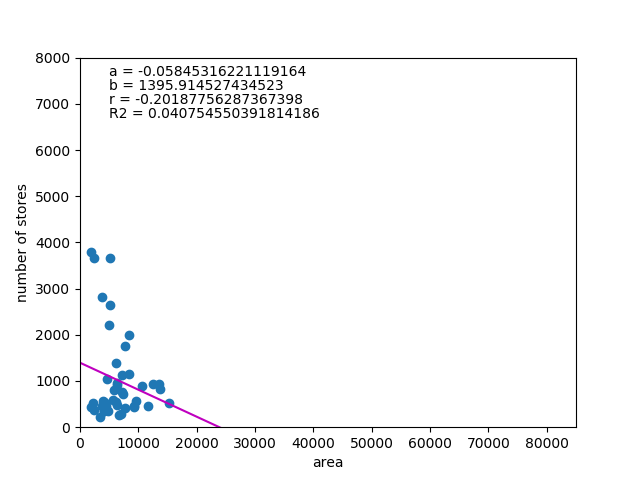
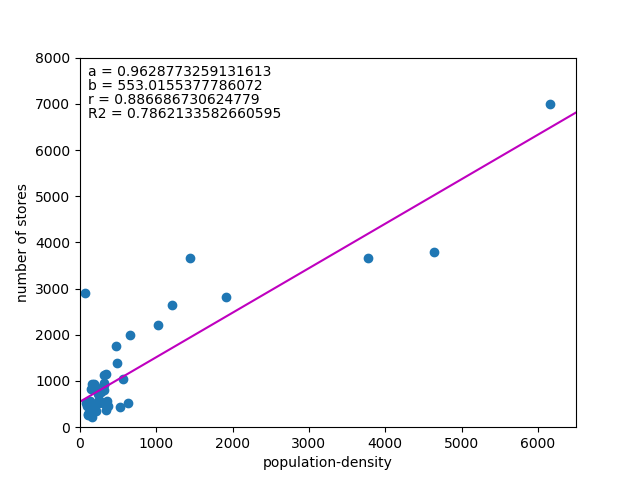
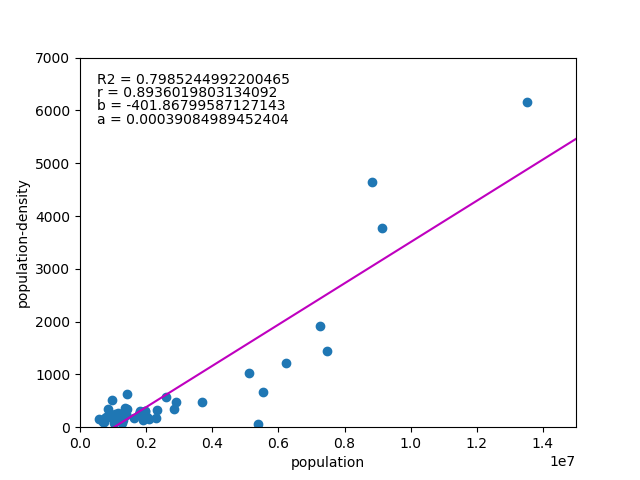
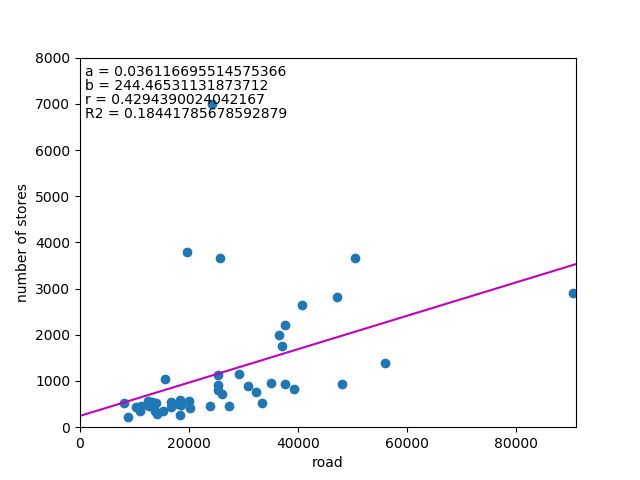
![\begin{eqnarray*} r &=& \frac{{\rm Cov}(X, Y)}{\sqrt{V(X) \cdot V(Y)}} \\ &=& \frac{E(X - \overline{X})(Y - \overline{Y})} {\sqrt{ ( E\left[ (X - \overline{X})^2 \right] E\left[ (Y - \overline{Y})^2 \right] }} \\ &=& \frac{\displaystyle \sum_{i=1}^{n}(x_i - \overline{x})(y_i - \overline{y})} {\left[ \displaystyle \sum_{i=1}^{n} (x_i - \overline{x})^2 \displaystyle \sum_{i=1}^{n} (y_i - \overline{y})^2 \right]^{1/2}} \end{eqnarray*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-b9969ab54d441dc3797aad03fd503747_l3.png "Rendered by QuickLaTeX.com")

![\begin{eqnarray*} r &=& \frac{ {\rm Cov}(X, aX+b) } { \left[ V(X) \cdot V(aX+b) \right]^{1/2} } \\ &=& \frac{ a {\rm Cov}(X, X) } { \left[ V(X) \cdot a^2 V(X) \right]^{1/2} } \\ &=& \frac{a}{\sqrt{a^2}} \cdot \frac{ {\rm Cov}(X, X) } { \left[ V(X) \cdot V(X) \right]^{1/2} } \\ &=& \frac{a}{|a|} \cdot \frac{ V(X) } { V(X) } \\ &=& 1 \; {\rm or} \; -1 \end{eqnarray*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-0d7ce9a0442d3932b94aab482cf5e5d2_l3.png "Rendered by QuickLaTeX.com")
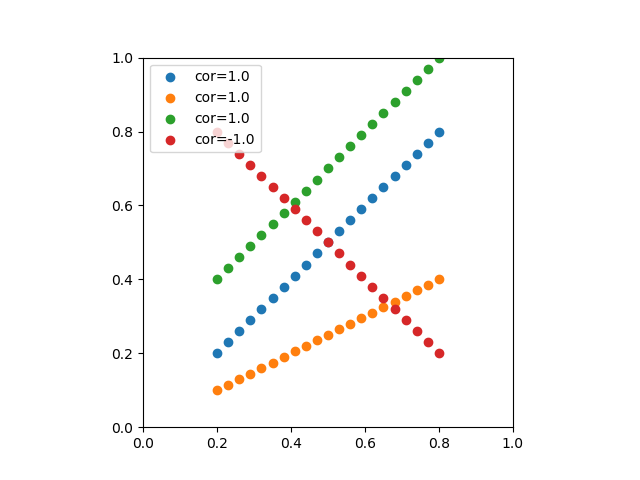
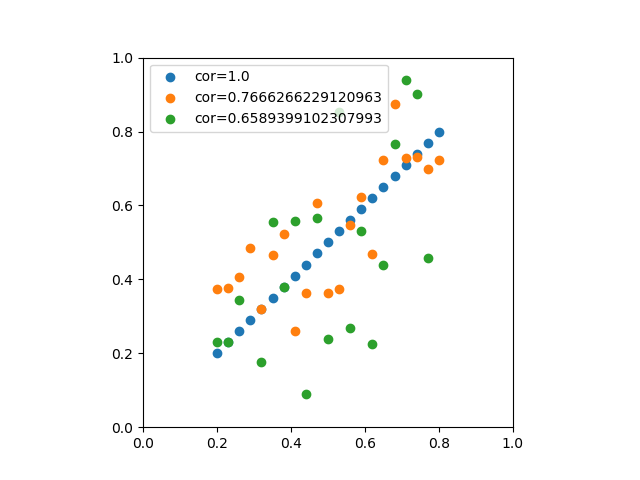
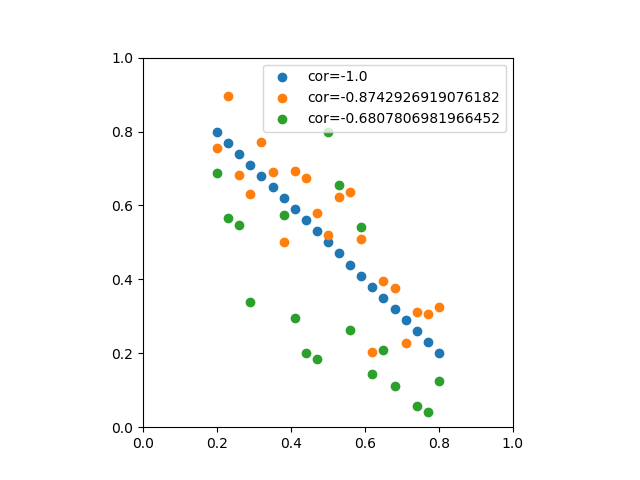
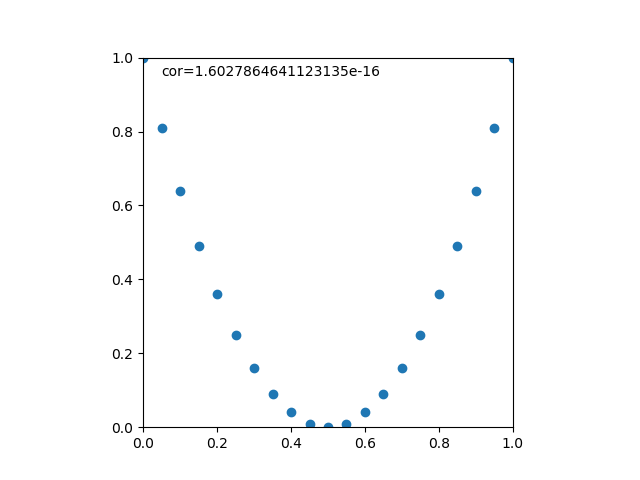
 のデータからなる複数の標本に対して、線形式で最も説明性の高いものを求める。
のデータからなる複数の標本に対して、線形式で最も説明性の高いものを求める。 に線形式を適用して得られた値
に線形式を適用して得られた値 と
と の差(残差)の平方和が最小となるような係数
の差(残差)の平方和が最小となるような係数 を求める(最小二乗法)。
を求める(最小二乗法)。


![\begin{equation*} \left[ \begin{array}{cc} S_{xx} & S_x \\ S_x & n \end{array} \right] \left[ \begin{array}{c} a \\ b \end{array} \right] = \left[ \begin{array}{c} S_{xy} \\ S_y \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-94c536b2251278801e9940f98a49312c_l3.png "Rendered by QuickLaTeX.com")
![\begin{equation*} \left[ \begin{array}{c} a \\ b \end{array} \right] = \left[ \begin{array}{c} \dfrac{n S_{xy} - S_x S_y}{n S_{xx} - {S_x}^2} \\ \dfrac{S_{xx} S_y - S_x S_{xy}}{n S_{xx} - {S_x}^2} \end{array} \right] \end{equation*}](http://taustation.com/wp1/wp-content/ql-cache/quicklatex.com-5ab9943a0ccf9c81304d639401e154d8_l3.png "Rendered by QuickLaTeX.com")
 、
、


 で表す。
で表す。 によって、以下の変動が定義される。
によって、以下の変動が定義される。


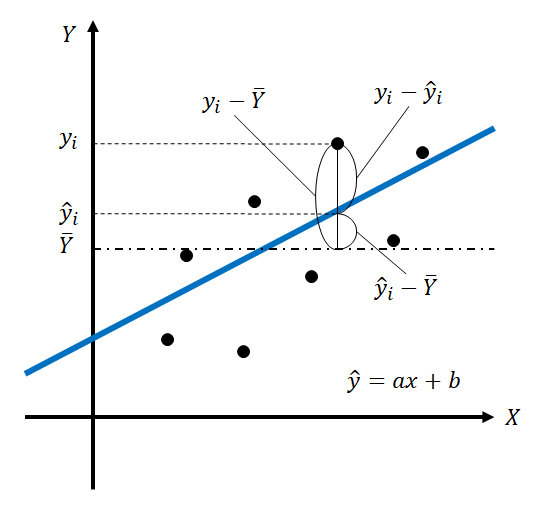







 を考慮して、
を考慮して、

 で表される。
で表される。
 すなわち全変動が回帰変動で全く説明できないときに0となる。
すなわち全変動が回帰変動で全く説明できないときに0となる。 とすると、
とすると、


 とすると、
とすると、 回は当たらないことを考慮して、
回は当たらないことを考慮して、
 とすると、これは各回の確率を累積していくことで求められるので、
とすると、これは各回の確率を累積していくことで求められるので、
 のとき1に近づくが、10回目で約83.8%、20回目で約97.4%、30回目で約99.6%、40回目で約99.9%となり、100回も打ってその時点で生き延びている確率はほとんどゼロに近い。
のとき1に近づくが、10回目で約83.8%、20回目で約97.4%、30回目で約99.6%、40回目で約99.9%となり、100回も打ってその時点で生き延びている確率はほとんどゼロに近い。 とすると、
とすると、
 とすると、
とすると、
 となり、
となり、


 としているが、この項の考え方は結局求めたい確率と同じ道筋で考えなければならない。
としているが、この項の考え方は結局求めたい確率と同じ道筋で考えなければならない。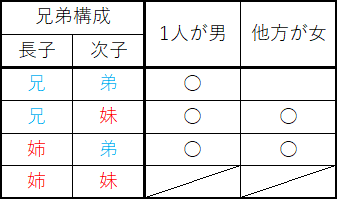






 に相当し、事前確率
に相当し、事前確率 の値が小さいほど4.5に近づく(
の値が小さいほど4.5に近づく(
 と
と の2事象の場合は、
の2事象の場合は、




 であることに留意して、これらの記号でベイズの定理を表すと以下の通り。
であることに留意して、これらの記号でベイズの定理を表すと以下の通り。
 とおくと、
とおくと、 となる。
となる。 がいくらかは関係ない。
がいくらかは関係ない。 」という条件を加える。
」という条件を加える。
 を考える。これは、陰性反応の時に難病にかかっていない確率に相当する。
を考える。これは、陰性反応の時に難病にかかっていない確率に相当する。

 の場合は
の場合は となる。
となる。 と置くと、
と置くと、 となる。
となる。 について解く。
について解く。
 のとき、
のとき、 となり、検査が意味を持つことがわかる。
となり、検査が意味を持つことがわかる。 がとても小さい場合を考える。たとえば難病の罹患率が1万人や10万人に1人といった場合。
がとても小さい場合を考える。たとえば難病の罹患率が1万人や10万人に1人といった場合。 とすると(
とすると(
 として、
として、